 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCorr: Wire Detection and Depth Estimation for Autonomous Drones
Sep 18, 2025In the realm of fully autonomous drones, the accurate detection of obstacles is paramount to ensure safe navigation and prevent collisions. Among these challenges, the detection of wires stands out due to their slender profile, which poses a unique and intricate problem. To address this issue, we present an innovative solution in the form of a monocular end-to-end model for wire segmentation and depth estimation. Our approach leverages a temporal correlation layer trained on synthetic data, providing the model with the ability to effectively tackle the complex joint task of wire detection and depth estimation. We demonstrate the superiority of our proposed method over existing competitive approaches in the joint task of wire detection and depth estimation. Our results underscore the potential of our model to enhance the safety and precision of autonomous drones, shedding light on its promising applications in real-world scenarios.
* Published in Proceedings of the 4th International Conference on Robotics, Computer Vision and Intelligent Systems (ROBOVIS), 2024
Adversarial Negotiation Dynamics in Generative Language Models
Dec 29, 2024

Generative language models are increasingly used for contract drafting and enhancement, creating a scenario where competing parties deploy different language models against each other. This introduces not only a game-theory challenge but also significant concerns related to AI safety and security, as the language model employed by the opposing party can be unknown. These competitive interactions can be seen as adversarial testing grounds, where models are effectively red-teamed to expose vulnerabilities such as generating biased, harmful or legally problematic text. Despite the importance of these challenges, the competitive robustness and safety of these models in adversarial settings remain poorly understood. In this small study, we approach this problem by evaluating the performance and vulnerabilities of major open-source language models in head-to-head competitions, simulating real-world contract negotiations. We further explore how these adversarial interactions can reveal potential risks, informing the development of more secure and reliable models. Our findings contribute to the growing body of research on AI safety, offering insights into model selection and optimisation in competitive legal contexts and providing actionable strategies for mitigating risks.
Learning to Project for Cross-Task Knowledge Distillation
Mar 21, 2024
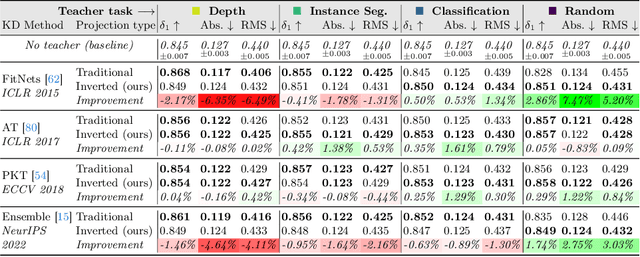
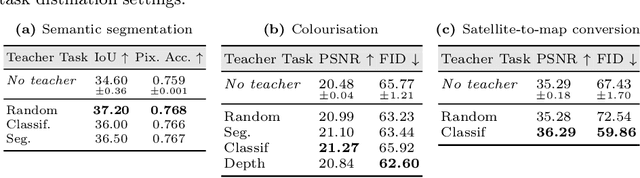
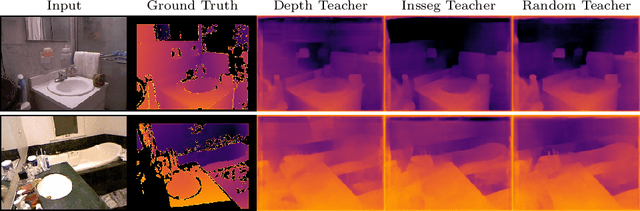
Traditional knowledge distillation (KD) relies on a proficient teacher trained on the target task, which is not always available. In this setting, cross-task distillation can be used, enabling the use of any teacher model trained on a different task. However, many KD methods prove ineffective when applied to this cross-task setting. To address this limitation, we propose a simple modification: the use of an inverted projection. We show that this drop-in replacement for a standard projector is effective by learning to disregard any task-specific features which might degrade the student's performance. We find that this simple modification is sufficient for extending many KD methods to the cross-task setting, where the teacher and student tasks can be very different. In doing so, we obtain up to a 1.9% improvement in the cross-task setting compared to the traditional projection, at no additional cost. Our method can obtain significant performance improvements (up to 7%) when using even a randomly-initialised teacher on various tasks such as depth estimation, image translation, and semantic segmentation, despite the lack of any learned knowledge to transfer. To provide conceptual and analytical insights into this result, we show that using an inverted projection allows the distillation loss to be decomposed into a knowledge transfer and a spectral regularisation component. Through this analysis we are additionally able to propose a novel regularisation loss that allows teacher-free distillation, enabling performance improvements of up to 8.57% on ImageNet with no additional training costs.
