 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSATGround: A Spatially-Aware Approach for Visual Grounding in Remote Sensing
Dec 09, 2025Vision-language models (VLMs) are emerging as powerful generalist tools for remote sensing, capable of integrating information across diverse tasks and enabling flexible, instruction-based interactions via a chat interface. In this work, we enhance VLM-based visual grounding in satellite imagery by proposing a novel structured localization mechanism. Our approach involves finetuning a pretrained VLM on a diverse set of instruction-following tasks, while interfacing a dedicated grounding module through specialized control tokens for localization. This method facilitates joint reasoning over both language and spatial information, significantly enhancing the model's ability to precisely localize objects in complex satellite scenes. We evaluate our framework on several remote sensing benchmarks, consistently improving the state-of-the-art, including a 24.8% relative improvement over previous methods on visual grounding. Our results highlight the benefits of integrating structured spatial reasoning into VLMs, paving the way for more reliable real-world satellite data analysis.
RetouchLLM: Training-free White-box Image Retouching
Oct 09, 2025Image retouching not only enhances visual quality but also serves as a means of expressing personal preferences and emotions. However, existing learning-based approaches require large-scale paired data and operate as black boxes, making the retouching process opaque and limiting their adaptability to handle diverse, user- or image-specific adjustments. In this work, we propose RetouchLLM, a training-free white-box image retouching system, which requires no training data and performs interpretable, code-based retouching directly on high-resolution images. Our framework progressively enhances the image in a manner similar to how humans perform multi-step retouching, allowing exploration of diverse adjustment paths. It comprises of two main modules: a visual critic that identifies differences between the input and reference images, and a code generator that produces executable codes. Experiments demonstrate that our approach generalizes well across diverse retouching styles, while natural language-based user interaction enables interpretable and controllable adjustments tailored to user intent.
Region-based Cluster Discrimination for Visual Representation Learning
Jul 26, 2025Learning visual representations is foundational for a broad spectrum of downstream tasks. Although recent vision-language contrastive models, such as CLIP and SigLIP, have achieved impressive zero-shot performance via large-scale vision-language alignment, their reliance on global representations constrains their effectiveness for dense prediction tasks, such as grounding, OCR, and segmentation. To address this gap, we introduce Region-Aware Cluster Discrimination (RICE), a novel method that enhances region-level visual and OCR capabilities. We first construct a billion-scale candidate region dataset and propose a Region Transformer layer to extract rich regional semantics. We further design a unified region cluster discrimination loss that jointly supports object and OCR learning within a single classification framework, enabling efficient and scalable distributed training on large-scale data. Extensive experiments show that RICE consistently outperforms previous methods on tasks, including segmentation, dense detection, and visual perception for Multimodal Large Language Models (MLLMs). The pre-trained models have been released at https://github.com/deepglint/MVT.
VeLoRA: Memory Efficient Training using Rank-1 Sub-Token Projections
May 28, 2024



