 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisturbance-Free Surgical Video Generation from Multi-Camera Shadowless Lamps for Open Surgery
Dec 09, 2025

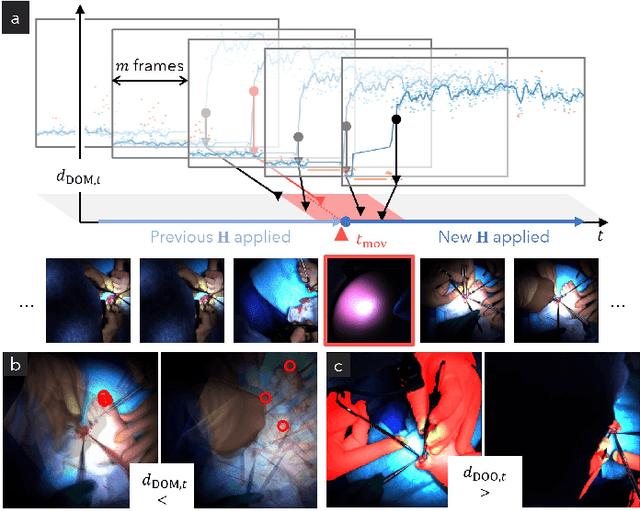

Video recordings of open surgeries are greatly required for education and research purposes. However, capturing unobstructed videos is challenging since surgeons frequently block the camera field of view. To avoid occlusion, the positions and angles of the camera must be frequently adjusted, which is highly labor-intensive. Prior work has addressed this issue by installing multiple cameras on a shadowless lamp and arranging them to fully surround the surgical area. This setup increases the chances of some cameras capturing an unobstructed view. However, manual image alignment is needed in post-processing since camera configurations change every time surgeons move the lamp for optimal lighting. This paper aims to fully automate this alignment task. The proposed method identifies frames in which the lighting system moves, realigns them, and selects the camera with the least occlusion to generate a video that consistently presents the surgical field from a fixed perspective. A user study involving surgeons demonstrated that videos generated by our method were superior to those produced by conventional methods in terms of the ease of confirming the surgical area and the comfort during video viewing. Additionally, our approach showed improvements in video quality over existing techniques. Furthermore, we implemented several synthesis options for the proposed view-synthesis method and conducted a user study to assess surgeons' preferences for each option.
EgoSurgery-HTS: A Dataset for Egocentric Hand-Tool Segmentation in Open Surgery Videos
Mar 24, 2025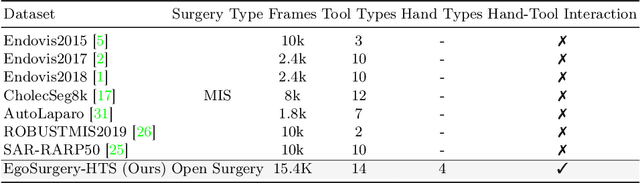

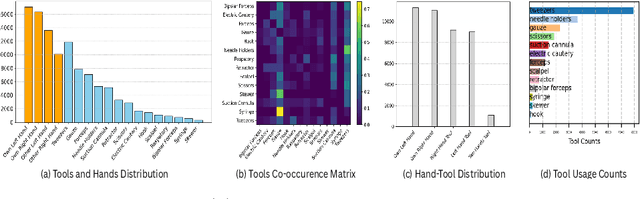
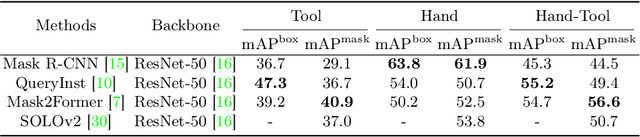
Egocentric open-surgery videos capture rich, fine-grained details essential for accurately modeling surgical procedures and human behavior in the operating room. A detailed, pixel-level understanding of hands and surgical tools is crucial for interpreting a surgeon's actions and intentions. We introduce EgoSurgery-HTS, a new dataset with pixel-wise annotations and a benchmark suite for segmenting surgical tools, hands, and interacting tools in egocentric open-surgery videos. Specifically, we provide a labeled dataset for (1) tool instance segmentation of 14 distinct surgical tools, (2) hand instance segmentation, and (3) hand-tool segmentation to label hands and the tools they manipulate. Using EgoSurgery-HTS, we conduct extensive evaluations of state-of-the-art segmentation methods and demonstrate significant improvements in the accuracy of hand and hand-tool segmentation in egocentric open-surgery videos compared to existing datasets. The dataset will be released at https://github.com/Fujiry0/EgoSurgery.
