 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidelines for External Disturbance Factors in the Use of OCR in Real-World Environments
Apr 21, 2025The performance of OCR has improved with the evolution of AI technology. As OCR continues to broaden its range of applications, the increased likelihood of interference introduced by various usage environments can prevent it from achieving its inherent performance. This results in reduced recognition accuracy under certain conditions, and makes the quality control of recognition devices more challenging. Therefore, to ensure that users can properly utilize OCR, we compiled the real-world external disturbance factors that cause performance degradation, along with the resulting image degradation phenomena, into an external disturbance factor table and, by also indicating how to make use of it, organized them into guidelines.
Estimation of Human Condition at Disaster Site Using Aerial Drone Images
Aug 08, 2023

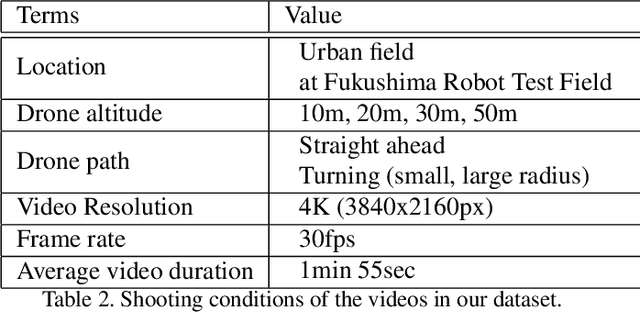
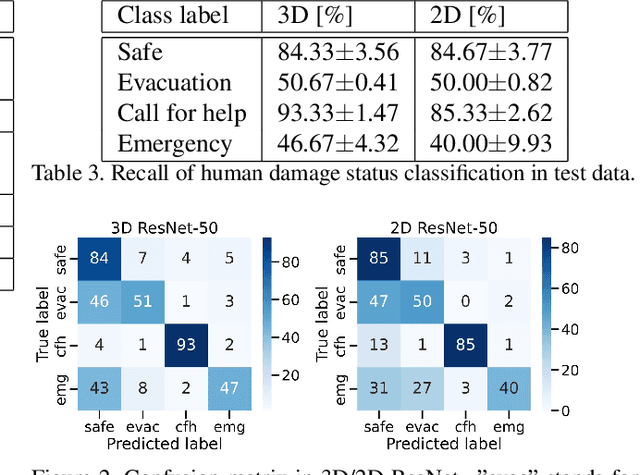
Drones are being used to assess the situation in various disasters. In this study, we investigate a method to automatically estimate the damage status of people based on their actions in aerial drone images in order to understand disaster sites faster and save labor. We constructed a new dataset of aerial images of human actions in a hypothetical disaster that occurred in an urban area, and classified the human damage status using 3D ResNet. The results showed that the status with characteristic human actions could be classified with a recall rate of more than 80%, while other statuses with similar human actions could only be classified with a recall rate of about 50%. In addition, a cloud-based VR presentation application suggested the effectiveness of using drones to understand the disaster site and estimate the human condition.
Describing and Localizing Multiple Changes with Transformers
Mar 25, 2021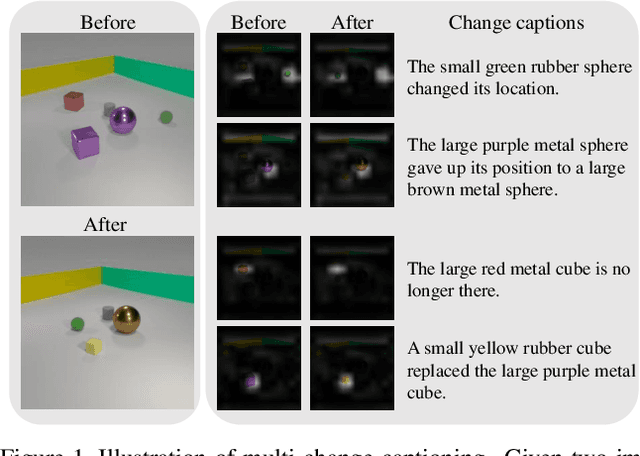
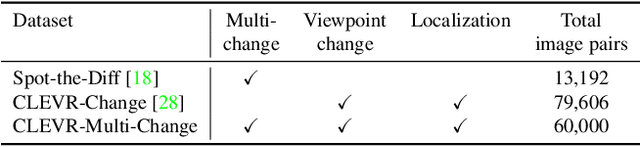


