 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRAL: Semantic-Aware Progressive LiDAR Scene Generation
May 28, 2025Leveraging recent diffusion models, LiDAR-based large-scale 3D scene generation has achieved great success. While recent voxel-based approaches can generate both geometric structures and semantic labels, existing range-view methods are limited to producing unlabeled LiDAR scenes. Relying on pretrained segmentation models to predict the semantic maps often results in suboptimal cross-modal consistency. To address this limitation while preserving the advantages of range-view representations, such as computational efficiency and simplified network design, we propose Spiral, a novel range-view LiDAR diffusion model that simultaneously generates depth, reflectance images, and semantic maps. Furthermore, we introduce novel semantic-aware metrics to evaluate the quality of the generated labeled range-view data. Experiments on the SemanticKITTI and nuScenes datasets demonstrate that Spiral achieves state-of-the-art performance with the smallest parameter size, outperforming two-step methods that combine the generative and segmentation models. Additionally, we validate that range images generated by Spiral can be effectively used for synthetic data augmentation in the downstream segmentation training, significantly reducing the labeling effort on LiDAR data.
Generative Data Augmentation for Object Point Cloud Segmentation
May 23, 2025Data augmentation is widely used to train deep learning models to address data scarcity. However, traditional data augmentation (TDA) typically relies on simple geometric transformation, such as random rotation and rescaling, resulting in minimal data diversity enrichment and limited model performance improvement. State-of-the-art generative models for 3D shape generation rely on the denoising diffusion probabilistic models and manage to generate realistic novel point clouds for 3D content creation and manipulation. Nevertheless, the generated 3D shapes lack associated point-wise semantic labels, restricting their usage in enlarging the training data for point cloud segmentation tasks. To bridge the gap between data augmentation techniques and the advanced diffusion models, we extend the state-of-the-art 3D diffusion model, Lion, to a part-aware generative model that can generate high-quality point clouds conditioned on given segmentation masks. Leveraging the novel generative model, we introduce a 3-step generative data augmentation (GDA) pipeline for point cloud segmentation training. Our GDA approach requires only a small amount of labeled samples but enriches the training data with generated variants and pseudo-labeled samples, which are validated by a novel diffusion-based pseudo-label filtering method. Extensive experiments on two large-scale synthetic datasets and a real-world medical dataset demonstrate that our GDA method outperforms TDA approach and related semi-supervised and self-supervised methods.
SeaLion: Semantic Part-Aware Latent Point Diffusion Models for 3D Generation
May 23, 2025Denoising diffusion probabilistic models have achieved significant success in point cloud generation, enabling numerous downstream applications, such as generative data augmentation and 3D model editing. However, little attention has been given to generating point clouds with point-wise segmentation labels, as well as to developing evaluation metrics for this task. Therefore, in this paper, we present SeaLion, a novel diffusion model designed to generate high-quality and diverse point clouds with fine-grained segmentation labels. Specifically, we introduce the semantic part-aware latent point diffusion technique, which leverages the intermediate features of the generative models to jointly predict the noise for perturbed latent points and associated part segmentation labels during the denoising process, and subsequently decodes the latent points to point clouds conditioned on part segmentation labels. To effectively evaluate the quality of generated point clouds, we introduce a novel point cloud pairwise distance calculation method named part-aware Chamfer distance (p-CD). This method enables existing metrics, such as 1-NNA, to measure both the local structural quality and inter-part coherence of generated point clouds. Experiments on the large-scale synthetic dataset ShapeNet and real-world medical dataset IntrA demonstrate that SeaLion achieves remarkable performance in generation quality and diversity, outperforming the existing state-of-the-art model, DiffFacto, by 13.33% and 6.52% on 1-NNA (p-CD) across the two datasets. Experimental analysis shows that SeaLion can be trained semi-supervised, thereby reducing the demand for labeling efforts. Lastly, we validate the applicability of SeaLion in generative data augmentation for training segmentation models and the capability of SeaLion to serve as a tool for part-aware 3D shape editing.
