 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe N-Body Problem: Parallel Execution from Single-Person Egocentric Video
Dec 12, 2025Humans can intuitively parallelise complex activities, but can a model learn this from observing a single person? Given one egocentric video, we introduce the N-Body Problem: how N individuals, can hypothetically perform the same set of tasks observed in this video. The goal is to maximise speed-up, but naive assignment of video segments to individuals often violates real-world constraints, leading to physically impossible scenarios like two people using the same object or occupying the same space. To address this, we formalise the N-Body Problem and propose a suite of metrics to evaluate both performance (speed-up, task coverage) and feasibility (spatial collisions, object conflicts and causal constraints). We then introduce a structured prompting strategy that guides a Vision-Language Model (VLM) to reason about the 3D environment, object usage, and temporal dependencies to produce a viable parallel execution. On 100 videos from EPIC-Kitchens and HD-EPIC, our method for N = 2 boosts action coverage by 45% over a baseline prompt for Gemini 2.5 Pro, while simultaneously slashing collision rates, object and causal conflicts by 55%, 45% and 55% respectively.
Reconstructing Objects along Hand Interaction Timelines in Egocentric Video
Dec 08, 2025We introduce the task of Reconstructing Objects along Hand Interaction Timelines (ROHIT). We first define the Hand Interaction Timeline (HIT) from a rigid object's perspective. In a HIT, an object is first static relative to the scene, then is held in hand following contact, where its pose changes. This is usually followed by a firm grip during use, before it is released to be static again w.r.t. to the scene. We model these pose constraints over the HIT, and propose to propagate the object's pose along the HIT enabling superior reconstruction using our proposed Constrained Optimisation and Propagation (COP) framework. Importantly, we focus on timelines with stable grasps - i.e. where the hand is stably holding an object, effectively maintaining constant contact during use. This allows us to efficiently annotate, study, and evaluate object reconstruction in videos without 3D ground truth. We evaluate our proposed task, ROHIT, over two egocentric datasets, HOT3D and in-the-wild EPIC-Kitchens. In HOT3D, we curate 1.2K clips of stable grasps. In EPIC-Kitchens, we annotate 2.4K clips of stable grasps including 390 object instances across 9 categories from videos of daily interactions in 141 environments. Without 3D ground truth, we utilise 2D projection error to assess the reconstruction. Quantitatively, COP improves stable grasp reconstruction by 6.2-11.3% and HIT reconstruction by up to 24.5% with constrained pose propagation.
