 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrime and Reach: Synthesising Body Motion for Gaze-Primed Object Reach
Dec 18, 2025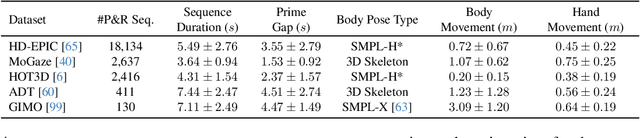



Human motion generation is a challenging task that aims to create realistic motion imitating natural human behaviour. We focus on the well-studied behaviour of priming an object/location for pick up or put down -- that is, the spotting of an object/location from a distance, known as gaze priming, followed by the motion of approaching and reaching the target location. To that end, we curate, for the first time, 23.7K gaze-primed human motion sequences for reaching target object locations from five publicly available datasets, i.e., HD-EPIC, MoGaze, HOT3D, ADT, and GIMO. We pre-train a text-conditioned diffusion-based motion generation model, then fine-tune it conditioned on goal pose or location, on our curated sequences. Importantly, we evaluate the ability of the generated motion to imitate natural human movement through several metrics, including the 'Reach Success' and a newly introduced 'Prime Success' metric. On the largest dataset, HD-EPIC, our model achieves 60% prime success and 89% reach success when conditioned on the goal object location.
Event-based Egocentric Human Pose Estimation in Dynamic Environment
May 28, 2025Estimating human pose using a front-facing egocentric camera is essential for applications such as sports motion analysis, VR/AR, and AI for wearable devices. However, many existing methods rely on RGB cameras and do not account for low-light environments or motion blur. Event-based cameras have the potential to address these challenges. In this work, we introduce a novel task of human pose estimation using a front-facing event-based camera mounted on the head and propose D-EventEgo, the first framework for this task. The proposed method first estimates the head poses, and then these are used as conditions to generate body poses. However, when estimating head poses, the presence of dynamic objects mixed with background events may reduce head pose estimation accuracy. Therefore, we introduce the Motion Segmentation Module to remove dynamic objects and extract background information. Extensive experiments on our synthetic event-based dataset derived from EgoBody, demonstrate that our approach outperforms our baseline in four out of five evaluation metrics in dynamic environments.
EventEgoHands: Event-based Egocentric 3D Hand Mesh Reconstruction
May 25, 2025Reconstructing 3D hand mesh is challenging but an important task for human-computer interaction and AR/VR applications. In particular, RGB and/or depth cameras have been widely used in this task. However, methods using these conventional cameras face challenges in low-light environments and during motion blur. Thus, to address these limitations, event cameras have been attracting attention in recent years for their high dynamic range and high temporal resolution. Despite their advantages, event cameras are sensitive to background noise or camera motion, which has limited existing studies to static backgrounds and fixed cameras. In this study, we propose EventEgoHands, a novel method for event-based 3D hand mesh reconstruction in an egocentric view. Our approach introduces a Hand Segmentation Module that extracts hand regions, effectively mitigating the influence of dynamic background events. We evaluated our approach and demonstrated its effectiveness on the N-HOT3D dataset, improving MPJPE by approximately more than 4.5 cm (43%).