DDOS: The Drone Depth and Obstacle Segmentation Dataset
Dec 19, 2023Accurate depth and semantic segmentation are crucial for various computer vision tasks. However, the scarcity of annotated real-world aerial datasets poses a significant challenge for training and evaluating robust models. Additionally, the detection and segmentation of thin objects, such as wires, cables, and fences, present a critical concern for ensuring the safe operation of drones. To address these limitations, we present a novel synthetic dataset specifically designed for depth and semantic segmentation tasks in aerial views. Leveraging photo-realistic rendering techniques, our dataset provides a valuable resource for training models using a synthetic-supervision training scheme while introducing new drone-specific metrics for depth accuracy.
Multi-Class Segmentation from Aerial Views using Recursive Noise Diffusion
Dec 01, 2022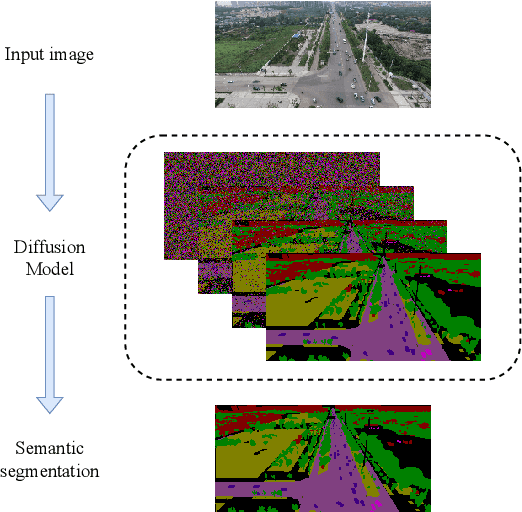
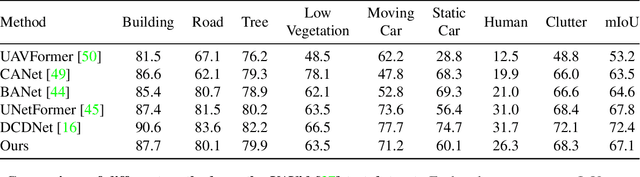
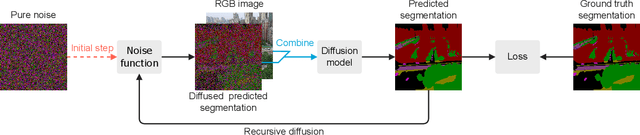
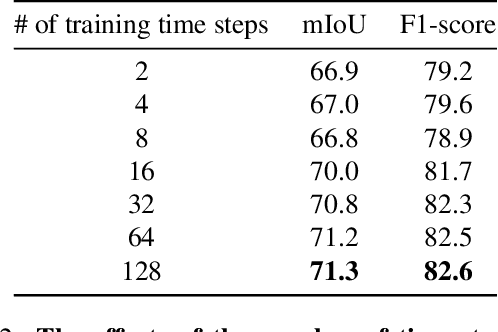
Semantic segmentation from aerial views is a vital task for autonomous drones as they require precise and accurate segmentation to traverse safely and efficiently. Segmenting images from aerial views is especially challenging as they include diverse view-points, extreme scale variation and high scene complexity. To address this problem, we propose an end-to-end multi-class semantic segmentation diffusion model. We introduce recursive denoising which allows predicted error to propagate through the denoising process. In addition, we combine this with a hierarchical multi-scale approach, complementary to the diffusion process. Our method achieves state-of-the-art results on UAVid and on the Vaihingen building segmentation benchmark.