High-Quality Virtual Single-Viewpoint Surgical Video: Geometric Autocalibration of Multiple Cameras in Surgical Lights
Mar 05, 2025Occlusion-free video generation is challenging due to surgeons' obstructions in the camera field of view. Prior work has addressed this issue by installing multiple cameras on a surgical light, hoping some cameras will observe the surgical field with less occlusion. However, this special camera setup poses a new imaging challenge since camera configurations can change every time surgeons move the light, and manual image alignment is required. This paper proposes an algorithm to automate this alignment task. The proposed method detects frames where the lighting system moves, realigns them, and selects the camera with the least occlusion. This algorithm results in a stabilized video with less occlusion. Quantitative results show that our method outperforms conventional approaches. A user study involving medical doctors also confirmed the superiority of our method.
EgoSurgery-Tool: A Dataset of Surgical Tool and Hand Detection from Egocentric Open Surgery Videos
Jun 06, 2024Surgical tool detection is a fundamental task for understanding egocentric open surgery videos. However, detecting surgical tools presents significant challenges due to their highly imbalanced class distribution, similar shapes and similar textures, and heavy occlusion. The lack of a comprehensive large-scale dataset compounds these challenges. In this paper, we introduce EgoSurgery-Tool, an extension of the existing EgoSurgery-Phase dataset, which contains real open surgery videos captured using an egocentric camera attached to the surgeon's head, along with phase annotations. EgoSurgery-Tool has been densely annotated with surgical tools and comprises over 49K surgical tool bounding boxes across 15 categories, constituting a large-scale surgical tool detection dataset. EgoSurgery-Tool also provides annotations for hand detection with over 46K hand-bounding boxes, capturing hand-object interactions that are crucial for understanding activities in egocentric open surgery. EgoSurgery-Tool is superior to existing datasets due to its larger scale, greater variety of surgical tools, more annotations, and denser scenes. We conduct a comprehensive analysis of EgoSurgery-Tool using nine popular object detectors to assess their effectiveness in both surgical tool and hand detection. The dataset will be released at https://github.com/Fujiry0/EgoSurgery.
EgoSurgery-Phase: A Dataset of Surgical Phase Recognition from Egocentric Open Surgery Videos
May 30, 2024Surgical phase recognition has gained significant attention due to its potential to offer solutions to numerous demands of the modern operating room. However, most existing methods concentrate on minimally invasive surgery (MIS), leaving surgical phase recognition for open surgery understudied. This discrepancy is primarily attributed to the scarcity of publicly available open surgery video datasets for surgical phase recognition. To address this issue, we introduce a new egocentric open surgery video dataset for phase recognition, named EgoSurgery-Phase. This dataset comprises 15 hours of real open surgery videos spanning 9 distinct surgical phases all captured using an egocentric camera attached to the surgeon's head. In addition to video, the EgoSurgery-Phase offers eye gaze. As far as we know, it is the first real open surgery video dataset for surgical phase recognition publicly available. Furthermore, inspired by the notable success of masked autoencoders (MAEs) in video understanding tasks (e.g., action recognition), we propose a gaze-guided masked autoencoder (GGMAE). Considering the regions where surgeons' gaze focuses are often critical for surgical phase recognition (e.g., surgical field), in our GGMAE, the gaze information acts as an empirical semantic richness prior to guiding the masking process, promoting better attention to semantically rich spatial regions. GGMAE significantly improves the previous state-of-the-art recognition method (6.4% in Jaccard) and the masked autoencoder-based method (3.1% in Jaccard) on EgoSurgery-Phase. The dataset will be released at https://github.com/Fujiry0/EgoSurgery.