The Invisible EgoHand: 3D Hand Forecasting through EgoBody Pose Estimation
Apr 11, 2025Forecasting hand motion and pose from an egocentric perspective is essential for understanding human intention. However, existing methods focus solely on predicting positions without considering articulation, and only when the hands are visible in the field of view. This limitation overlooks the fact that approximate hand positions can still be inferred even when they are outside the camera's view. In this paper, we propose a method to forecast the 3D trajectories and poses of both hands from an egocentric video, both in and out of the field of view. We propose a diffusion-based transformer architecture for Egocentric Hand Forecasting, EgoH4, which takes as input the observation sequence and camera poses, then predicts future 3D motion and poses for both hands of the camera wearer. We leverage full-body pose information, allowing other joints to provide constraints on hand motion. We denoise the hand and body joints along with a visibility predictor for hand joints and a 3D-to-2D reprojection loss that minimizes the error when hands are in-view. We evaluate EgoH4 on the Ego-Exo4D dataset, combining subsets with body and hand annotations. We train on 156K sequences and evaluate on 34K sequences, respectively. EgoH4 improves the performance by 3.4cm and 5.1cm over the baseline in terms of ADE for hand trajectory forecasting and MPJPE for hand pose forecasting. Project page: https://masashi-hatano.github.io/EgoH4/
Multimodal Cross-Domain Few-Shot Learning for Egocentric Action Recognition
May 31, 2024We address a novel cross-domain few-shot learning task (CD-FSL) with multimodal input and unlabeled target data for egocentric action recognition. This paper simultaneously tackles two critical challenges associated with egocentric action recognition in CD-FSL settings: (1) the extreme domain gap in egocentric videos (\eg, daily life vs. industrial domain) and (2) the computational cost for real-world applications. We propose MM-CDFSL, a domain-adaptive and computationally efficient approach designed to enhance adaptability to the target domain and improve inference speed. To address the first challenge, we propose the incorporation of multimodal distillation into the student RGB model using teacher models. Each teacher model is trained independently on source and target data for its respective modality. Leveraging only unlabeled target data during multimodal distillation enhances the student model's adaptability to the target domain. We further introduce ensemble masked inference, a technique that reduces the number of input tokens through masking. In this approach, ensemble prediction mitigates the performance degradation caused by masking, effectively addressing the second issue. Our approach outperformed the state-of-the-art CD-FSL approaches with a substantial margin on multiple egocentric datasets, improving by an average of 6.12/6.10 points for 1-shot/5-shot settings while achieving $2.2$ times faster inference speed. Project page: https://masashi-hatano.github.io/MM-CDFSL/
EMAG: Ego-motion Aware and Generalizable 2D Hand Forecasting from Egocentric Videos
May 30, 2024Predicting future human behavior from egocentric videos is a challenging but critical task for human intention understanding. Existing methods for forecasting 2D hand positions rely on visual representations and mainly focus on hand-object interactions. In this paper, we investigate the hand forecasting task and tackle two significant issues that persist in the existing methods: (1) 2D hand positions in future frames are severely affected by ego-motions in egocentric videos; (2) prediction based on visual information tends to overfit to background or scene textures, posing a challenge for generalization on novel scenes or human behaviors. To solve the aforementioned problems, we propose EMAG, an ego-motion-aware and generalizable 2D hand forecasting method. In response to the first problem, we propose a method that considers ego-motion, represented by a sequence of homography matrices of two consecutive frames. We further leverage modalities such as optical flow, trajectories of hands and interacting objects, and ego-motions, thereby alleviating the second issue. Extensive experiments on two large-scale egocentric video datasets, Ego4D and EPIC-Kitchens 55, verify the effectiveness of the proposed method. In particular, our model outperforms prior methods by $7.0$\% on cross-dataset evaluations. Project page: https://masashi-hatano.github.io/EMAG/
EgoSurgery-Phase: A Dataset of Surgical Phase Recognition from Egocentric Open Surgery Videos
May 30, 2024Surgical phase recognition has gained significant attention due to its potential to offer solutions to numerous demands of the modern operating room. However, most existing methods concentrate on minimally invasive surgery (MIS), leaving surgical phase recognition for open surgery understudied. This discrepancy is primarily attributed to the scarcity of publicly available open surgery video datasets for surgical phase recognition. To address this issue, we introduce a new egocentric open surgery video dataset for phase recognition, named EgoSurgery-Phase. This dataset comprises 15 hours of real open surgery videos spanning 9 distinct surgical phases all captured using an egocentric camera attached to the surgeon's head. In addition to video, the EgoSurgery-Phase offers eye gaze. As far as we know, it is the first real open surgery video dataset for surgical phase recognition publicly available. Furthermore, inspired by the notable success of masked autoencoders (MAEs) in video understanding tasks (e.g., action recognition), we propose a gaze-guided masked autoencoder (GGMAE). Considering the regions where surgeons' gaze focuses are often critical for surgical phase recognition (e.g., surgical field), in our GGMAE, the gaze information acts as an empirical semantic richness prior to guiding the masking process, promoting better attention to semantically rich spatial regions. GGMAE significantly improves the previous state-of-the-art recognition method (6.4% in Jaccard) and the masked autoencoder-based method (3.1% in Jaccard) on EgoSurgery-Phase. The dataset will be released at https://github.com/Fujiry0/EgoSurgery.