 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity-Driven Comprehensive Scientific Paper Summarization: Insight from cvpaper.challenge
Mar 17, 2022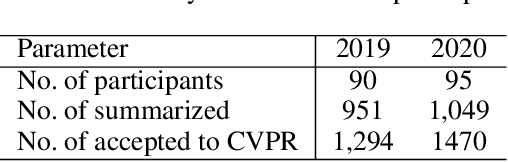


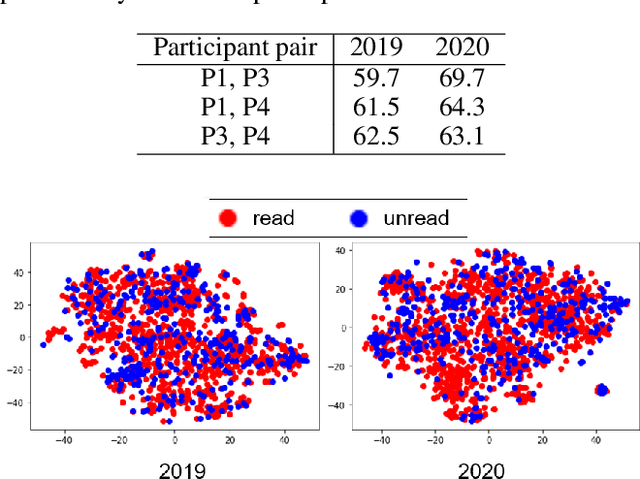
The present paper introduces a group activity involving writing summaries of conference proceedings by volunteer participants. The rapid increase in scientific papers is a heavy burden for researchers, especially non-native speakers, who need to survey scientific literature. To alleviate this problem, we organized a group of non-native English speakers to write summaries of papers presented at a computer vision conference to share the knowledge of the papers read by the group. We summarized a total of 2,000 papers presented at the Conference on Computer Vision and Pattern Recognition, a top-tier conference on computer vision, in 2019 and 2020. We quantitatively analyzed participants' selection regarding which papers they read among the many available papers. The experimental results suggest that we can summarize a wide range of papers without asking participants to read papers unrelated to their interests.
Describing and Localizing Multiple Changes with Transformers
Mar 25, 2021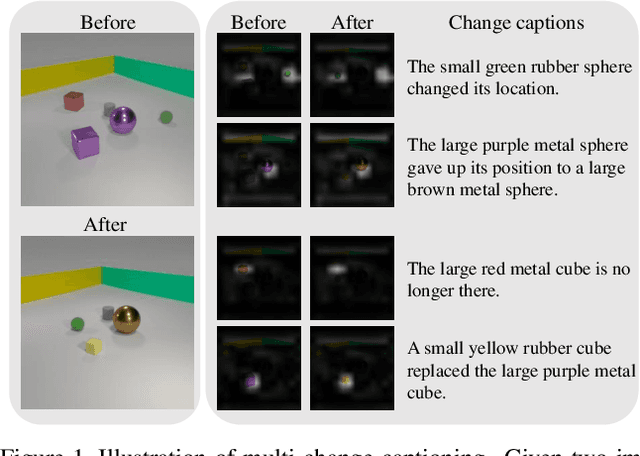
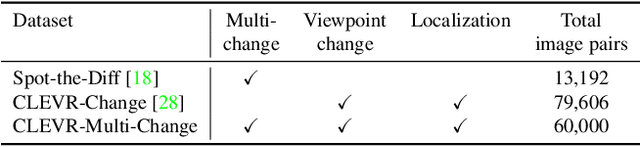


Change captioning tasks aim to detect changes in image pairs observed before and after a scene change and generate a natural language description of the changes. Existing change captioning studies have mainly focused on scenes with a single change. However, detecting and describing multiple changed parts in image pairs is essential for enhancing adaptability to complex scenarios. We solve the above issues from three aspects: (i) We propose a CG-based multi-change captioning dataset; (ii) We benchmark existing state-of-the-art methods of single change captioning on multi-change captioning; (iii) We further propose Multi-Change Captioning transformers (MCCFormers) that identify change regions by densely correlating different regions in image pairs and dynamically determines the related change regions with words in sentences. The proposed method obtained the highest scores on four conventional change captioning evaluation metrics for multi-change captioning. In addition, existing methods generate a single attention map for multiple changes and lack the ability to distinguish change regions. In contrast, our proposed method can separate attention maps for each change and performs well with respect to change localization. Moreover, the proposed framework outperformed the previous state-of-the-art methods on an existing change captioning benchmark, CLEVR-Change, by a large margin (+6.1 on BLEU-4 and +9.7 on CIDEr scores), indicating its general ability in change captioning tasks.
Hyperbolic Disk Embeddings for Directed Acyclic Graphs
Feb 13, 2019



Obtaining continuous representations of structural data such as directed acyclic graphs (DAGs) has gained attention in machine learning and artificial intelligence. However, embedding complex DAGs in which both ancestors and descendants of nodes are exponentially increasing is difficult. Tackling in this problem, we develop Disk Embeddings, which is a framework for embedding DAGs into quasi-metric spaces. Existing state-of-the-art methods, Order Embeddings and Hyperbolic Entailment Cones, are instances of Disk Embedding in Euclidean space and spheres respectively. Furthermore, we propose a novel method Hyperbolic Disk Embeddings to handle exponential growth of relations. The results of our experiments show that our Disk Embedding models outperform existing methods especially in complex DAGs other than trees.
Automatic Paper Summary Generation from Visual and Textual Information
Nov 16, 2018Due to the recent boom in artificial intelligence (AI) research, including computer vision (CV), it has become impossible for researchers in these fields to keep up with the exponentially increasing number of manuscripts. In response to this situation, this paper proposes the paper summary generation (PSG) task using a simple but effective method to automatically generate an academic paper summary from raw PDF data. We realized PSG by combination of vision-based supervised components detector and language-based unsupervised important sentence extractor, which is applicable for a trained format of manuscripts. We show the quantitative evaluation of ability of simple vision-based components extraction, and the qualitative evaluation that our system can extract both visual item and sentence that are helpful for understanding. After processing via our PSG, the 979 manuscripts accepted by the Conference on Computer Vision and Pattern Recognition (CVPR) 2018 are available. It is believed that the proposed method will provide a better way for researchers to stay caught with important academic papers.
Solving Non-identifiable Latent Feature Models
Sep 26, 2018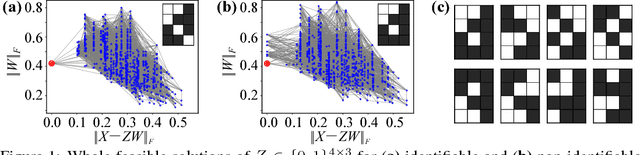



Latent feature models (LFM)s are widely employed for extracting latent structures of data. While offering high, parameter estimation is difficult with LFMs because of the combinational nature of latent features, and non-identifiability is a particularly difficult problem when parameter estimation is not unique and there exists equivalent solutions. In this paper, a necessary and sufficient condition for non-identifiability is shown. The condition is significantly related to dependency of features, and this implies that non-identifiability may often occur in real-world applications. A novel method for parameter estimation that solves the non-identifiability problem is also proposed. This method can be combined as a post-process with existing methods and can find an appropriate solution by hopping efficiently through equivalent solutions. We have evaluated the effectiveness of the method on both synthetic and real-world datasets.