Deep Selection: A Fully Supervised Camera Selection Network for Surgery Recordings
Mar 28, 2023Recording surgery in operating rooms is an essential task for education and evaluation of medical treatment. However, recording the desired targets, such as the surgery field, surgical tools, or doctor's hands, is difficult because the targets are heavily occluded during surgery. We use a recording system in which multiple cameras are embedded in the surgical lamp, and we assume that at least one camera is recording the target without occlusion at any given time. As the embedded cameras obtain multiple video sequences, we address the task of selecting the camera with the best view of the surgery. Unlike the conventional method, which selects the camera based on the area size of the surgery field, we propose a deep neural network that predicts the camera selection probability from multiple video sequences by learning the supervision of the expert annotation. We created a dataset in which six different types of plastic surgery are recorded, and we provided the annotation of camera switching. Our experiments show that our approach successfully switched between cameras and outperformed three baseline methods.
Deep Learning in Diabetic Foot Ulcers Detection: A Comprehensive Evaluation
Oct 15, 2020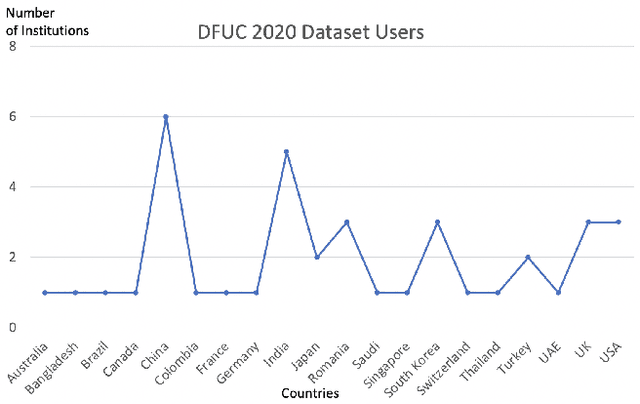
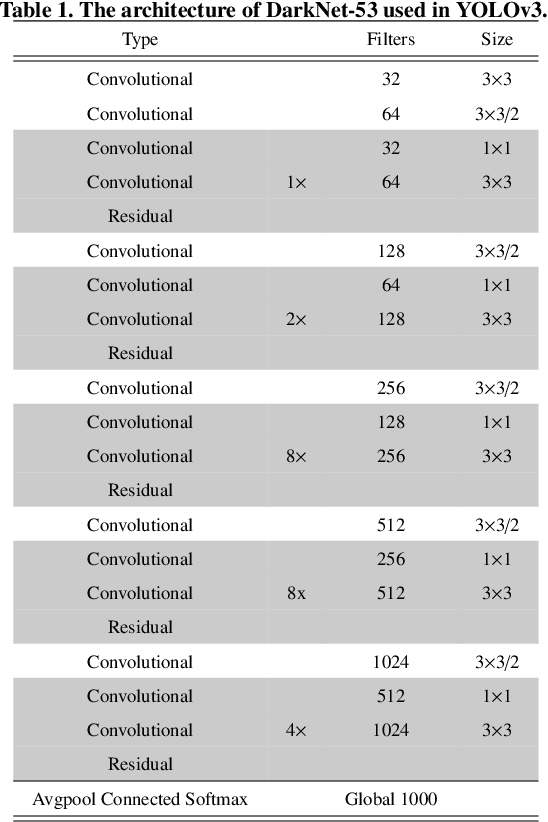
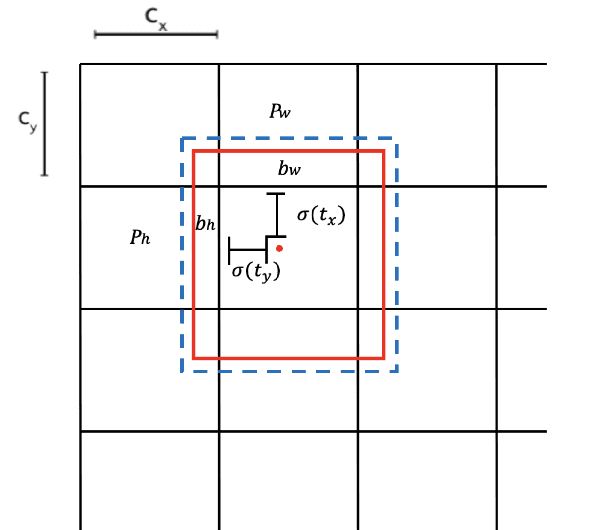
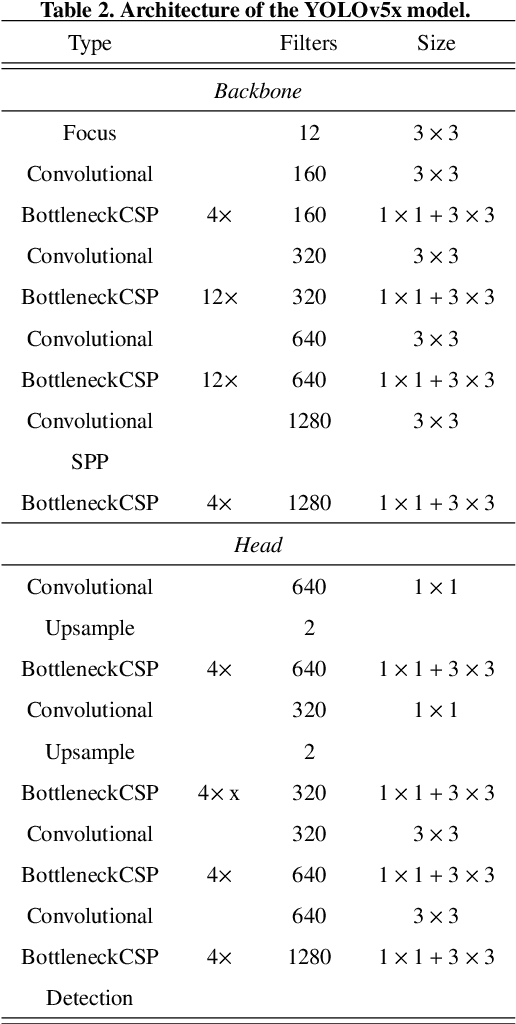
