 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSta: Efficient Training Scheme with Siestaed Gaussians for Monocular 3D Scene Reconstruction
Apr 09, 2025



Gaussian Splatting (GS) is a popular approach for 3D reconstruction, mostly due to its ability to converge reasonably fast, faithfully represent the scene and render (novel) views in a fast fashion. However, it suffers from large storage and memory requirements, and its training speed still lags behind the hash-grid based radiance field approaches (e.g. Instant-NGP), which makes it especially difficult to deploy them in robotics scenarios, where 3D reconstruction is crucial for accurate operation. In this paper, we propose GSta that dynamically identifies Gaussians that have converged well during training, based on their positional and color gradient norms. By forcing such Gaussians into a siesta and stopping their updates (freezing) during training, we improve training speed with competitive accuracy compared to state of the art. We also propose an early stopping mechanism based on the PSNR values computed on a subset of training images. Combined with other improvements, such as integrating a learning rate scheduler, GSta achieves an improved Pareto front in convergence speed, memory and storage requirements, while preserving quality. We also show that GSta can improve other methods and complement orthogonal approaches in efficiency improvement; once combined with Trick-GS, GSta achieves up to 5x faster training, 16x smaller disk size compared to vanilla GS, while having comparable accuracy and consuming only half the peak memory. More visualisations are available at https://anilarmagan.github.io/SRUK-GSta.
Trick-GS: A Balanced Bag of Tricks for Efficient Gaussian Splatting
Jan 24, 2025Gaussian splatting (GS) for 3D reconstruction has become quite popular due to their fast training, inference speeds and high quality reconstruction. However, GS-based reconstructions generally consist of millions of Gaussians, which makes them hard to use on computationally constrained devices such as smartphones. In this paper, we first propose a principled analysis of advances in efficient GS methods. Then, we propose Trick-GS, which is a careful combination of several strategies including (1) progressive training with resolution, noise and Gaussian scales, (2) learning to prune and mask primitives and SH bands by their significance, and (3) accelerated GS training framework. Trick-GS takes a large step towards resource-constrained GS, where faster run-time, smaller and faster-convergence of models is of paramount concern. Our results on three datasets show that Trick-GS achieves up to 2x faster training, 40x smaller disk size and 2x faster rendering speed compared to vanilla GS, while having comparable accuracy.
On the Importance of Accurate Geometry Data for Dense 3D Vision Tasks
Mar 26, 2023



Learning-based methods to solve dense 3D vision problems typically train on 3D sensor data. The respectively used principle of measuring distances provides advantages and drawbacks. These are typically not compared nor discussed in the literature due to a lack of multi-modal datasets. Texture-less regions are problematic for structure from motion and stereo, reflective material poses issues for active sensing, and distances for translucent objects are intricate to measure with existing hardware. Training on inaccurate or corrupt data induces model bias and hampers generalisation capabilities. These effects remain unnoticed if the sensor measurement is considered as ground truth during the evaluation. This paper investigates the effect of sensor errors for the dense 3D vision tasks of depth estimation and reconstruction. We rigorously show the significant impact of sensor characteristics on the learned predictions and notice generalisation issues arising from various technologies in everyday household environments. For evaluation, we introduce a carefully designed dataset\footnote{dataset available at https://github.com/Junggy/HAMMER-dataset} comprising measurements from commodity sensors, namely D-ToF, I-ToF, passive/active stereo, and monocular RGB+P. Our study quantifies the considerable sensor noise impact and paves the way to improved dense vision estimates and targeted data fusion.