Change captioning tasks aim to detect changes in image pairs observed before and after a scene change and generate a natural language description of the changes. Existing change captioning studies have mainly focused on scenes with a single change. However, detecting and describing multiple changed parts in image pairs is essential for enhancing adaptability to complex scenarios. We solve the above issues from three aspects: (i) We propose a CG-based multi-change captioning dataset; (ii) We benchmark existing state-of-the-art methods of single change captioning on multi-change captioning; (iii) We further propose Multi-Change Captioning transformers (MCCFormers) that identify change regions by densely correlating different regions in image pairs and dynamically determines the related change regions with words in sentences. The proposed method obtained the highest scores on four conventional change captioning evaluation metrics for multi-change captioning. In addition, existing methods generate a single attention map for multiple changes and lack the ability to distinguish change regions. In contrast, our proposed method can separate attention maps for each change and performs well with respect to change localization. Moreover, the proposed framework outperformed the previous state-of-the-art methods on an existing change captioning benchmark, CLEVR-Change, by a large margin (+6.1 on BLEU-4 and +9.7 on CIDEr scores), indicating its general ability in change captioning tasks.
Can Vision Transformers Learn without Natural Images?
Mar 24, 2021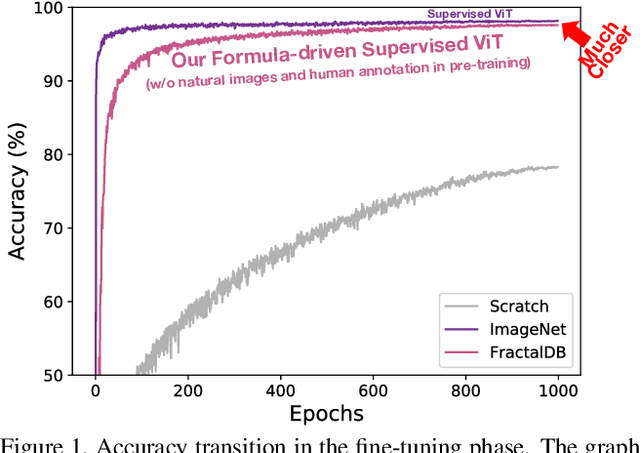
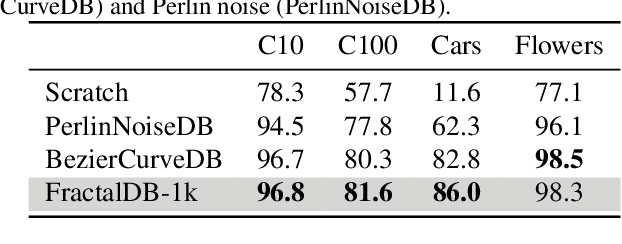
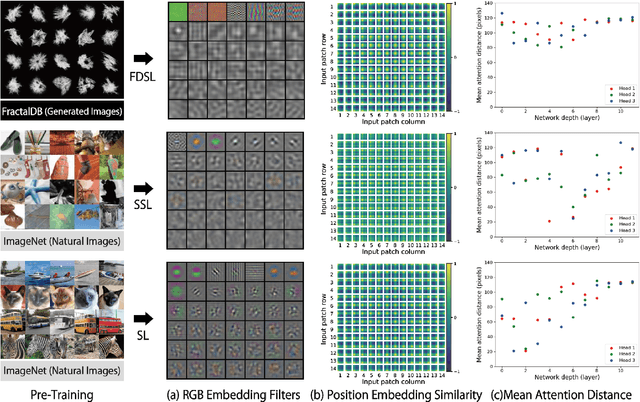
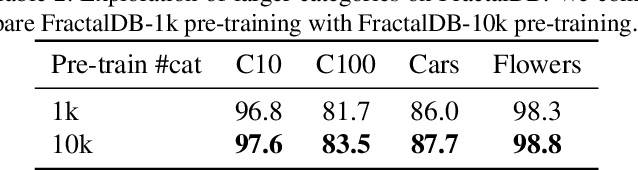
Can we complete pre-training of Vision Transformers (ViT) without natural images and human-annotated labels? Although a pre-trained ViT seems to heavily rely on a large-scale dataset and human-annotated labels, recent large-scale datasets contain several problems in terms of privacy violations, inadequate fairness protection, and labor-intensive annotation. In the present paper, we pre-train ViT without any image collections and annotation labor. We experimentally verify that our proposed framework partially outperforms sophisticated Self-Supervised Learning (SSL) methods like SimCLRv2 and MoCov2 without using any natural images in the pre-training phase. Moreover, although the ViT pre-trained without natural images produces some different visualizations from ImageNet pre-trained ViT, it can interpret natural image datasets to a large extent. For example, the performance rates on the CIFAR-10 dataset are as follows: our proposal 97.6 vs. SimCLRv2 97.4 vs. ImageNet 98.0.
Dominant Codewords Selection with Topic Model for Action Recognition
May 01, 2016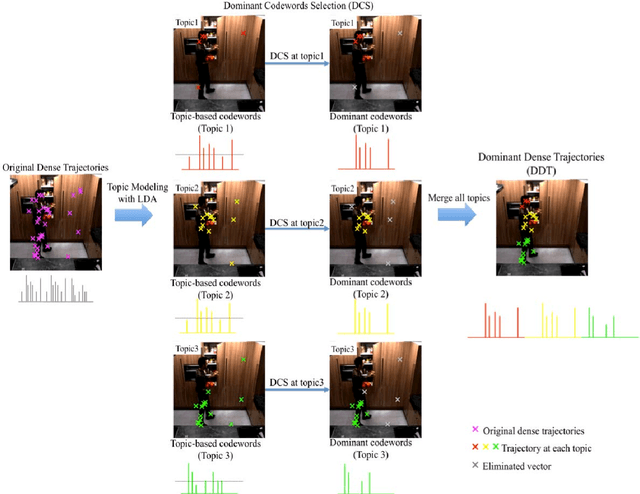
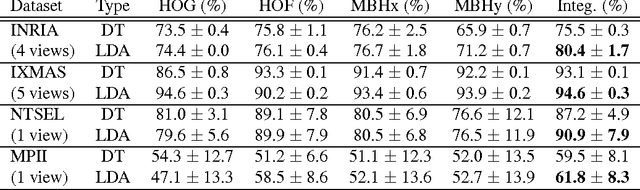