There has been a substantial amount of research on computer methods and technology for the detection and recognition of diabetic foot ulcers (DFUs), but there is a lack of systematic comparisons of state-of-the-art deep learning object detection frameworks applied to this problem. With recent development and data sharing performed as part of the DFU Challenge (DFUC2020) such a comparison becomes possible: DFUC2020 provided participants with a comprehensive dataset consisting of 2,000 images for training each method and 2,000 images for testing them. The following deep learning-based algorithms are compared in this paper: Faster R-CNN, three variants of Faster R-CNN and an ensemble method; YOLOv3; YOLOv5; EfficientDet; and a new Cascade Attention Network. For each deep learning method, we provide a detailed description of model architecture, parameter settings for training and additional stages including pre-processing, data augmentation and post-processing. We provide a comprehensive evaluation for each method. All the methods required a data augmentation stage to increase the number of images available for training and a post-processing stage to remove false positives. The best performance is obtained Deformable Convolution, a variant of Faster R-CNN, with a mAP of 0.6940 and an F1-Score of 0.7434. Finally, we demonstrate that the ensemble method based on different deep learning methods can enhanced the F1-Score but not the mAP. Our results show that state-of-the-art deep learning methods can detect DFU with some accuracy, but there are many challenges ahead before they can be implemented in real world settings.