 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI4EOSC: a Federated Cloud Platform for Artificial Intelligence in Scientific Research
Dec 18, 2025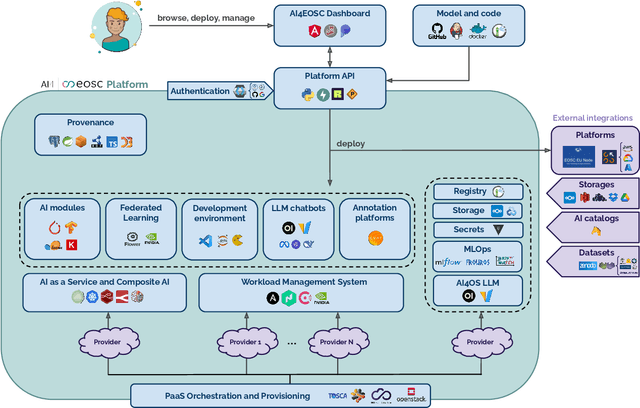
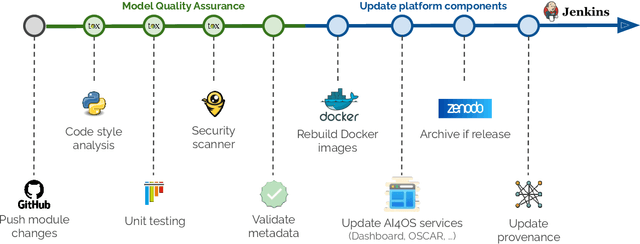
In this paper, we describe a federated compute platform dedicated to support Artificial Intelligence in scientific workloads. Putting the effort into reproducible deployments, it delivers consistent, transparent access to a federation of physically distributed e-Infrastructures. Through a comprehensive service catalogue, the platform is able to offer an integrated user experience covering the full Machine Learning lifecycle, including model development (with dedicated interactive development environments), training (with GPU resources, annotation tools, experiment tracking, and federated learning support) and deployment (covering a wide range of deployment options all along the Cloud Continuum). The platform also provides tools for traceability and reproducibility of AI models, integrates with different Artificial Intelligence model providers, datasets and storage resources, allowing users to interact with the broader Machine Learning ecosystem. Finally, it is easily customizable to lower the adoption barrier by external communities.
Towards a Spatiotemporal Fusion Approach to Precipitation Nowcasting
May 25, 2025



With the increasing availability of meteorological data from various sensors, numerical models and reanalysis products, the need for efficient data integration methods has become paramount for improving weather forecasts and hydrometeorological studies. In this work, we propose a data fusion approach for precipitation nowcasting by integrating data from meteorological and rain gauge stations in Rio de Janeiro metropolitan area with ERA5 reanalysis data and GFS numerical weather prediction. We employ the spatiotemporal deep learning architecture called STConvS2S, leveraging a structured dataset covering a 9 x 11 grid. The study spans from January 2011 to October 2024, and we evaluate the impact of integrating three surface station systems. Among the tested configurations, the fusion-based model achieves an F1-score of 0.2033 for forecasting heavy precipitation events (greater than 25 mm/h) at a one-hour lead time. Additionally, we present an ablation study to assess the contribution of each station network and propose a refined inference strategy for precipitation nowcasting, integrating the GFS numerical weather prediction (NWP) data with in-situ observations.
PoseMatcher: One-shot 6D Object Pose Estimation by Deep Feature Matching
Apr 03, 2023Estimating the pose of an unseen object is the goal of the challenging one-shot pose estimation task. Previous methods have heavily relied on feature matching with great success. However, these methods are often inefficient and limited by their reliance on pre-trained models that have not be designed specifically for pose estimation. In this paper we propose PoseMatcher, an accurate model free one-shot object pose estimator that overcomes these limitations. We create a new training pipeline for object to image matching based on a three-view system: a query with a positive and negative templates. This simple yet effective approach emulates test time scenarios by cheaply constructing an approximation of the full object point cloud during training. To enable PoseMatcher to attend to distinct input modalities, an image and a pointcloud, we introduce IO-Layer, a new attention layer that efficiently accommodates self and cross attention between the inputs. Moreover, we propose a pruning strategy where we iteratively remove redundant regions of the target object to further reduce the complexity and noise of the network while maintaining accuracy. Finally we redesign commonly used pose refinement strategies, zoom and 2D offset refinements, and adapt them to the one-shot paradigm. We outperform all prior one-shot pose estimation methods on the Linemod and YCB-V datasets as well achieve results rivaling recent instance-level methods. The source code and models are available at https://github.com/PedroCastro/PoseMatcher.
