 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoireMix: A Formula-Based Data Augmentation for Improving Image Classification Robustness
Mar 26, 2026Data augmentation is a key technique for improving the robustness of image classification models. However, many recent approaches rely on diffusion-based synthesis or complex feature mixing strategies, which introduce substantial computational overhead or require external datasets. In this work, we explore a different direction: procedural augmentation based on analytic interference patterns. Unlike conventional augmentation methods that rely on stochastic noise, feature mixing, or generative models, our approach exploits Moire interference to generate structured perturbations spanning a wide range of spatial frequencies. We propose a lightweight augmentation method that procedurally generates Moire textures on-the-fly using a closed-form mathematical formulation. The patterns are synthesized directly in memory with negligible computational cost (0.0026 seconds per image), mixed with training images during training, and immediately discarded, enabling a storage-free augmentation pipeline without external data. Extensive experiments with Vision Transformers demonstrate that the proposed method consistently improves robustness across multiple benchmarks, including ImageNet-C, ImageNet-R, and adversarial benchmarks, outperforming standard augmentation baselines and existing external-data-free augmentation approaches. These results suggest that analytic interference patterns provide a practical and efficient alternative to data-driven generative augmentation methods.
3D sans 3D Scans: Scalable Pre-training from Video-Generated Point Clouds
Dec 28, 2025Despite recent progress in 3D self-supervised learning, collecting large-scale 3D scene scans remains expensive and labor-intensive. In this work, we investigate whether 3D representations can be learned from unlabeled videos recorded without any real 3D sensors. We present Laplacian-Aware Multi-level 3D Clustering with Sinkhorn-Knopp (LAM3C), a self-supervised framework that learns from video-generated point clouds from unlabeled videos. We first introduce RoomTours, a video-generated point cloud dataset constructed by collecting room-walkthrough videos from the web (e.g., real-estate tours) and generating 49,219 scenes using an off-the-shelf feed-forward reconstruction model. We also propose a noise-regularized loss that stabilizes representation learning by enforcing local geometric smoothness and ensuring feature stability under noisy point clouds. Remarkably, without using any real 3D scans, LAM3C achieves higher performance than the previous self-supervised methods on indoor semantic and instance segmentation. These results suggest that unlabeled videos represent an abundant source of data for 3D self-supervised learning.
Detect Fake with Fake: Leveraging Synthetic Data-driven Representation for Synthetic Image Detection
Sep 13, 2024Are general-purpose visual representations acquired solely from synthetic data useful for detecting fake images? In this work, we show the effectiveness of synthetic data-driven representations for synthetic image detection. Upon analysis, we find that vision transformers trained by the latest visual representation learners with synthetic data can effectively distinguish fake from real images without seeing any real images during pre-training. Notably, using SynCLR as the backbone in a state-of-the-art detection method demonstrates a performance improvement of +10.32 mAP and +4.73% accuracy over the widely used CLIP, when tested on previously unseen GAN models. Code is available at https://github.com/cvpaperchallenge/detect-fake-with-fake.