Is my Depth Ground-Truth Good Enough? HAMMER -- Highly Accurate Multi-Modal Dataset for DEnse 3D Scene Regression
May 09, 2022


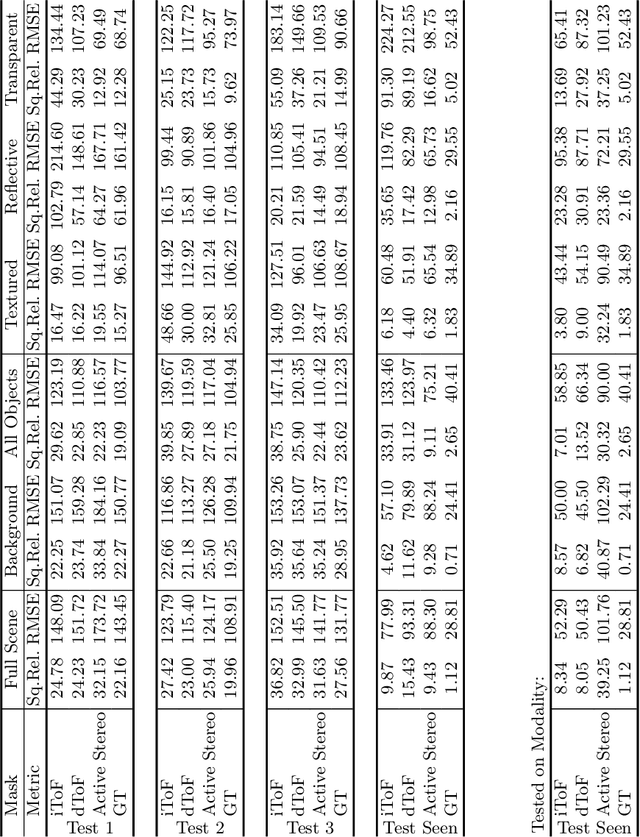
Depth estimation is a core task in 3D computer vision. Recent methods investigate the task of monocular depth trained with various depth sensor modalities. Every sensor has its advantages and drawbacks caused by the nature of estimates. In the literature, mostly mean average error of the depth is investigated and sensor capabilities are typically not discussed. Especially indoor environments, however, pose challenges for some devices. Textureless regions pose challenges for structure from motion, reflective materials are problematic for active sensing, and distances for translucent material are intricate to measure with existing sensors. This paper proposes HAMMER, a dataset comprising depth estimates from multiple commonly used sensors for indoor depth estimation, namely ToF, stereo, structured light together with monocular RGB+P data. We construct highly reliable ground truth depth maps with the help of 3D scanners and aligned renderings. A popular depth estimators is trained on this data and typical depth senosors. The estimates are extensively analyze on different scene structures. We notice generalization issues arising from various sensor technologies in household environments with challenging but everyday scene content. HAMMER, which we make publicly available, provides a reliable base to pave the way to targeted depth improvements and sensor fusion approaches.
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
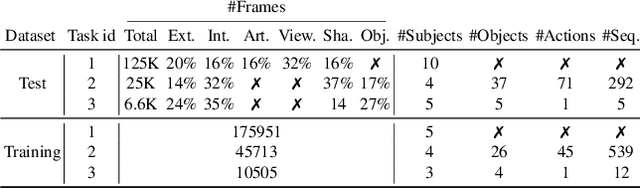
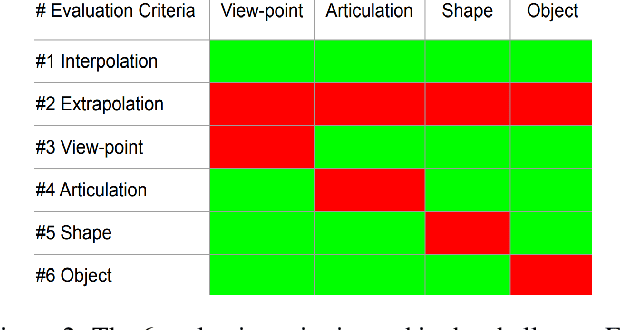
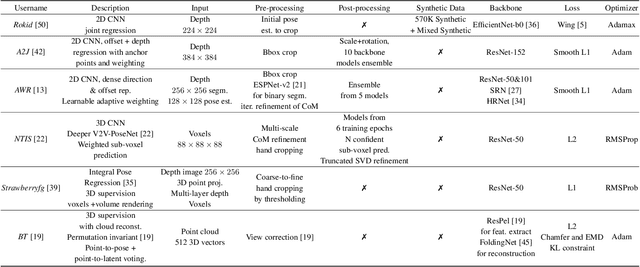
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.
