 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisturbance-Free Surgical Video Generation from Multi-Camera Shadowless Lamps for Open Surgery
Dec 09, 2025

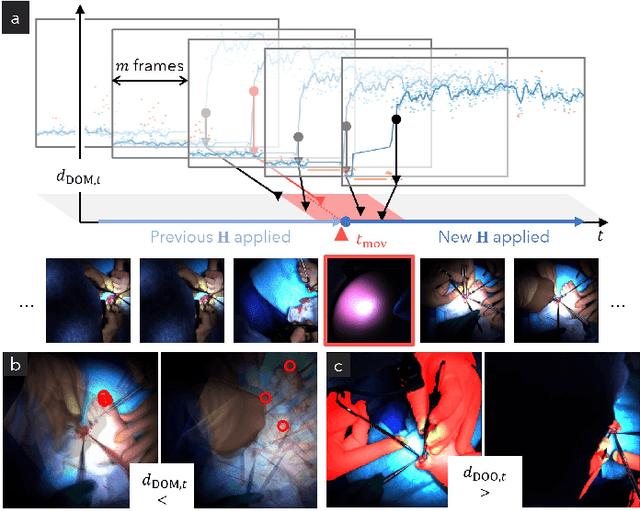

Video recordings of open surgeries are greatly required for education and research purposes. However, capturing unobstructed videos is challenging since surgeons frequently block the camera field of view. To avoid occlusion, the positions and angles of the camera must be frequently adjusted, which is highly labor-intensive. Prior work has addressed this issue by installing multiple cameras on a shadowless lamp and arranging them to fully surround the surgical area. This setup increases the chances of some cameras capturing an unobstructed view. However, manual image alignment is needed in post-processing since camera configurations change every time surgeons move the lamp for optimal lighting. This paper aims to fully automate this alignment task. The proposed method identifies frames in which the lighting system moves, realigns them, and selects the camera with the least occlusion to generate a video that consistently presents the surgical field from a fixed perspective. A user study involving surgeons demonstrated that videos generated by our method were superior to those produced by conventional methods in terms of the ease of confirming the surgical area and the comfort during video viewing. Additionally, our approach showed improvements in video quality over existing techniques. Furthermore, we implemented several synthesis options for the proposed view-synthesis method and conducted a user study to assess surgeons' preferences for each option.
Event-based Egocentric Human Pose Estimation in Dynamic Environment
May 28, 2025Estimating human pose using a front-facing egocentric camera is essential for applications such as sports motion analysis, VR/AR, and AI for wearable devices. However, many existing methods rely on RGB cameras and do not account for low-light environments or motion blur. Event-based cameras have the potential to address these challenges. In this work, we introduce a novel task of human pose estimation using a front-facing event-based camera mounted on the head and propose D-EventEgo, the first framework for this task. The proposed method first estimates the head poses, and then these are used as conditions to generate body poses. However, when estimating head poses, the presence of dynamic objects mixed with background events may reduce head pose estimation accuracy. Therefore, we introduce the Motion Segmentation Module to remove dynamic objects and extract background information. Extensive experiments on our synthetic event-based dataset derived from EgoBody, demonstrate that our approach outperforms our baseline in four out of five evaluation metrics in dynamic environments.
EventEgoHands: Event-based Egocentric 3D Hand Mesh Reconstruction
May 25, 2025Reconstructing 3D hand mesh is challenging but an important task for human-computer interaction and AR/VR applications. In particular, RGB and/or depth cameras have been widely used in this task. However, methods using these conventional cameras face challenges in low-light environments and during motion blur. Thus, to address these limitations, event cameras have been attracting attention in recent years for their high dynamic range and high temporal resolution. Despite their advantages, event cameras are sensitive to background noise or camera motion, which has limited existing studies to static backgrounds and fixed cameras. In this study, we propose EventEgoHands, a novel method for event-based 3D hand mesh reconstruction in an egocentric view. Our approach introduces a Hand Segmentation Module that extracts hand regions, effectively mitigating the influence of dynamic background events. We evaluated our approach and demonstrated its effectiveness on the N-HOT3D dataset, improving MPJPE by approximately more than 4.5 cm (43%).