CARL: Camera-Agnostic Representation Learning for Spectral Image Analysis
Apr 27, 2025Spectral imaging offers promising applications across diverse domains, including medicine and urban scene understanding, and is already established as a critical modality in remote sensing. However, variability in channel dimensionality and captured wavelengths among spectral cameras impede the development of AI-driven methodologies, leading to camera-specific models with limited generalizability and inadequate cross-camera applicability. To address this bottleneck, we introduce $\textbf{CARL}$, a model for $\textbf{C}$amera-$\textbf{A}$gnostic $\textbf{R}$epresentation $\textbf{L}$earning across RGB, multispectral, and hyperspectral imaging modalities. To enable the conversion of a spectral image with any channel dimensionality to a camera-agnostic embedding, we introduce wavelength positional encoding and a self-attention-cross-attention mechanism to compress spectral information into learned query representations. Spectral-spatial pre-training is achieved with a novel spectral self-supervised JEPA-inspired strategy tailored to CARL. Large-scale experiments across the domains of medical imaging, autonomous driving, and satellite imaging demonstrate our model's unique robustness to spectral heterogeneity, outperforming on datasets with simulated and real-world cross-camera spectral variations. The scalability and versatility of the proposed approach position our model as a backbone for future spectral foundation models.
Deep intra-operative illumination calibration of hyperspectral cameras
Sep 11, 2024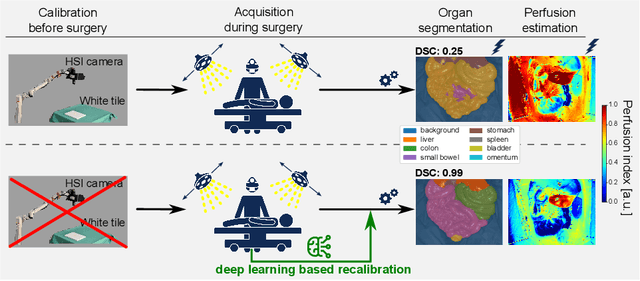
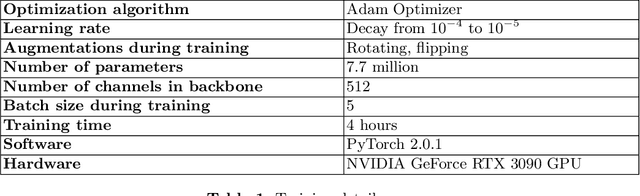

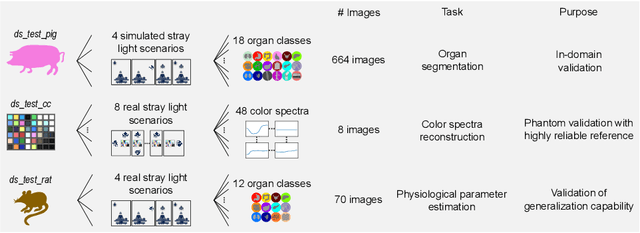
Hyperspectral imaging (HSI) is emerging as a promising novel imaging modality with various potential surgical applications. Currently available cameras, however, suffer from poor integration into the clinical workflow because they require the lights to be switched off, or the camera to be manually recalibrated as soon as lighting conditions change. Given this critical bottleneck, the contribution of this paper is threefold: (1) We demonstrate that dynamically changing lighting conditions in the operating room dramatically affect the performance of HSI applications, namely physiological parameter estimation, and surgical scene segmentation. (2) We propose a novel learning-based approach to automatically recalibrating hyperspectral images during surgery and show that it is sufficiently accurate to replace the tedious process of white reference-based recalibration. (3) Based on a total of 742 HSI cubes from a phantom, porcine models, and rats we show that our recalibration method not only outperforms previously proposed methods, but also generalizes across species, lighting conditions, and image processing tasks. Due to its simple workflow integration as well as high accuracy, speed, and generalization capabilities, our method could evolve as a central component in clinical surgical HSI.
