 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeRF-Feat: 6D Object Pose Estimation using Feature Rendering
Paper and Code
Jun 19, 2024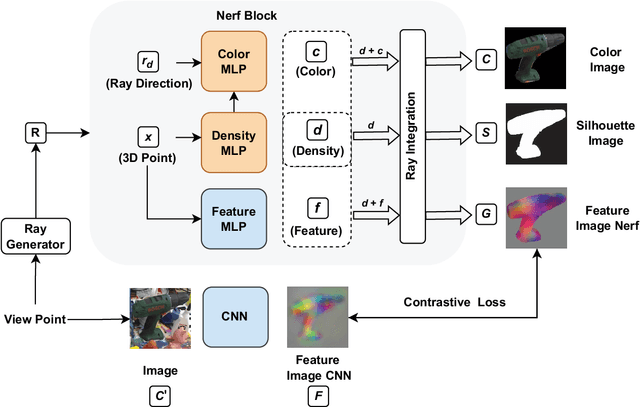

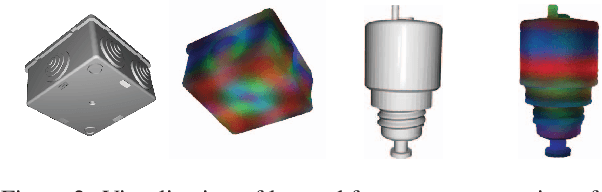

Object Pose Estimation is a crucial component in robotic grasping and augmented reality. Learning based approaches typically require training data from a highly accurate CAD model or labeled training data acquired using a complex setup. We address this by learning to estimate pose from weakly labeled data without a known CAD model. We propose to use a NeRF to learn object shape implicitly which is later used to learn view-invariant features in conjunction with CNN using a contrastive loss. While NeRF helps in learning features that are view-consistent, CNN ensures that the learned features respect symmetry. During inference, CNN is used to predict view-invariant features which can be used to establish correspondences with the implicit 3d model in NeRF. The correspondences are then used to estimate the pose in the reference frame of NeRF. Our approach can also handle symmetric objects unlike other approaches using a similar training setup. Specifically, we learn viewpoint invariant, discriminative features using NeRF which are later used for pose estimation. We evaluated our approach on LM, LM-Occlusion, and T-Less dataset and achieved benchmark accuracy despite using weakly labeled data.