The Invisible EgoHand: 3D Hand Forecasting through EgoBody Pose Estimation
Apr 11, 2025Forecasting hand motion and pose from an egocentric perspective is essential for understanding human intention. However, existing methods focus solely on predicting positions without considering articulation, and only when the hands are visible in the field of view. This limitation overlooks the fact that approximate hand positions can still be inferred even when they are outside the camera's view. In this paper, we propose a method to forecast the 3D trajectories and poses of both hands from an egocentric video, both in and out of the field of view. We propose a diffusion-based transformer architecture for Egocentric Hand Forecasting, EgoH4, which takes as input the observation sequence and camera poses, then predicts future 3D motion and poses for both hands of the camera wearer. We leverage full-body pose information, allowing other joints to provide constraints on hand motion. We denoise the hand and body joints along with a visibility predictor for hand joints and a 3D-to-2D reprojection loss that minimizes the error when hands are in-view. We evaluate EgoH4 on the Ego-Exo4D dataset, combining subsets with body and hand annotations. We train on 156K sequences and evaluate on 34K sequences, respectively. EgoH4 improves the performance by 3.4cm and 5.1cm over the baseline in terms of ADE for hand trajectory forecasting and MPJPE for hand pose forecasting. Project page: https://masashi-hatano.github.io/EgoH4/
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025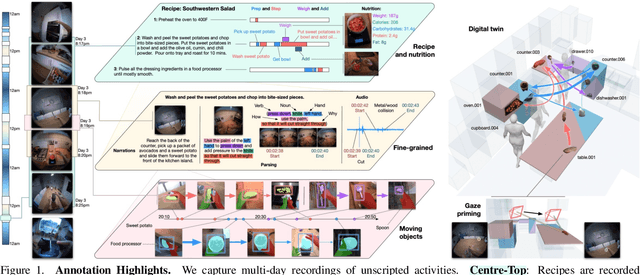
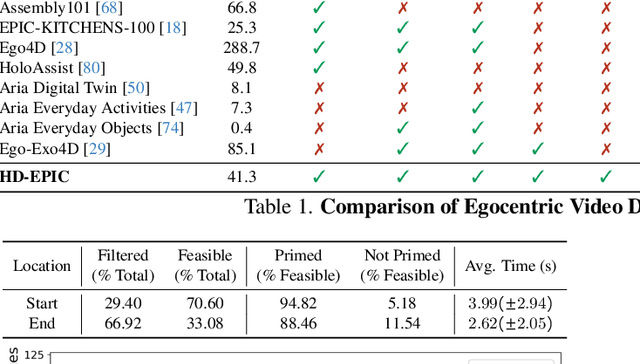

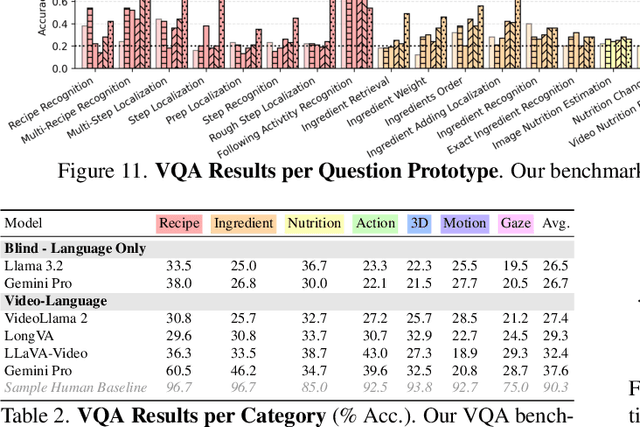
We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
Get a Grip: Reconstructing Hand-Object Stable Grasps in Egocentric Videos
Dec 25, 2023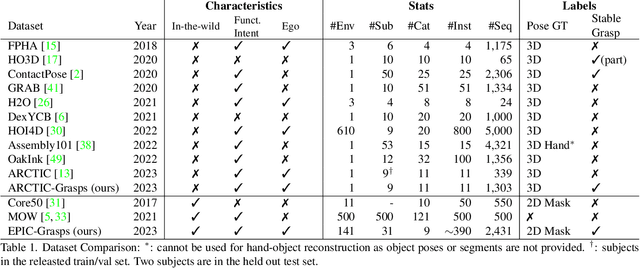
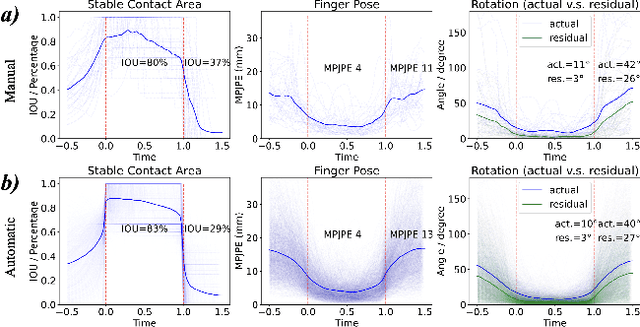
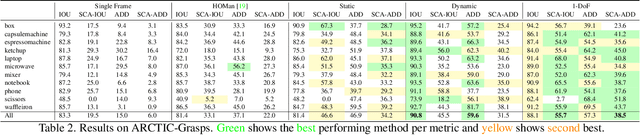
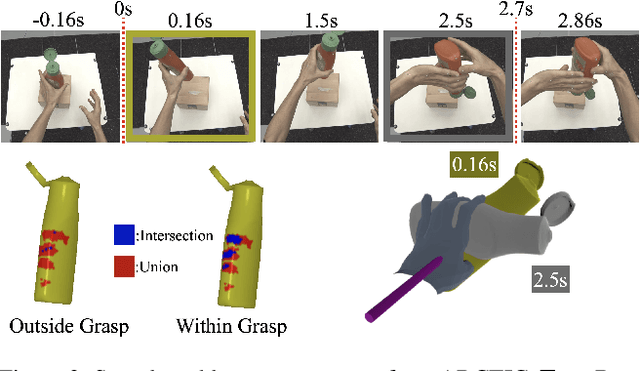