Enhancing Inverse Problem Solutions with Accurate Surrogate Simulators and Promising Candidates
Apr 26, 2023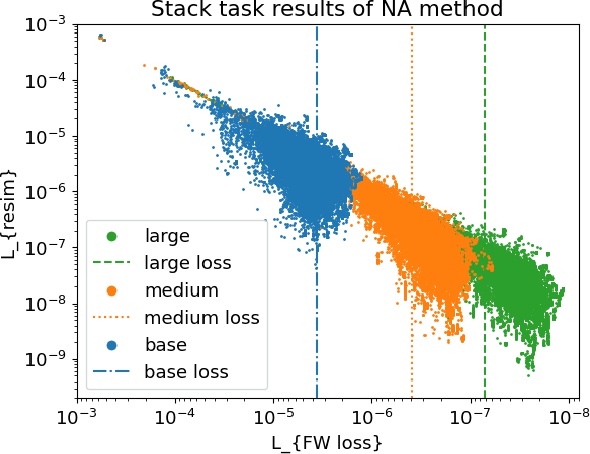

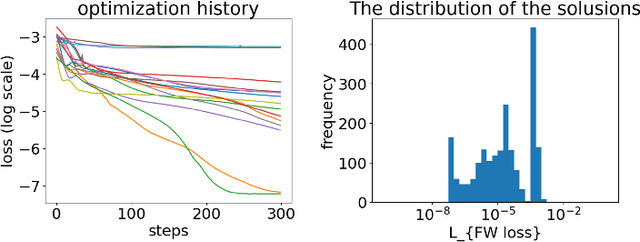

Deep-learning inverse techniques have attracted significant attention in recent years. Among them, the neural adjoint (NA) method, which employs a neural network surrogate simulator, has demonstrated impressive performance in the design tasks of artificial electromagnetic materials (AEM). However, the impact of the surrogate simulators' accuracy on the solutions in the NA method remains uncertain. Furthermore, achieving sufficient optimization becomes challenging in this method when the surrogate simulator is large, and computational resources are limited. Additionally, the behavior under constraints has not been studied, despite its importance from the engineering perspective. In this study, we investigated the impact of surrogate simulators' accuracy on the solutions and discovered that the more accurate the surrogate simulator is, the better the solutions become. We then developed an extension of the NA method, named Neural Lagrangian (NeuLag) method, capable of efficiently optimizing a sufficient number of solution candidates. We then demonstrated that the NeuLag method can find optimal solutions even when handling sufficient candidates is difficult due to the use of a large and accurate surrogate simulator. The resimulation errors of the NeuLag method were approximately 1/50 compared to previous methods for three AEM tasks. Finally, we performed optimization under constraint using NA and NeuLag, and confirmed their potential in optimization with soft or hard constraints. We believe our method holds potential in areas that require large and accurate surrogate simulators.
Scapegoat Generation for Privacy Protection from Deepfake
Mar 06, 2023



To protect privacy and prevent malicious use of deepfake, current studies propose methods that interfere with the generation process, such as detection and destruction approaches. However, these methods suffer from sub-optimal generalization performance to unseen models and add undesirable noise to the original image. To address these problems, we propose a new problem formulation for deepfake prevention: generating a ``scapegoat image'' by modifying the style of the original input in a way that is recognizable as an avatar by the user, but