Tackling Two Challenges of 6D Object Pose Estimation: Lack of Real Annotated RGB Images and Scalability to Number of Objects
Mar 27, 2020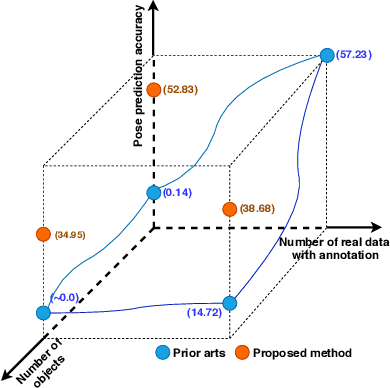
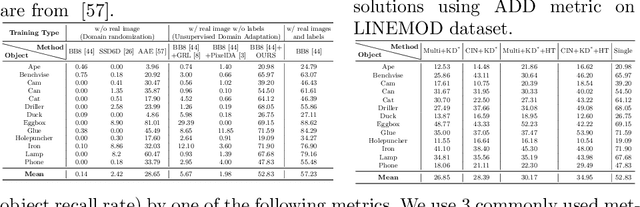
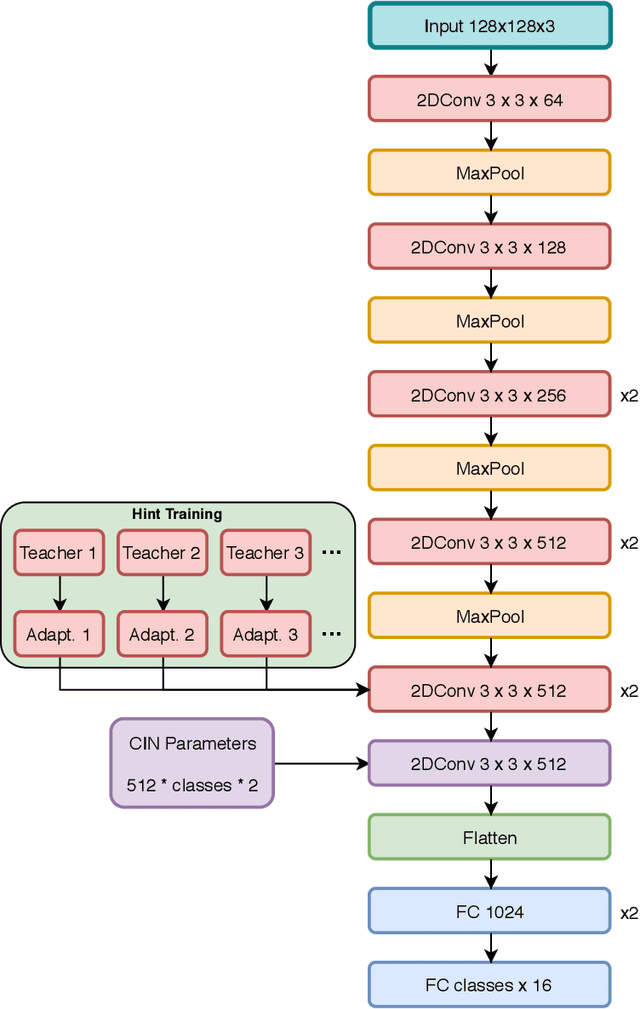
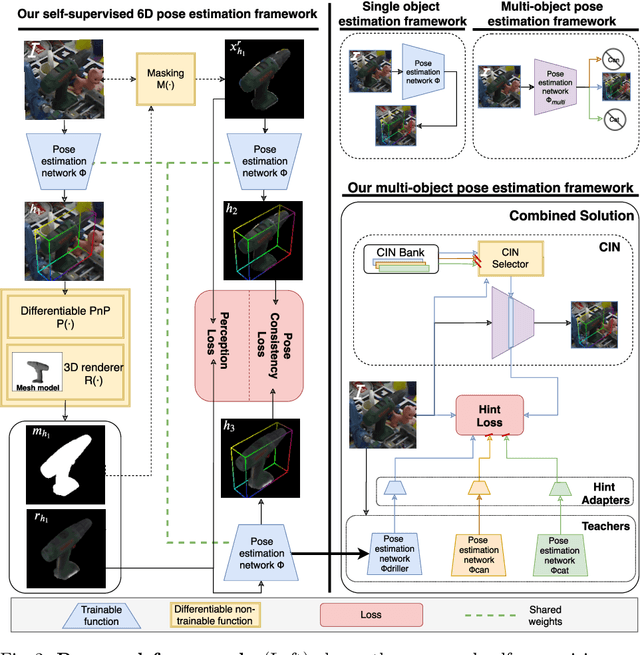
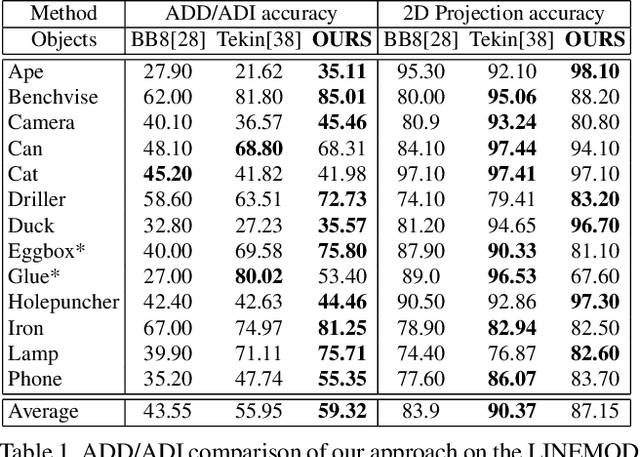
State-of-the-art methods for 6D object pose estimation typically train a Deep Neural Network per object, and its training data first comes from a 3D object mesh. Models trained with synthetic data alone do not generalise well, and training a model for multiple objects sharply drops its accuracy. In this work, we address these two main challenges for 6D object pose estimation and investigate viable methods in experiments. For lack of real RGB data with pose annotations, we propose a novel self-supervision method via pose consistency. For scalability to multiple objects, we apply additional parameterisation to a backbone network and distill knowledge from teachers to a student network for model compression. We further evaluate the combination of the two methods for settings where we are given only synthetic data and a single network for multiple objects. In experiments using LINEMOD, LINEMOD OCCLUSION and T-LESS datasets, the methods significantly boost baseline accuracies and are comparable with the upper bounds, i.e., object specific networks trained on real data with pose labels.
