 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSta: Efficient Training Scheme with Siestaed Gaussians for Monocular 3D Scene Reconstruction
Apr 09, 2025



Gaussian Splatting (GS) is a popular approach for 3D reconstruction, mostly due to its ability to converge reasonably fast, faithfully represent the scene and render (novel) views in a fast fashion. However, it suffers from large storage and memory requirements, and its training speed still lags behind the hash-grid based radiance field approaches (e.g. Instant-NGP), which makes it especially difficult to deploy them in robotics scenarios, where 3D reconstruction is crucial for accurate operation. In this paper, we propose GSta that dynamically identifies Gaussians that have converged well during training, based on their positional and color gradient norms. By forcing such Gaussians into a siesta and stopping their updates (freezing) during training, we improve training speed with competitive accuracy compared to state of the art. We also propose an early stopping mechanism based on the PSNR values computed on a subset of training images. Combined with other improvements, such as integrating a learning rate scheduler, GSta achieves an improved Pareto front in convergence speed, memory and storage requirements, while preserving quality. We also show that GSta can improve other methods and complement orthogonal approaches in efficiency improvement; once combined with Trick-GS, GSta achieves up to 5x faster training, 16x smaller disk size compared to vanilla GS, while having comparable accuracy and consuming only half the peak memory. More visualisations are available at https://anilarmagan.github.io/SRUK-GSta.
LP-IOANet: Efficient High Resolution Document Shadow Removal
Mar 22, 2023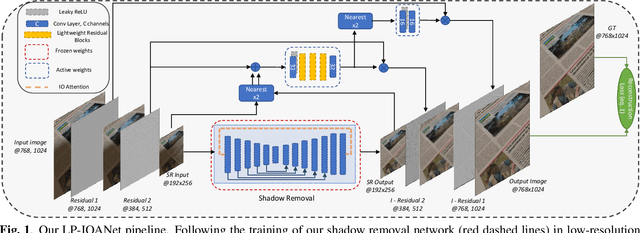

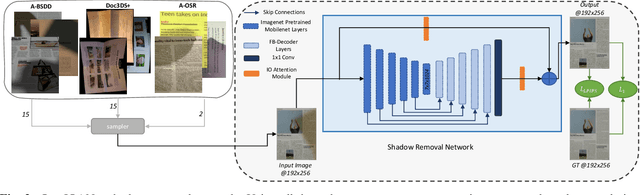

Document shadow removal is an integral task in document enhancement pipelines, as it improves visibility, readability and thus the overall quality. Assuming that the majority of practical document shadow removal scenarios require real-time, accurate models that can produce high-resolution outputs in-the-wild, we propose Laplacian Pyramid with Input/Output Attention Network (LP-IOANet), a novel pipeline with a lightweight architecture and an upsampling module. Furthermore, we propose three new datasets which cover a wide range of lighting conditions, images, shadow shapes and viewpoints. Our results show that we outperform the state-of-the-art by a 35% relative improvement in mean average error (MAE), while running real-time in four times the resolution (of the state-of-the-art method) on a mobile device.