 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025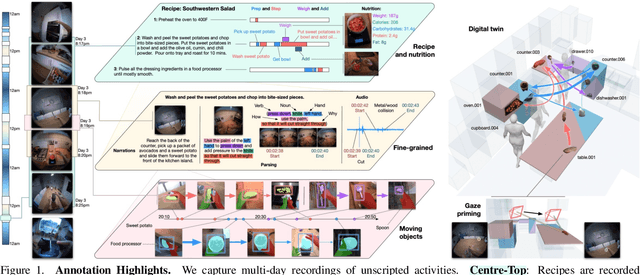
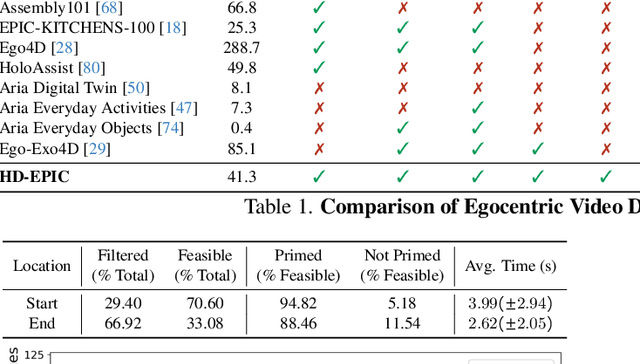

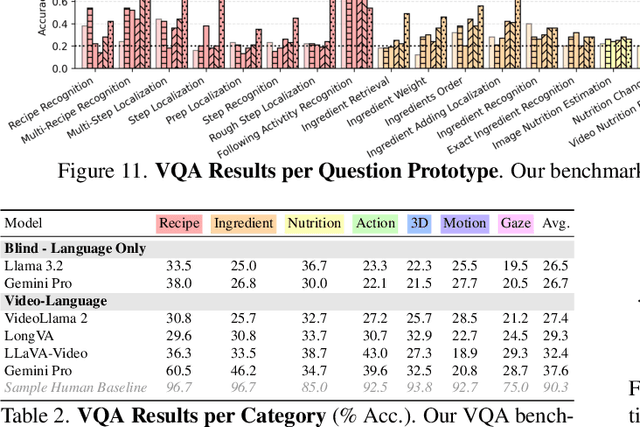
We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
EgoPoints: Advancing Point Tracking for Egocentric Videos
Dec 05, 2024



We introduce EgoPoints, a benchmark for point tracking in egocentric videos. We annotate 4.7K challenging tracks in egocentric sequences. Compared to the popular TAP-Vid-DAVIS evaluation benchmark, we include 9x more points that go out-of-view and 59x more points that require re-identification (ReID) after returning to view. To measure the performance of models on these challenging points, we introduce evaluation metrics that specifically monitor tracking performance on points in-view, out-of-view, and points that require re-identification. We then propose a pipeline to create semi-real sequences, with automatic ground truth. We generate 11K such sequences by combining dynamic Kubric objects with scene points from EPIC Fields. When fine-tuning point tracking methods on these sequences and evaluating on our annotated EgoPoints sequences, we improve CoTracker across all metrics, including the tracking accuracy $\delta^\star_{\text{avg}}$ by 2.7 percentage points and accuracy on ReID sequences (ReID$\delta_{\text{avg}}$) by 2.4 points. We also improve $\delta^\star_{\text{avg}}$ and ReID$\delta_{\text{avg}}$ of PIPs++ by 0.3 and 2.8 respectively.
EPIC Fields: Marrying 3D Geometry and Video Understanding
Jun 14, 2023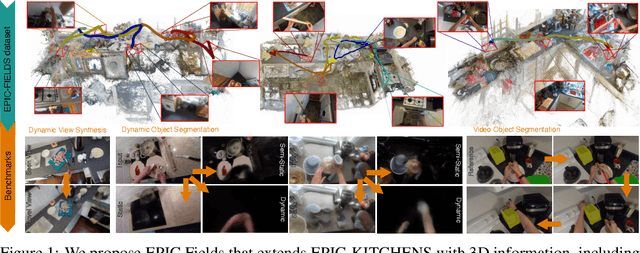