Accurate 6D Object Pose Estimation by Pose Conditioned Mesh Reconstruction
Oct 23, 2019
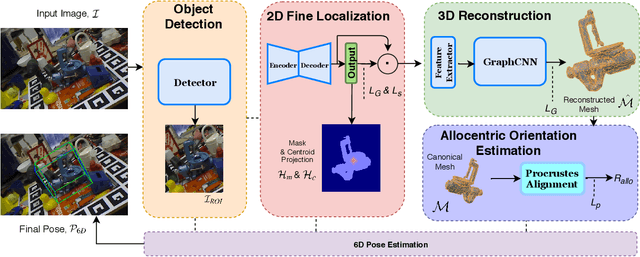

Current 6D object pose methods consist of deep CNN models fully optimized for a single object but with its architecture standardized among objects with different shapes. In contrast to previous works, we explicitly exploit each object's distinct topological information i.e. 3D dense meshes in the pose estimation model, with an automated process and prior to any post-processing refinement stage. In order to achieve this, we propose a learning framework in which a Graph Convolutional Neural Network reconstructs a pose conditioned 3D mesh of the object. A robust estimation of the allocentric orientation is recovered by computing, in a differentiable manner, the Procrustes' alignment between the canonical and reconstructed dense 3D meshes. 6D egocentric pose is then lifted using additional mask and 2D centroid projection estimations. Our method is capable of self validating its pose estimation by measuring the quality of the reconstructed mesh, which is invaluable in real life applications. In our experiments on the LINEMOD, OCCLUSION and YCB-Video benchmarks, the proposed method outperforms state-of-the-arts.
What is usual in unusual videos? Trajectory snippet histograms for discovering unusualness
Nov 02, 2014
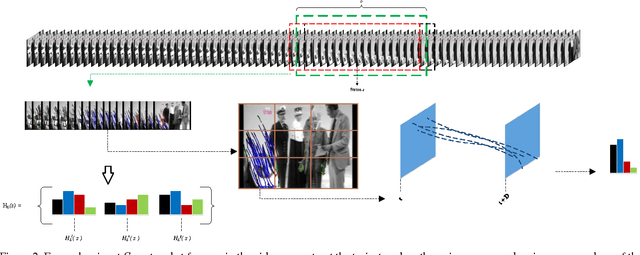
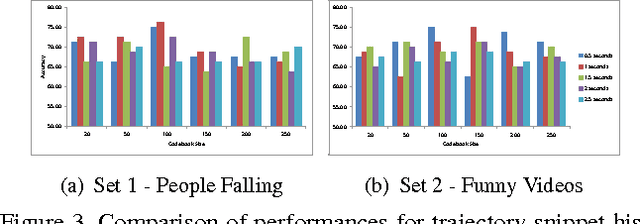
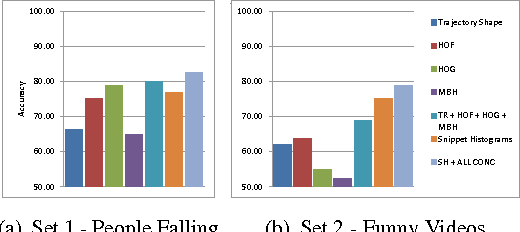
Unusual events are important as being possible indicators of undesired consequences. Moreover, unusualness in everyday life activities may also be amusing to watch as proven by the popularity of such videos shared in social media. Discovery of unusual events in videos is generally attacked as a problem of finding usual patterns, and then separating the ones that do not resemble to those. In this study, we address the problem from the other side, and try to answer what type of patterns are shared among unusual videos that make them resemble to each other regardless of the ongoing event. With this challenging problem at hand, we propose a novel descriptor to encode the rapid motions in videos utilizing densely extracted trajectories. The proposed descriptor, which is referred to as trajectory snipped histograms, is used to distinguish unusual videos from usual videos, and further exploited to discover snapshots in which unusualness happen. Experiments on domain specific people falling videos and unrestricted funny videos show the effectiveness of our method in capturing unusualness.