impossible to reconstruct the real face. Even in the case of malicious deepfake, the privacy of the users is still protected. To achieve this, we introduce an optimization-based editing method that utilizes GAN inversion to discourage deepfake models from generating similar scapegoats. We validate the effectiveness of our proposed method through quantitative and user studies.
Neural Density-Distance Fields
Jul 29, 2022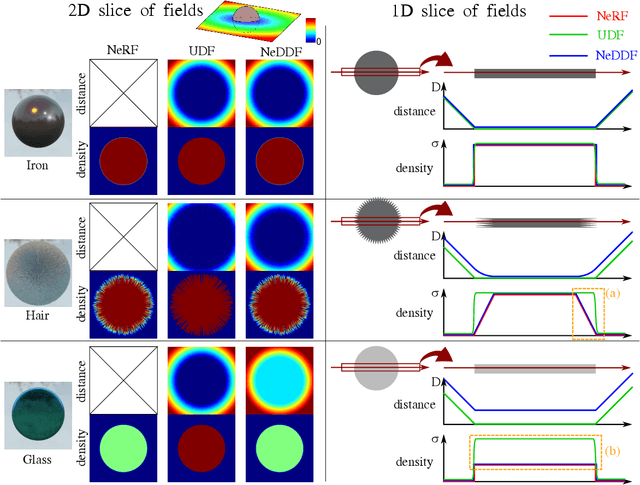

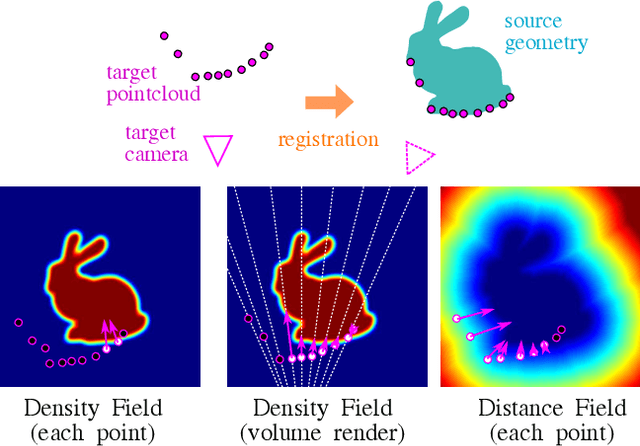
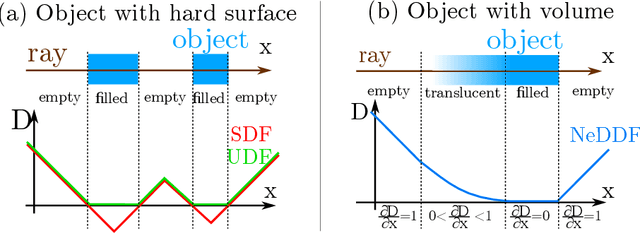
The success of neural fields for 3D vision tasks is now indisputable. Following this trend, several methods aiming for visual localization (e.g., SLAM) have been proposed to estimate distance or density fields using neural fields. However, it is difficult to achieve high localization performance by only density fields-based methods such as Neural Radiance Field (NeRF) since they do not provide density gradient in most empty regions. On the other hand, distance field-based methods such as Neural Implicit Surface (NeuS) have limitations in objects' surface shapes. This paper proposes Neural Density-Distance Field (NeDDF), a novel 3D representation that reciprocally constrains the distance and density fields. We extend distance field formulation to shapes with no explicit boundary surface, such as fur or smoke, which enable explicit conversion from distance field to density field. Consistent distance and density fields realized by explicit conversion enable both robustness to initial values and high-quality registration. Furthermore, the consistency between fields allows fast convergence from sparse point clouds. Experiments show that NeDDF can achieve high localization performance while providing comparable results to NeRF on novel view synthesis. The code is available at https://github.com/ueda0319/neddf.
RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions
Jul 31, 2021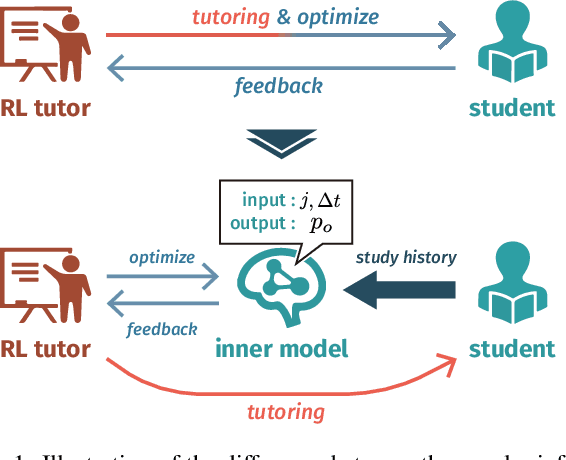
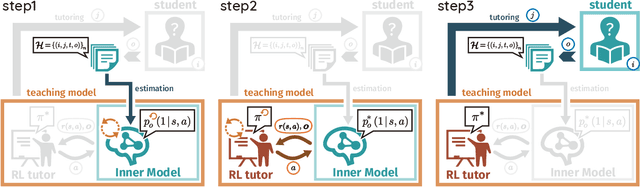
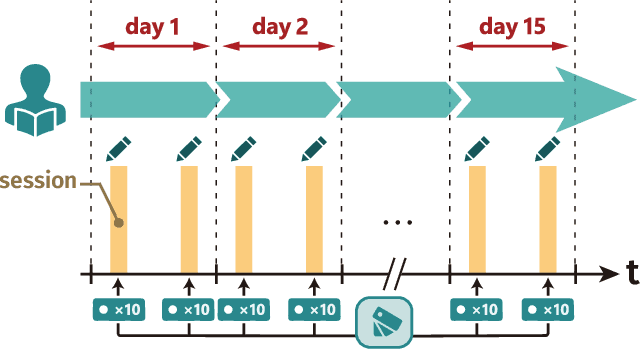
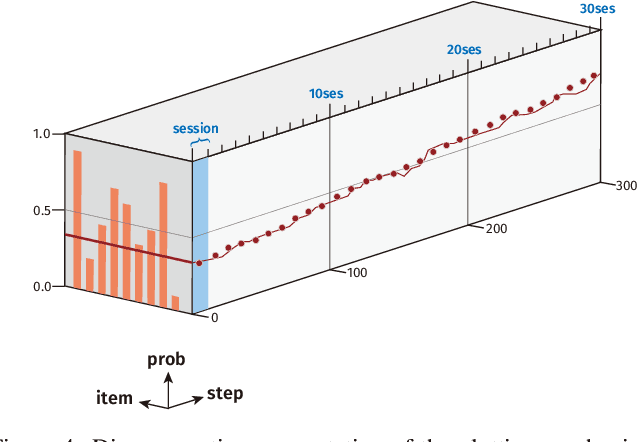