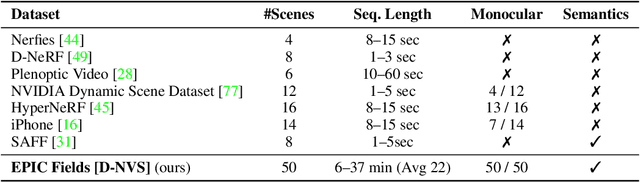

Neural rendering is fuelling a unification of learning, 3D geometry and video understanding that has been waiting for more than two decades. Progress, however, is still hampered by a lack of suitable datasets and benchmarks. To address this gap, we introduce EPIC Fields, an augmentation of EPIC-KITCHENS with 3D camera information. Like other datasets for neural rendering, EPIC Fields removes the complex and expensive step of reconstructing cameras using photogrammetry, and allows researchers to focus on modelling problems. We illustrate the challenge of photogrammetry in egocentric videos of dynamic actions and propose innovations to address them. Compared to other neural rendering datasets, EPIC Fields is better tailored to video understanding because it is paired with labelled action segments and the recent VISOR segment annotations. To further motivate the community, we also evaluate two benchmark tasks in neural rendering and segmenting dynamic objects, with strong baselines that showcase what is not possible today. We also highlight the advantage of geometry in semi-supervised video object segmentations on the VISOR annotations. EPIC Fields reconstructs 96% of videos in EPICKITCHENS, registering 19M frames in 99 hours recorded in 45 kitchens.
EPIC-KITCHENS VISOR Benchmark: VIdeo Segmentations and Object Relations
Sep 26, 2022
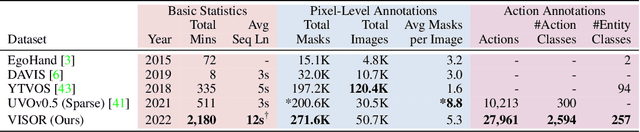
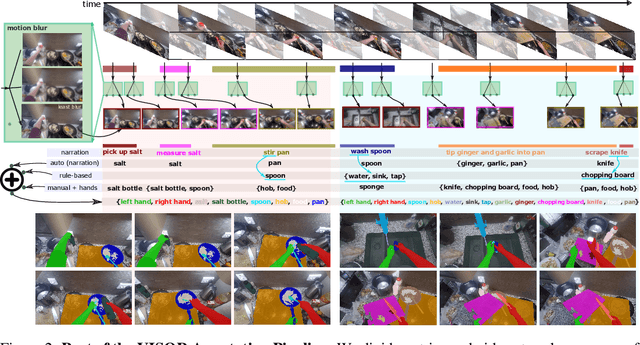
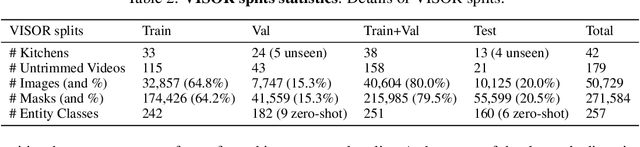
We introduce VISOR, a new dataset of pixel annotations and a benchmark suite for segmenting hands and active objects in egocentric video. VISOR annotates videos from EPIC-KITCHENS, which comes with a new set of challenges not encountered in current video segmentation datasets. Specifically, we need to ensure both short- and long-term consistency of pixel-level annotations as objects undergo transformative interactions, e.g. an onion is peeled, diced and cooked - where we aim to obtain accurate pixel-level annotations of the peel, onion pieces, chopping board, knife, pan, as well as the acting hands. VISOR introduces an annotation pipeline, AI-powered in parts, for scalability and quality. In total, we publicly release 272K manual semantic masks of 257 object classes, 9.9M interpolated dense masks, 67K hand-object relations, covering 36 hours of 179 untrimmed videos. Along with the annotations, we introduce three challenges in video object segmentation, interaction understanding and long-term reasoning. For data, code and leaderboards: http://epic-kitchens.github.io/VISOR