 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate 6D Object Pose Estimation by Pose Conditioned Mesh Reconstruction
Paper and Code
Oct 23, 2019
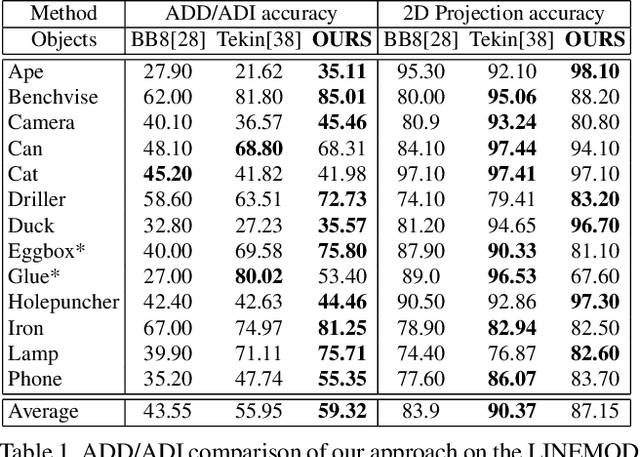
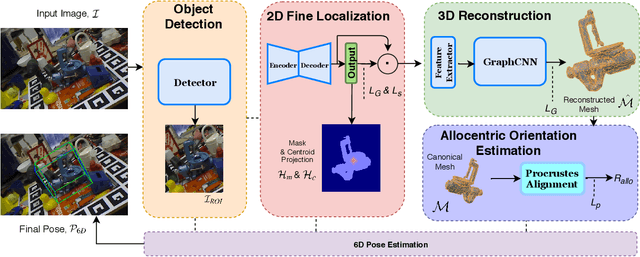

Current 6D object pose methods consist of deep CNN models fully optimized for a single object but with its architecture standardized among objects with different shapes. In contrast to previous works, we explicitly exploit each object's distinct topological information i.e. 3D dense meshes in the pose estimation model, with an automated process and prior to any post-processing refinement stage. In order to achieve this, we propose a learning framework in which a Graph Convolutional Neural Network reconstructs a pose conditioned 3D mesh of the object. A robust estimation of the allocentric orientation is recovered by computing, in a differentiable manner, the Procrustes' alignment between the canonical and reconstructed dense 3D meshes. 6D egocentric pose is then lifted using additional mask and 2D centroid projection estimations. Our method is capable of self validating its pose estimation by measuring the quality of the reconstructed mesh, which is invaluable in real life applications. In our experiments on the LINEMOD, OCCLUSION and YCB-Video benchmarks, the proposed method outperforms state-of-the-arts.