High-Quality Virtual Single-Viewpoint Surgical Video: Geometric Autocalibration of Multiple Cameras in Surgical Lights
Mar 05, 2025Occlusion-free video generation is challenging due to surgeons' obstructions in the camera field of view. Prior work has addressed this issue by installing multiple cameras on a surgical light, hoping some cameras will observe the surgical field with less occlusion. However, this special camera setup poses a new imaging challenge since camera configurations can change every time surgeons move the light, and manual image alignment is required. This paper proposes an algorithm to automate this alignment task. The proposed method detects frames where the lighting system moves, realigns them, and selects the camera with the least occlusion. This algorithm results in a stabilized video with less occlusion. Quantitative results show that our method outperforms conventional approaches. A user study involving medical doctors also confirmed the superiority of our method.
Dense Depth from Event Focal Stack
Dec 11, 2024We propose a method for dense depth estimation from an event stream generated when sweeping the focal plane of the driving lens attached to an event camera. In this method, a depth map is inferred from an ``event focal stack'' composed of the event stream using a convolutional neural network trained with synthesized event focal stacks. The synthesized event stream is created from a focal stack generated by Blender for any arbitrary 3D scene. This allows for training on scenes with diverse structures. Additionally, we explored methods to eliminate the domain gap between real event streams and synthetic event streams. Our method demonstrates superior performance over a depth-from-defocus method in the image domain on synthetic and real datasets.
Acoustic-based 3D Human Pose Estimation Robust to Human Position
Nov 08, 2024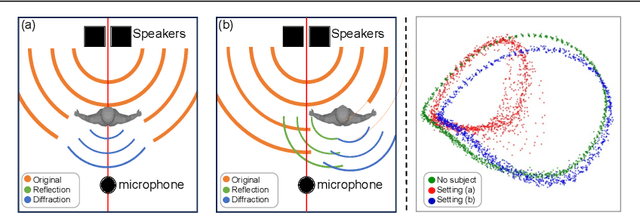
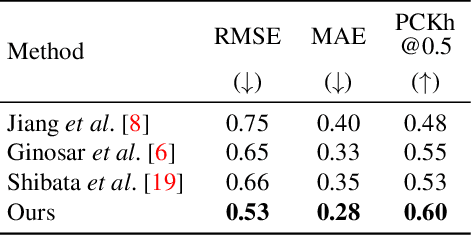
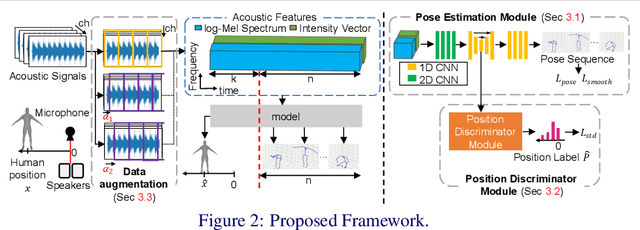
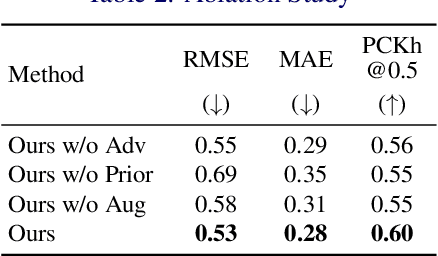
This paper explores the problem of 3D human pose estimation from only low-level acoustic signals. The existing active acoustic sensing-based approach for 3D human pose estimation implicitly assumes that the target user is positioned along a line between loudspeakers and a microphone. Because reflection and diffraction of sound by the human body cause subtle acoustic signal changes compared to sound obstruction, the existing model degrades its accuracy significantly when subjects deviate from this line, limiting its practicality in real-world scenarios. To overcome this limitation, we propose a novel method composed of a position discriminator and reverberation-resistant model. The former predicts the standing positions of subjects and applies adversarial learning to extract subject position-invariant features. The latter utilizes acoustic signals before the estimation target time as references to enhance robustness against the variations in sound arrival times due to diffraction and reflection. We construct an acoustic pose estimation dataset that covers diverse human locations and demonstrate through experiments that our proposed method outperforms existing approaches.
Scapegoat Generation for Privacy Protection from Deepfake
Mar 06, 2023