Large language models (LLMs) have recently emerged as powerful tools for tackling many language-processing tasks. Despite their success, training and fine-tuning these models is still far too computationally and memory intensive. In this paper, we identify and characterise the important components needed for effective model convergence using gradient descent. In doing so we find that the intermediate activations used to implement backpropagation can be excessively compressed without incurring any degradation in performance. This result leads us to a cheap and memory-efficient algorithm for both fine-tuning and pre-training LLMs. The proposed algorithm simply divides the tokens up into smaller sub-tokens before projecting them onto a fixed 1-dimensional subspace during the forward pass. These features are then coarsely reconstructed during the backward pass to implement the update rules. We confirm the effectiveness of our algorithm as being complimentary to many state-of-the-art PEFT methods on the VTAB-1k fine-tuning benchmark. Furthermore, we outperform QLoRA for fine-tuning LLaMA and show competitive performance against other memory-efficient pre-training methods on the large-scale C4 dataset.
Learning to Project for Cross-Task Knowledge Distillation
Mar 21, 2024
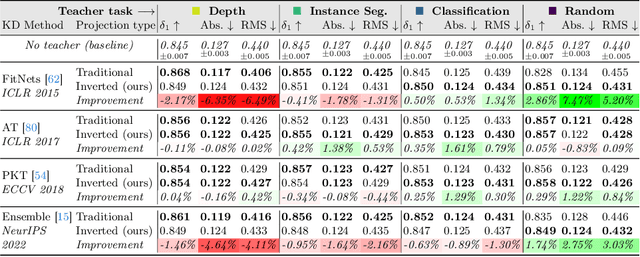
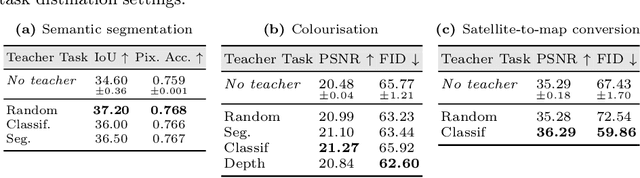
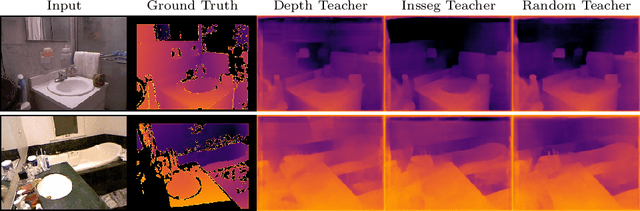
Traditional knowledge distillation (KD) relies on a proficient teacher trained on the target task, which is not always available. In this setting, cross-task distillation can be used, enabling the use of any teacher model trained on a different task. However, many KD methods prove ineffective when applied to this cross-task setting. To address this limitation, we propose a simple modification: the use of an inverted projection. We show that this drop-in replacement for a standard projector is effective by learning to disregard any task-specific features which might degrade the student's performance. We find that this simple modification is sufficient for extending many KD methods to the cross-task setting, where the teacher and student tasks can be very different. In doing so, we obtain up to a 1.9% improvement in the cross-task setting compared to the traditional projection, at no additional cost. Our method can obtain significant performance improvements (up to 7%) when using even a randomly-initialised teacher on various tasks such as depth estimation, image translation, and semantic segmentation, despite the lack of any learned knowledge to transfer. To provide conceptual and analytical insights into this result, we show that using an inverted projection allows the distillation loss to be decomposed into a knowledge transfer and a spectral regularisation component. Through this analysis we are additionally able to propose a novel regularisation loss that allows teacher-free distillation, enabling performance improvements of up to 8.57% on ImageNet with no additional training costs.
$V_kD:$ Improving Knowledge Distillation using Orthogonal Projections
Mar 10, 2024



Knowledge distillation is an effective method for training small and efficient deep learning models. However, the efficacy of a single method can degenerate when transferring to other tasks, modalities, or even other architectures. To address this limitation, we propose a novel constrained feature distillation method. This method is derived from a small set of core principles, which results in two emerging components: an orthogonal projection and a task-specific normalisation. Equipped with both of these components, our transformer models can outperform all previous methods on ImageNet and reach up to a 4.4% relative improvement over the previous state-of-the-art methods. To further demonstrate the generality of our method, we apply it to object detection and image generation, whereby we obtain consistent and substantial performance improvements over state-of-the-art. Code and models are publicly available: https://github.com/roymiles/vkd
A closer look at the training dynamics of knowledge distillation
Mar 20, 2023

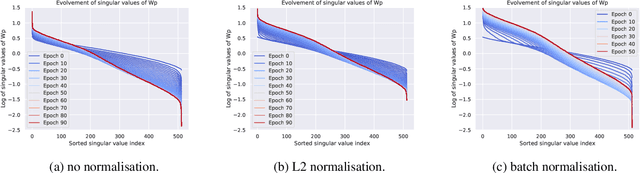

In this paper we revisit the efficacy of knowledge distillation as a function matching and metric learning problem. In doing so we verify three important design decisions, namely the normalisation, soft maximum function, and projection layers as key ingredients. We theoretically show that the projector implicitly encodes information on past examples, enabling relational gradients for the student. We then show that the normalisation of representations is tightly coupled with the training dynamics of this projector, which can have a large impact on the students performance. Finally, we show that a simple soft maximum function can be used to address any significant capacity gap problems. Experimental results on various benchmark datasets demonstrate that using these insights can lead to superior or comparable performance to state-of-the-art knowledge distillation techniques, despite being much more computationally efficient. In particular, we obtain these results across image classification (CIFAR100 and ImageNet), object detection (COCO2017), and on more difficult distillation objectives, such as training data efficient transformers, whereby we attain a 77.2% top-1 accuracy with DeiT-Ti on ImageNet.
MobileVOS: Real-Time Video Object Segmentation Contrastive Learning meets Knowledge Distillation
Mar 14, 2023This paper tackles the problem of semi-supervised video object segmentation on resource-constrained devices, such as mobile phones. We formulate this problem as a distillation task, whereby we demonstrate that small space-time-memory networks with finite memory can achieve competitive results with state of the art, but at a fraction of the computational cost (32 milliseconds per frame on a Samsung Galaxy S22). Specifically, we provide a theoretically grounded framework that unifies knowledge distillation with supervised contrastive representation learning. These models are able to jointly benefit from both pixel-wise contrastive learning and distillation from a pre-trained teacher. We validate this loss by achieving competitive J&F to state of the art on both the standard DAVIS and YouTube benchmarks, despite running up to 5x faster, and with 32x fewer parameters.
Information Theoretic Representation Distillation
Dec 01, 2021