NeRF-Feat: 6D Object Pose Estimation using Feature Rendering
Jun 19, 2024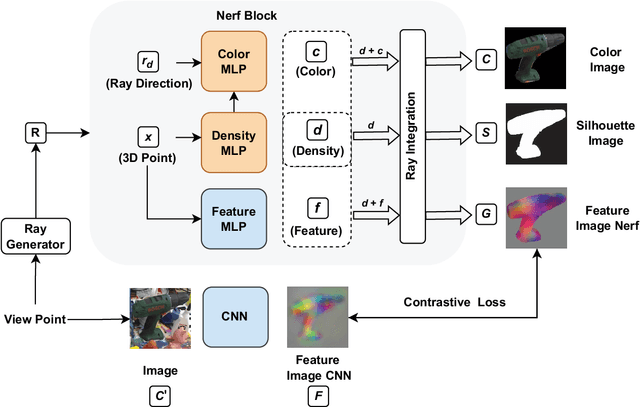


Object Pose Estimation is a crucial component in robotic grasping and augmented reality. Learning based approaches typically require training data from a highly accurate CAD model or labeled training data acquired using a complex setup. We address this by learning to estimate pose from weakly labeled data without a known CAD model. We propose to use a NeRF to learn object shape implicitly which is later used to learn view-invariant features in conjunction with CNN using a contrastive loss. While NeRF helps in learning features that are view-consistent, CNN ensures that the learned features respect symmetry. During inference, CNN is used to predict view-invariant features which can be used to establish correspondences with the implicit 3d model in NeRF. The correspondences are then used to estimate the pose in the reference frame of NeRF. Our approach can also handle symmetric objects unlike other approaches using a similar training setup. Specifically, we learn viewpoint invariant, discriminative features using NeRF which are later used for pose estimation. We evaluated our approach on LM, LM-Occlusion, and T-Less dataset and achieved benchmark accuracy despite using weakly labeled data.
* 3DV 2024
MatchU: Matching Unseen Objects for 6D Pose Estimation from RGB-D Images
Mar 03, 2024



Recent learning methods for object pose estimation require resource-intensive training for each individual object instance or category, hampering their scalability in real applications when confronted with previously unseen objects. In this paper, we propose MatchU, a Fuse-Describe-Match strategy for 6D pose estimation from RGB-D images. MatchU is a generic approach that fuses 2D texture and 3D geometric cues for 6D pose prediction of unseen objects. We rely on learning geometric 3D descriptors that are rotation-invariant by design. By encoding pose-agnostic geometry, the learned descriptors naturally generalize to unseen objects and capture symmetries. To tackle ambiguous associations using 3D geometry only, we fuse additional RGB information into our descriptor. This is achieved through a novel attention-based mechanism that fuses cross-modal information, together with a matching loss that leverages the latent space learned from RGB data to guide the descriptor learning process. Extensive experiments reveal the generalizability of both the RGB-D fusion strategy as well as the descriptor efficacy. Benefiting from the novel designs, MatchU surpasses all existing methods by a significant margin in terms of both accuracy and speed, even without the requirement of expensive re-training or rendering.
GeoTransformer: Fast and Robust Point Cloud Registration with Geometric Transformer
Jul 25, 2023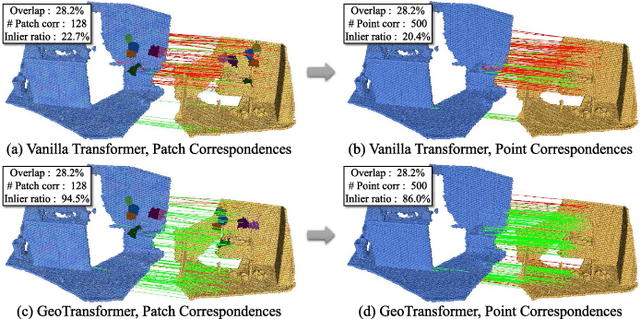
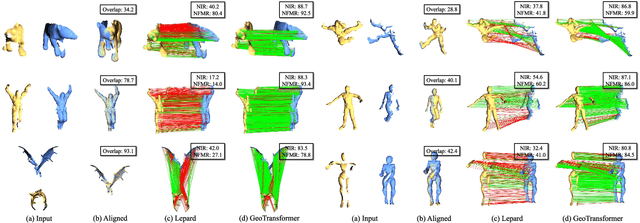
We study the problem of extracting accurate correspondences for point cloud registration. Recent keypoint-free methods have shown great potential through bypassing the detection of repeatable keypoints which is difficult to do especially in low-overlap scenarios. They seek correspondences over downsampled superpoints, which are then propagated to dense points. Superpoints are matched based on whether their neighboring patches overlap. Such sparse and loose matching requires contextual features capturing the geometric structure of the point clouds. We propose Geometric Transformer, or GeoTransformer for short, to learn geometric feature for robust superpoint matching. It encodes pair-wise distances and triplet-wise angles, making it invariant to rigid transformation and robust in low-overlap cases. The simplistic design attains surprisingly high matching accuracy such that no RANSAC is required in the estimation of alignment transformation, leading to $100$ times acceleration. Extensive experiments on rich benchmarks encompassing indoor, outdoor, synthetic, multiway and non-rigid demonstrate the efficacy of GeoTransformer. Notably, our method improves the inlier ratio by $18{\sim}31$ percentage points and the registration recall by over $7$ points on the challenging 3DLoMatch benchmark. Our code and models are available at \url{https://github.com/qinzheng93/GeoTransformer}.