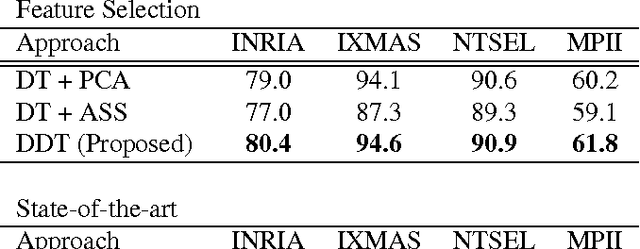
In this paper, we propose a framework for recognizing human activities that uses only in-topic dominant codewords and a mixture of intertopic vectors. Latent Dirichlet allocation (LDA) is used to develop approximations of human motion primitives; these are mid-level representations, and they adaptively integrate dominant vectors when classifying human activities. In LDA topic modeling, action videos (documents) are represented by a bag-of-words (input from a dictionary), and these are based on improved dense trajectories. The output topics correspond to human motion primitives, such as finger moving or subtle leg motion. We eliminate the impurities, such as missed tracking or changing light conditions, in each motion primitive. The assembled vector of motion primitives is an improved representation of the action. We demonstrate our method on four different datasets.
Feature Evaluation of Deep Convolutional Neural Networks for Object Recognition and Detection
Sep 25, 2015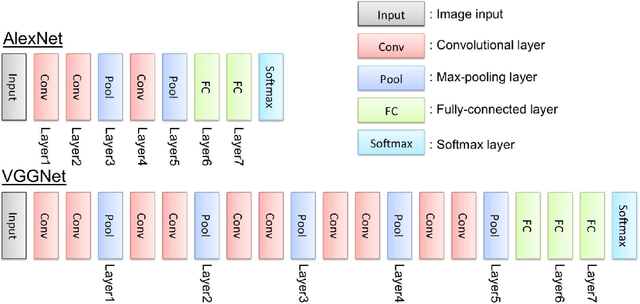

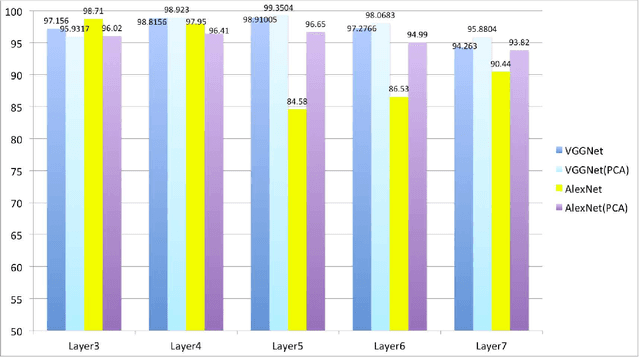

In this paper, we evaluate convolutional neural network (CNN) features using the AlexNet architecture and very deep convolutional network (VGGNet) architecture. To date, most CNN researchers have employed the last layers before output, which were extracted from the fully connected feature layers. However, since it is unlikely that feature representation effectiveness is dependent on the problem, this study evaluates additional convolutional layers that are adjacent to fully connected layers, in addition to executing simple tuning for feature concatenation (e.g., layer 3 + layer 5 + layer 7) and transformation, using tools such as principal component analysis. In our experiments, we carried out detection and classification tasks using the Caltech 101 and Daimler Pedestrian Benchmark Datasets.