We address in-the-wild hand-object reconstruction for a known object category in egocentric videos, focusing on temporal periods of stable grasps. We propose the task of Hand-Object Stable Grasp Reconstruction (HO-SGR), the joint reconstruction of frames during which the hand is stably holding the object. We thus can constrain the object motion relative to the hand, effectively regularising the reconstruction and improving performance. By analysing the 3D ARCTIC dataset, we identify temporal periods where the contact area between the hand and object vertices remain stable. We showcase that objects within stable grasps move within a single degree of freedom (1~DoF). We thus propose a method for jointly optimising all frames within a stable grasp by minimising the object's rotation to that within a latent 1 DoF. We then extend this knowledge to in-the-wild egocentric videos by labelling 2.4K clips of stable grasps from the EPIC-KITCHENS dataset. Our proposed EPIC-Grasps dataset includes 390 object instances of 9 categories, featuring stable grasps from videos of daily interactions in 141 environments. Our method achieves significantly better HO-SGR, both qualitatively and by computing the stable grasp area and 2D projection labels of mask overlaps.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
EPIC Fields: Marrying 3D Geometry and Video Understanding
Jun 14, 2023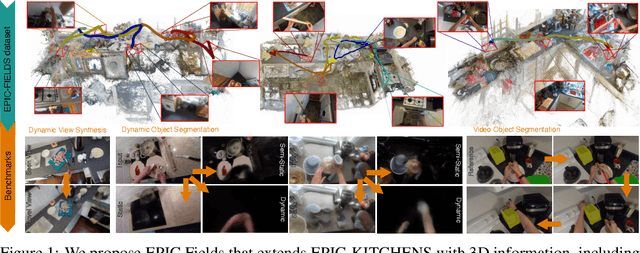

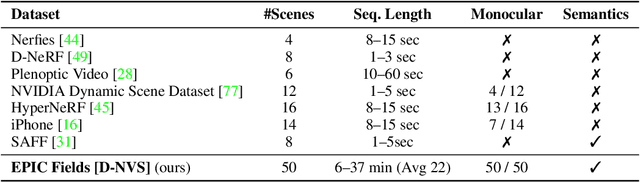

Neural rendering is fuelling a unification of learning, 3D geometry and video understanding that has been waiting for more than two decades. Progress, however, is still hampered by a lack of suitable datasets and benchmarks. To address this gap, we introduce EPIC Fields, an augmentation of EPIC-KITCHENS with 3D camera information. Like other datasets for neural rendering, EPIC Fields removes the complex and expensive step of reconstructing cameras using photogrammetry, and allows researchers to focus on modelling problems. We illustrate the challenge of photogrammetry in egocentric videos of dynamic actions and propose innovations to address them. Compared to other neural rendering datasets, EPIC Fields is better tailored to video understanding because it is paired with labelled action segments and the recent VISOR segment annotations. To further motivate the community, we also evaluate two benchmark tasks in neural rendering and segmenting dynamic objects, with strong baselines that showcase what is not possible today. We also highlight the advantage of geometry in semi-supervised video object segmentations on the VISOR annotations. EPIC Fields reconstructs 96% of videos in EPICKITCHENS, registering 19M frames in 99 hours recorded in 45 kitchens.