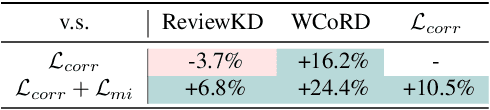

Despite the empirical success of knowledge distillation, there still lacks a theoretical foundation that can naturally lead to computationally inexpensive implementations. To address this concern, we forge an alternative connection between information theory and knowledge distillation using a recently proposed entropy-like functional. In doing so, we introduce two distinct complementary losses which aim to maximise the correlation and mutual information between the student and teacher representations. Our method achieves competitive performance to state-of-the-art on the knowledge distillation and cross-model transfer tasks, while incurring significantly less training overheads than closely related and similarly performing approaches. We further demonstrate the effectiveness of our method on a binary distillation task, whereby we shed light to a new state-of-the-art for binary quantisation. The code, evaluation protocols, and trained models will be publicly available.
Network compression and faster inference using spatial basis filters
Oct 25, 2021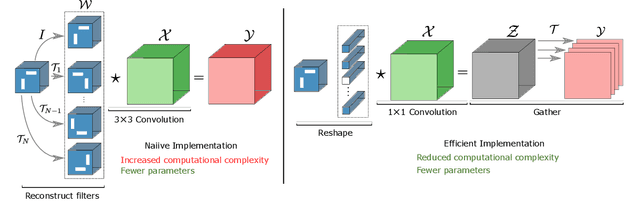
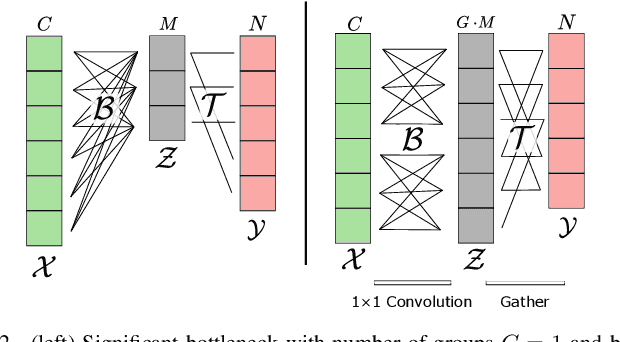
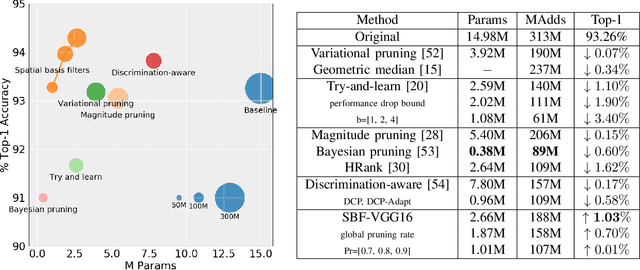
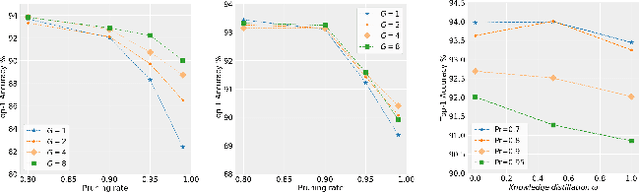
We present an efficient alternative to the convolutional layer through utilising spatial basis filters (SBF). SBF layers exploit the spatial redundancy in the convolutional filters across the depth to achieve overall model compression, while maintaining the top-end accuracy of their dense counter-parts. Training SBF-Nets is modelled as a simple pruning problem, but instead of zeroing out the pruned channels, they are replaced with inexpensive transformations from the set of non-pruned features. To enable an adoption of these SBF layers, we provide a flexible training pipeline and an efficient implementation in CUDA with low latency. To further demonstrate the effective capacity of these models, we apply semi-supervised knowledge distillation that leads to significant performance improvements over the baseline networks. Our experiments show that SBF-Nets are effective and achieve comparable or improved performance to state-of-the-art across CIFAR10, CIFAR100, Tiny-ImageNet, and ILSCRC-2012.