 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheapNVS: Real-Time On-Device Narrow-Baseline Novel View Synthesis
Jan 24, 2025



Single-view novel view synthesis (NVS) is a notorious problem due to its ill-posed nature, and often requires large, computationally expensive approaches to produce tangible results. In this paper, we propose CheapNVS: a fully end-to-end approach for narrow baseline single-view NVS based on a novel, efficient multiple encoder/decoder design trained in a multi-stage fashion. CheapNVS first approximates the laborious 3D image warping with lightweight learnable modules that are conditioned on the camera pose embeddings of the target view, and then performs inpainting on the occluded regions in parallel to achieve significant performance gains. Once trained on a subset of Open Images dataset, CheapNVS outperforms the state-of-the-art despite being 10 times faster and consuming 6% less memory. Furthermore, CheapNVS runs comfortably in real-time on mobile devices, reaching over 30 FPS on a Samsung Tab 9+.
Rethinking Encoder-Decoder Flow Through Shared Structures
Jan 24, 2025



Dense prediction tasks have enjoyed a growing complexity of encoder architectures, decoders, however, have remained largely the same. They rely on individual blocks decoding intermediate feature maps sequentially. We introduce banks, shared structures that are used by each decoding block to provide additional context in the decoding process. These structures, through applying them via resampling and feature fusion, improve performance on depth estimation for state-of-the-art transformer-based architectures on natural and synthetic images whilst training on large-scale datasets.
TrickVOS: A Bag of Tricks for Video Object Segmentation
Jun 28, 2023



Space-time memory (STM) network methods have been dominant in semi-supervised video object segmentation (SVOS) due to their remarkable performance. In this work, we identify three key aspects where we can improve such methods; i) supervisory signal, ii) pretraining and iii) spatial awareness. We then propose TrickVOS; a generic, method-agnostic bag of tricks addressing each aspect with i) a structure-aware hybrid loss, ii) a simple decoder pretraining regime and iii) a cheap tracker that imposes spatial constraints in model predictions. Finally, we propose a lightweight network and show that when trained with TrickVOS, it achieves competitive results to state-of-the-art methods on DAVIS and YouTube benchmarks, while being one of the first STM-based SVOS methods that can run in real-time on a mobile device.
LP-IOANet: Efficient High Resolution Document Shadow Removal
Mar 22, 2023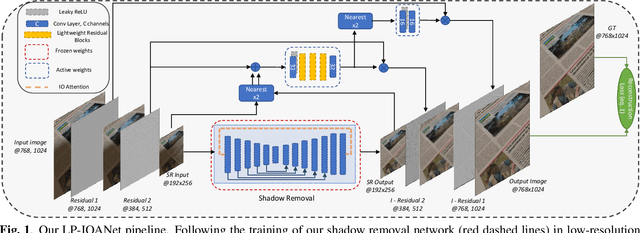

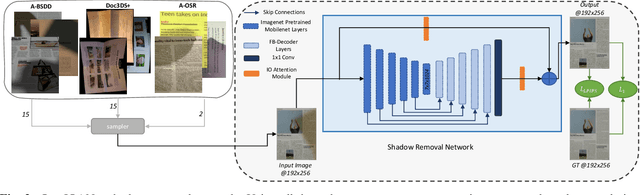

Document shadow removal is an integral task in document enhancement pipelines, as it improves visibility, readability and thus the overall quality. Assuming that the majority of practical document shadow removal scenarios require real-time, accurate models that can produce high-resolution outputs in-the-wild, we propose Laplacian Pyramid with Input/Output Attention Network (LP-IOANet), a novel pipeline with a lightweight architecture and an upsampling module. Furthermore, we propose three new datasets which cover a wide range of lighting conditions, images, shadow shapes and viewpoints. Our results show that we outperform the state-of-the-art by a 35% relative improvement in mean average error (MAE), while running real-time in four times the resolution (of the state-of-the-art method) on a mobile device.
MobileVOS: Real-Time Video Object Segmentation Contrastive Learning meets Knowledge Distillation
Mar 14, 2023This paper tackles the problem of semi-supervised video object segmentation on resource-constrained devices, such as mobile phones. We formulate this problem as a distillation task, whereby we demonstrate that small space-time-memory networks with finite memory can achieve competitive results with state of the art, but at a fraction of the computational cost (32 milliseconds per frame on a Samsung Galaxy S22). Specifically, we provide a theoretically grounded framework that unifies knowledge distillation with supervised contrastive representation learning. These models are able to jointly benefit from both pixel-wise contrastive learning and distillation from a pre-trained teacher. We validate this loss by achieving competitive J&F to state of the art on both the standard DAVIS and YouTube benchmarks, despite running up to 5x faster, and with 32x fewer parameters.