To protect privacy and prevent malicious use of deepfake, current studies propose methods that interfere with the generation process, such as detection and destruction approaches. However, these methods suffer from sub-optimal generalization performance to unseen models and add undesirable noise to the original image. To address these problems, we propose a new problem formulation for deepfake prevention: generating a ``scapegoat image'' by modifying the style of the original input in a way that is recognizable as an avatar by the user, but impossible to reconstruct the real face. Even in the case of malicious deepfake, the privacy of the users is still protected. To achieve this, we introduce an optimization-based editing method that utilizes GAN inversion to discourage deepfake models from generating similar scapegoats. We validate the effectiveness of our proposed method through quantitative and user studies.
Efficient Non-Line-of-Sight Imaging from Transient Sinograms
Aug 06, 2020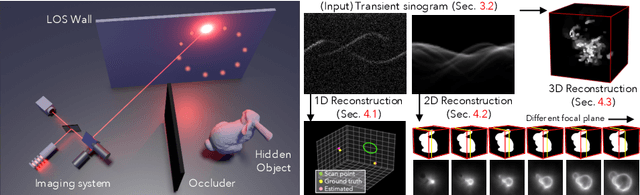



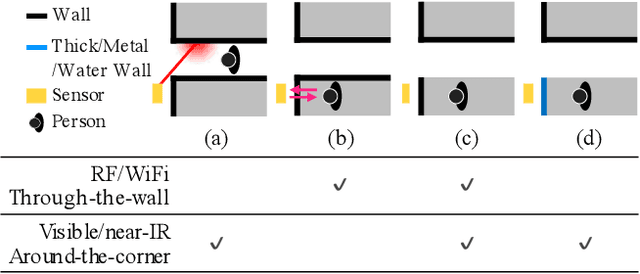
Non-line-of-sight (NLOS) imaging techniques use light that diffusely reflects off of visible surfaces (e.g., walls) to see around corners. One approach involves using pulsed lasers and ultrafast sensors to measure the travel time of multiply scattered light. Unlike existing NLOS techniques that generally require densely raster scanning points across the entirety of a relay wall, we explore a more efficient form of NLOS scanning that reduces both acquisition times and computational requirements. We propose a circular and confocal non-line-of-sight (C2NLOS) scan that involves illuminating and imaging a common point, and scanning this point in a circular path along a wall. We observe that (1) these C2NLOS measurements consist of a superposition of sinusoids, which we refer to as a transient sinogram, (2) there exists computationally efficient reconstruction procedures that transform these sinusoidal measurements into 3D positions of hidden scatterers or NLOS images of hidden objects, and (3) despite operating on an order of magnitude fewer measurements than previous approaches, these C2NLOS scans provide sufficient information about the hidden scene to solve these different NLOS imaging tasks. We show results from both simulated and real C2NLOS scans.
Optical Non-Line-of-Sight Physics-based 3D Human Pose Estimation
Mar 31, 2020
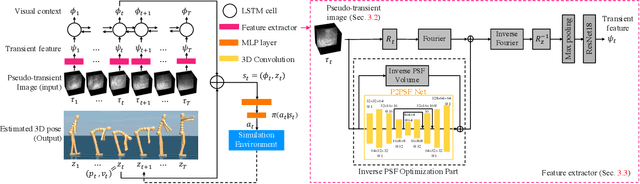

We describe a method for 3D human pose estimation from transient images (i.e., a 3D spatio-temporal histogram of photons) acquired by an optical non-line-of-sight (NLOS) imaging system. Our method can perceive 3D human pose by `looking around corners' through the use of light indirectly reflected by the environment. We bring together a diverse set of technologies from NLOS imaging, human pose estimation and deep reinforcement learning to construct an end-to-end data processing pipeline that converts a raw stream of photon measurements into a full 3D human pose sequence estimate. Our contributions are the design of data representation process which includes (1) a learnable inverse point spread function (PSF) to convert raw transient images into a deep feature vector; (2) a neural humanoid control policy conditioned on the transient image feature and learned from interactions with a physics simulator; and (3) a data synthesis and augmentation strategy based on depth data that can be transferred to a real-world NLOS imaging system. Our preliminary experiments suggest that our method is able to generalize to real-world NLOS measurement to estimate physically-valid 3D human poses.