A major challenge in the field of education is providing review schedules that present learned items at appropriate intervals to each student so that memory is retained over time. In recent years, attempts have been made to formulate item reviews as sequential decision-making problems to realize adaptive instruction based on the knowledge state of students. It has been reported previously that reinforcement learning can help realize mathematical models of students learning strategies to maintain a high memory rate. However, optimization using reinforcement learning requires a large number of interactions, and thus it cannot be applied directly to actual students. In this study, we propose a framework for optimizing teaching strategies by constructing a virtual model of the student while minimizing the interaction with the actual teaching target. In addition, we conducted an experiment considering actual instructions using the mathematical model and confirmed that the model performance is comparable to that of conventional teaching methods. Our framework can directly substitute mathematical models used in experiments with human students, and our results can serve as a buffer between theoretical instructional optimization and practical applications in e-learning systems.
ATRO: Adversarial Training with a Rejection Option
Oct 24, 2020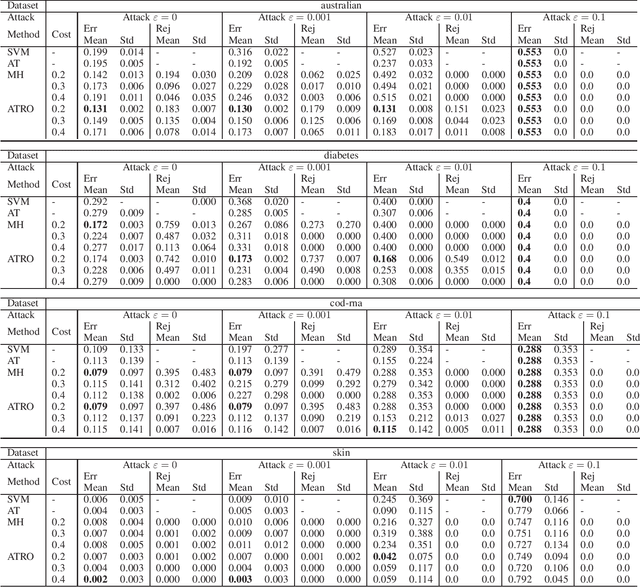
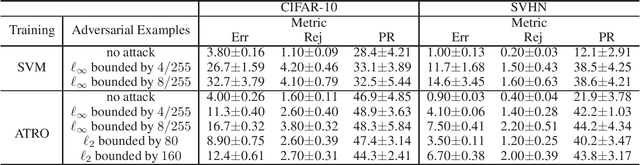
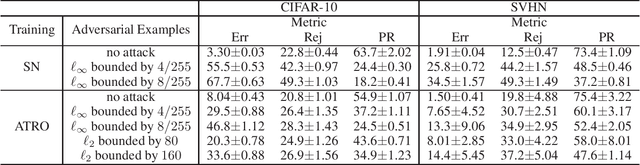
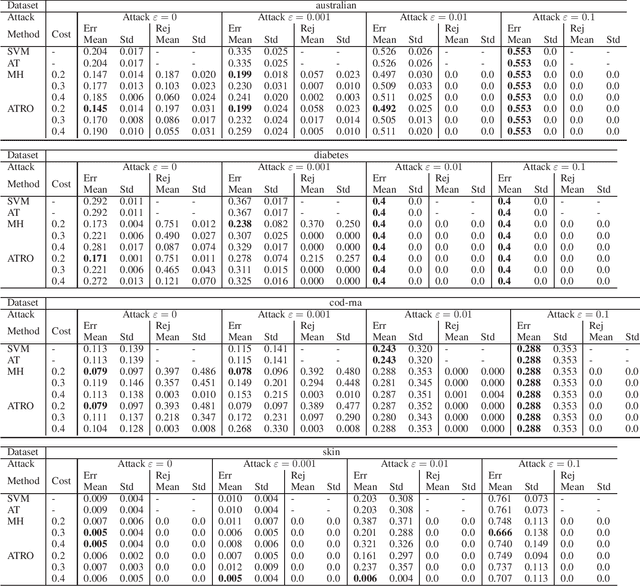
This paper proposes a classification framework with a rejection option to mitigate the performance deterioration caused by adversarial examples. While recent machine learning algorithms achieve high prediction performance, they are empirically vulnerable to adversarial examples, which are slightly perturbed data samples that are wrongly classified. In real-world applications, adversarial attacks using such adversarial examples could cause serious problems. To this end, various methods are proposed to obtain a classifier that is robust against adversarial examples. Adversarial training is one of them, which trains a classifier to minimize the worst-case loss under adversarial attacks. In this paper, in order to acquire a more reliable classifier against adversarial attacks, we propose the method of Adversarial Training with a Rejection Option (ATRO). Applying the adversarial training objective to both a classifier and a rejection function simultaneously, classifiers trained by ATRO can choose to abstain from classification when it has insufficient confidence to classify a test data point. We examine the feasibility of the framework using the surrogate maximum hinge loss and establish a generalization bound for linear models. Furthermore, we empirically confirmed the effectiveness of ATRO using various models and real-world datasets.