On the Importance of Accurate Geometry Data for Dense 3D Vision Tasks
Mar 26, 2023



Learning-based methods to solve dense 3D vision problems typically train on 3D sensor data. The respectively used principle of measuring distances provides advantages and drawbacks. These are typically not compared nor discussed in the literature due to a lack of multi-modal datasets. Texture-less regions are problematic for structure from motion and stereo, reflective material poses issues for active sensing, and distances for translucent objects are intricate to measure with existing hardware. Training on inaccurate or corrupt data induces model bias and hampers generalisation capabilities. These effects remain unnoticed if the sensor measurement is considered as ground truth during the evaluation. This paper investigates the effect of sensor errors for the dense 3D vision tasks of depth estimation and reconstruction. We rigorously show the significant impact of sensor characteristics on the learned predictions and notice generalisation issues arising from various technologies in everyday household environments. For evaluation, we introduce a carefully designed dataset\footnote{dataset available at https://github.com/Junggy/HAMMER-dataset} comprising measurements from commodity sensors, namely D-ToF, I-ToF, passive/active stereo, and monocular RGB+P. Our study quantifies the considerable sensor noise impact and paves the way to improved dense vision estimates and targeted data fusion.
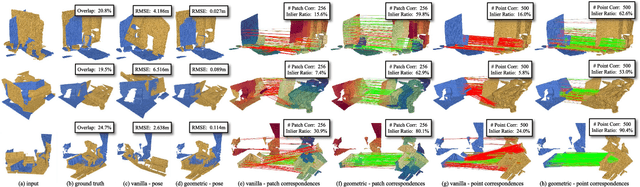
Rotation-Invariant Transformer for Point Cloud Matching
Mar 25, 2023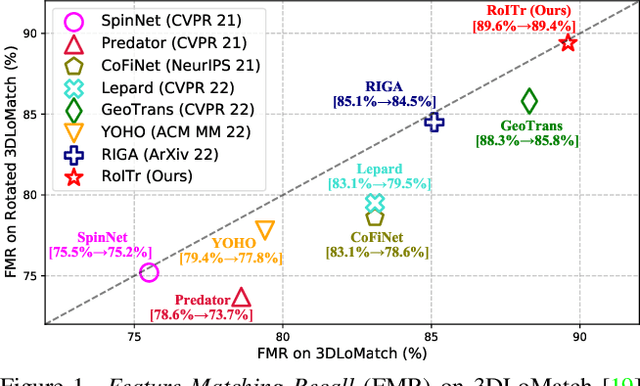