Tackling Two Challenges of 6D Object Pose Estimation: Lack of Real Annotated RGB Images and Scalability to Number of Objects
Mar 27, 2020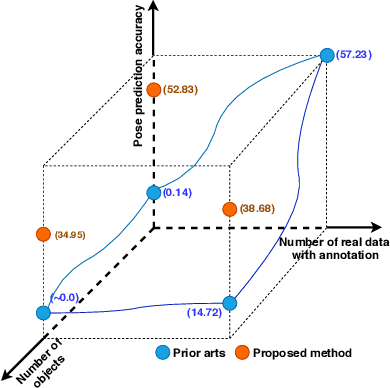
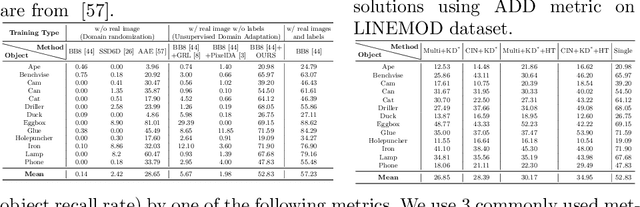
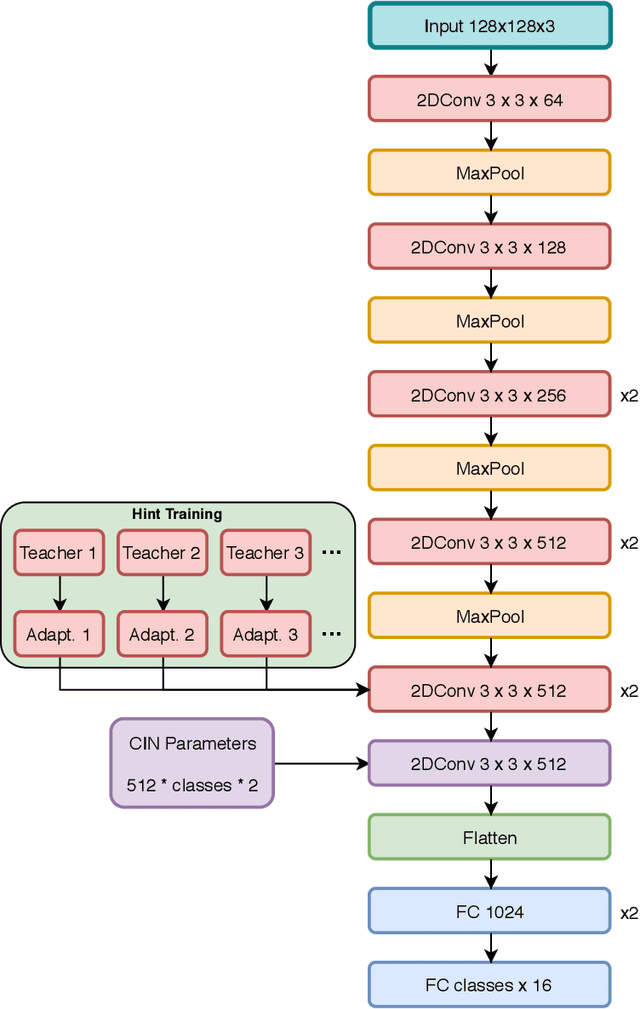
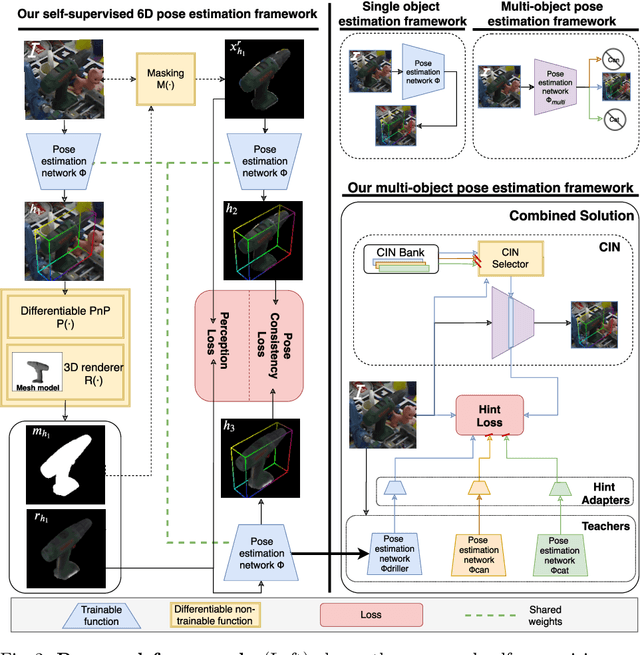
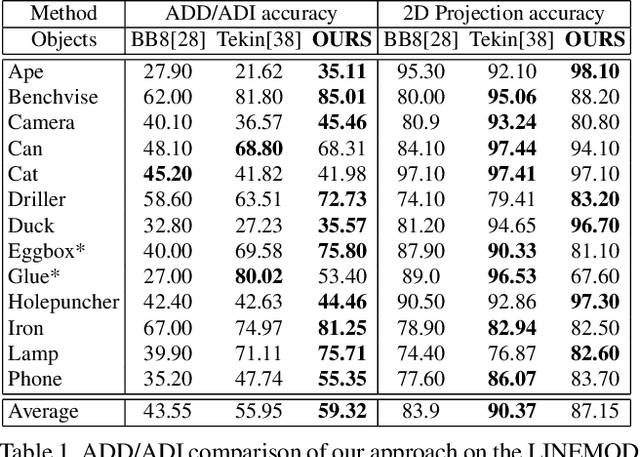
State-of-the-art methods for 6D object pose estimation typically train a Deep Neural Network per object, and its training data first comes from a 3D object mesh. Models trained with synthetic data alone do not generalise well, and training a model for multiple objects sharply drops its accuracy. In this work, we address these two main challenges for 6D object pose estimation and investigate viable methods in experiments. For lack of real RGB data with pose annotations, we propose a novel self-supervision method via pose consistency. For scalability to multiple objects, we apply additional parameterisation to a backbone network and distill knowledge from teachers to a student network for model compression. We further evaluate the combination of the two methods for settings where we are given only synthetic data and a single network for multiple objects. In experiments using LINEMOD, LINEMOD OCCLUSION and T-LESS datasets, the methods significantly boost baseline accuracies and are comparable with the upper bounds, i.e., object specific networks trained on real data with pose labels.