What Do Adversarially Robust Models Look At?
May 19, 2019

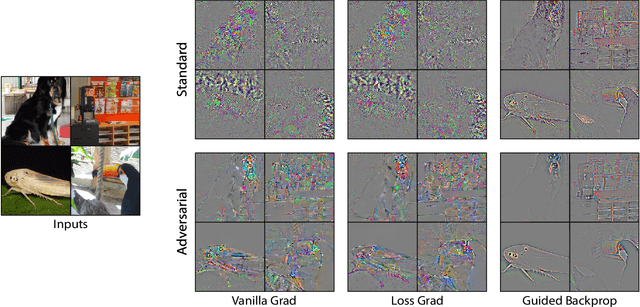
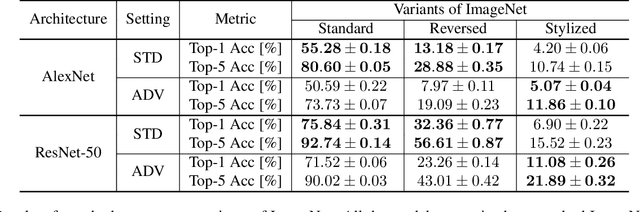
In this paper, we address the open question: "What do adversarially robust models look at?" Recently, it has been reported in many works that there exists the trade-off between standard accuracy and adversarial robustness. According to prior works, this trade-off is rooted in the fact that adversarially robust and standard accurate models might depend on very different sets of features. However, it has not been well studied what kind of difference actually exists. In this paper, we analyze this difference through various experiments visually and quantitatively. Experimental results show that adversarially robust models look at things at a larger scale than standard models and pay less attention to fine textures. Furthermore, although it has been claimed that adversarially robust features are not compatible with standard accuracy, there is even a positive effect by using them as pre-trained models particularly in low resolution datasets.
Automatic Paper Summary Generation from Visual and Textual Information
Nov 16, 2018Due to the recent boom in artificial intelligence (AI) research, including computer vision (CV), it has become impossible for researchers in these fields to keep up with the exponentially increasing number of manuscripts. In response to this situation, this paper proposes the paper summary generation (PSG) task using a simple but effective method to automatically generate an academic paper summary from raw PDF data. We realized PSG by combination of vision-based supervised components detector and language-based unsupervised important sentence extractor, which is applicable for a trained format of manuscripts. We show the quantitative evaluation of ability of simple vision-based components extraction, and the qualitative evaluation that our system can extract both visual item and sentence that are helpful for understanding. After processing via our PSG, the 979 manuscripts accepted by the Conference on Computer Vision and Pattern Recognition (CVPR) 2018 are available. It is believed that the proposed method will provide a better way for researchers to stay caught with important academic papers.