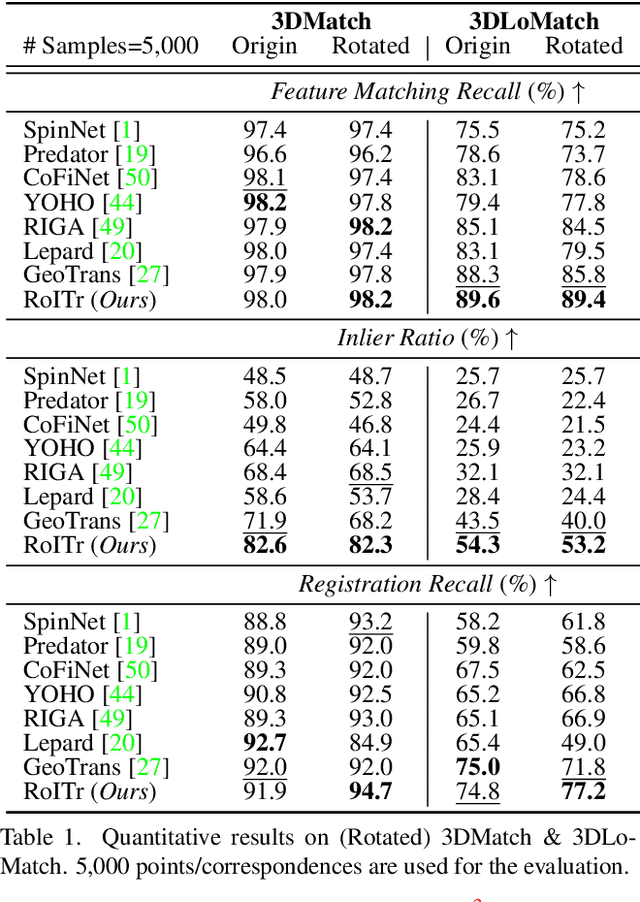
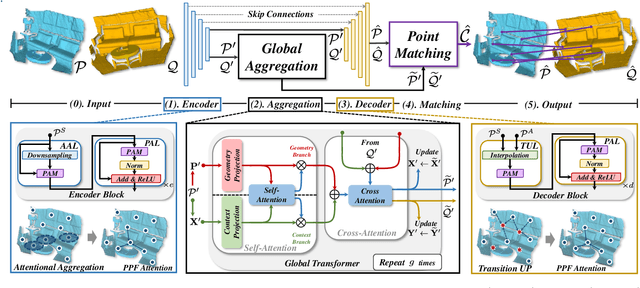
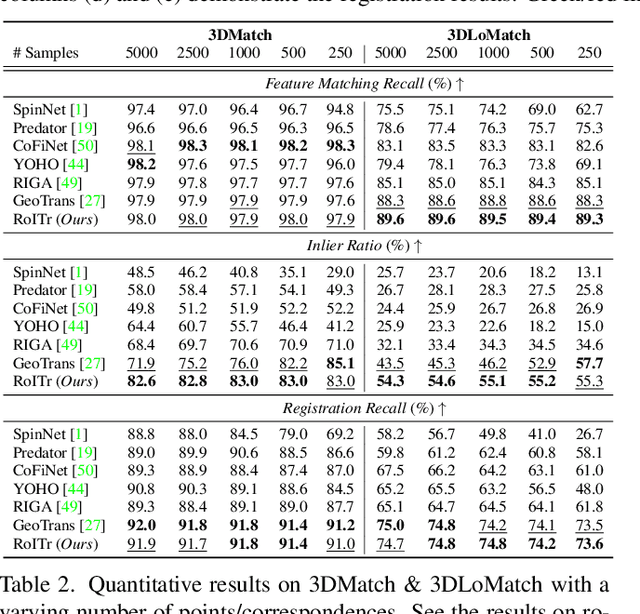
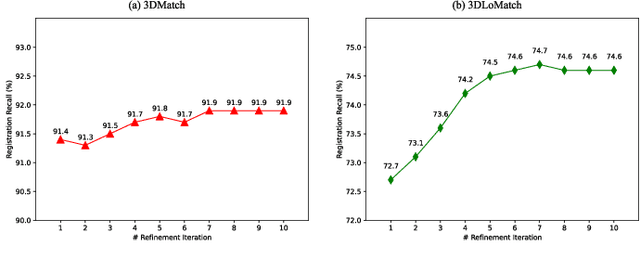
The intrinsic rotation invariance lies at the core of matching point clouds with handcrafted descriptors. However, it is widely despised by recent deep matchers that obtain the rotation invariance extrinsically via data augmentation. As the finite number of augmented rotations can never span the continuous SO(3) space, these methods usually show instability when facing rotations that are rarely seen. To this end, we introduce RoITr, a Rotation-Invariant Transformer to cope with the pose variations in the point cloud matching task. We contribute both on the local and global levels. Starting from the local level, we introduce an attention mechanism embedded with Point Pair Feature (PPF)-based coordinates to describe the pose-invariant geometry, upon which a novel attention-based encoder-decoder architecture is constructed. We further propose a global transformer with rotation-invariant cross-frame spatial awareness learned by the self-attention mechanism, which significantly improves the feature distinctiveness and makes the model robust with respect to the low overlap. Experiments are conducted on both the rigid and non-rigid public benchmarks, where RoITr outperforms all the state-of-the-art models by a considerable margin in the low-overlapping scenarios. Especially when the rotations are enlarged on the challenging 3DLoMatch benchmark, RoITr surpasses the existing methods by at least 13 and 5 percentage points in terms of Inlier Ratio and Registration Recall, respectively.