Accurate 6D Object Pose Estimation by Pose Conditioned Mesh Reconstruction
Oct 23, 2019
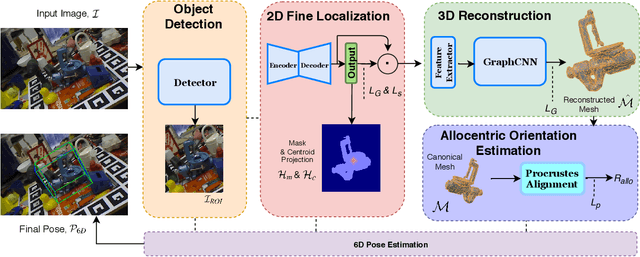

Current 6D object pose methods consist of deep CNN models fully optimized for a single object but with its architecture standardized among objects with different shapes. In contrast to previous works, we explicitly exploit each object's distinct topological information i.e. 3D dense meshes in the pose estimation model, with an automated process and prior to any post-processing refinement stage. In order to achieve this, we propose a learning framework in which a Graph Convolutional Neural Network reconstructs a pose conditioned 3D mesh of the object. A robust estimation of the allocentric orientation is recovered by computing, in a differentiable manner, the Procrustes' alignment between the canonical and reconstructed dense 3D meshes. 6D egocentric pose is then lifted using additional mask and 2D centroid projection estimations. Our method is capable of self validating its pose estimation by measuring the quality of the reconstructed mesh, which is invaluable in real life applications. In our experiments on the LINEMOD, OCCLUSION and YCB-Video benchmarks, the proposed method outperforms state-of-the-arts.