 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Based Depth Hints for Monocular Depth Estimation
Mar 22, 2024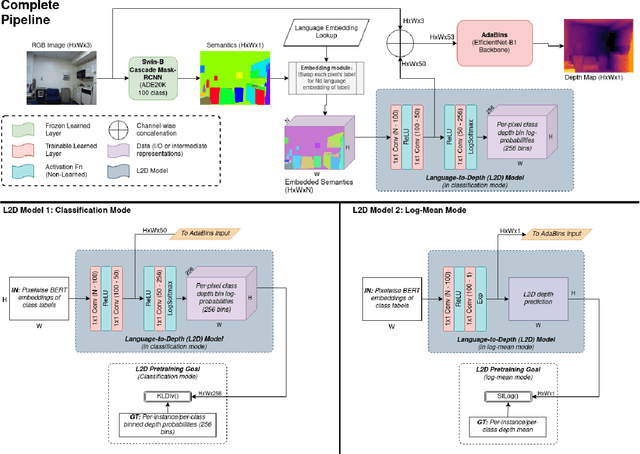
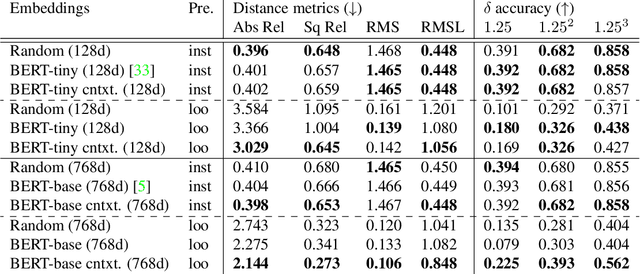
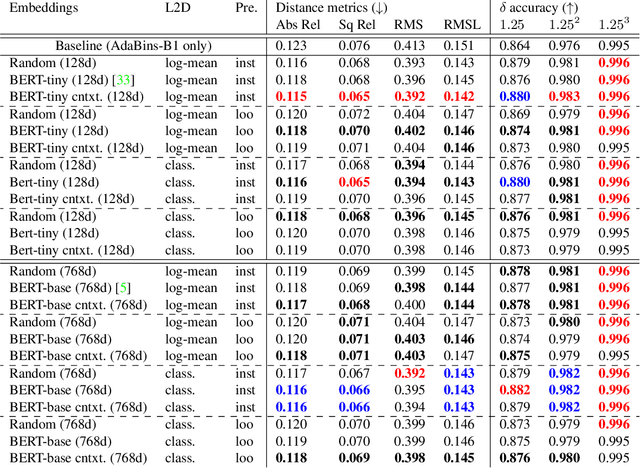
Monocular depth estimation (MDE) is inherently ambiguous, as a given image may result from many different 3D scenes and vice versa. To resolve this ambiguity, an MDE system must make assumptions about the most likely 3D scenes for a given input. These assumptions can be either explicit or implicit. In this work, we demonstrate the use of natural language as a source of an explicit prior about the structure of the world. The assumption is made that human language encodes the likely distribution in depth-space of various objects. We first show that a language model encodes this implicit bias during training, and that it can be extracted using a very simple learned approach. We then show that this prediction can be provided as an explicit source of assumption to an MDE system, using an off-the-shelf instance segmentation model that provides the labels used as the input to the language model. We demonstrate the performance of our method on the NYUD2 dataset, showing improvement compared to the baseline and to random controls.
Learning to Project for Cross-Task Knowledge Distillation
Mar 21, 2024
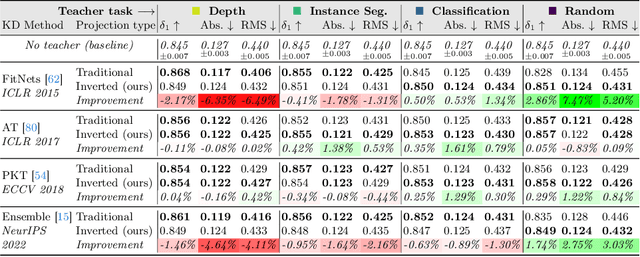
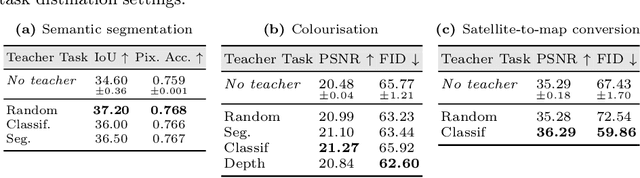
Traditional knowledge distillation (KD) relies on a proficient teacher trained on the target task, which is not always available. In this setting, cross-task distillation can be used, enabling the use of any teacher model trained on a different task. However, many KD methods prove ineffective when applied to this cross-task setting. To address this limitation, we propose a simple modification: the use of an inverted projection. We show that this drop-in replacement for a standard projector is effective by learning to disregard any task-specific features which might degrade the student's performance. We find that this simple modification is sufficient for extending many KD methods to the cross-task setting, where the teacher and student tasks can be very different. In doing so, we obtain up to a 1.9% improvement in the cross-task setting compared to the traditional projection, at no additional cost. Our method can obtain significant performance improvements (up to 7%) when using even a randomly-initialised teacher on various tasks such as depth estimation, image translation, and semantic segmentation, despite the lack of any learned knowledge to transfer. To provide conceptual and analytical insights into this result, we show that using an inverted projection allows the distillation loss to be decomposed into a knowledge transfer and a spectral regularisation component. Through this analysis we are additionally able to propose a novel regularisation loss that allows teacher-free distillation, enabling performance improvements of up to 8.57% on ImageNet with no additional training costs.
ObjCAViT: Improving Monocular Depth Estimation Using Natural Language Models And Image-Object Cross-Attention
Nov 30, 2022While monocular depth estimation (MDE) is an important problem in computer vision, it is difficult due to the ambiguity that results from the compression of a 3D scene into only 2 dimensions. It is common practice in the field to treat it as simple image-to-image translation, without consideration for the semantics of the scene and the objects within it. In contrast, humans and animals have been shown to use higher-level information to solve MDE: prior knowledge of the nature of the objects in the scene, their positions and likely configurations relative to one another, and their apparent sizes have all been shown to help resolve this ambiguity. In this paper, we present a novel method to enhance MDE performance by encouraging use of known-useful information about the semantics of objects and inter-object relationships within a scene. Our novel ObjCAViT module sources world-knowledge from language models and learns inter-object relationships in the context of the MDE problem using transformer attention, incorporating apparent size information. Our method produces highly accurate depth maps, and we obtain competitive results on the NYUv2 and KITTI datasets. Our ablation experiments show that the use of language and cross-attention within the ObjCAViT module increases performance. Code is released at https://github.com/DylanAuty/ObjCAViT.
Monocular Depth Estimation Using Cues Inspired by Biological Vision Systems
Apr 21, 2022
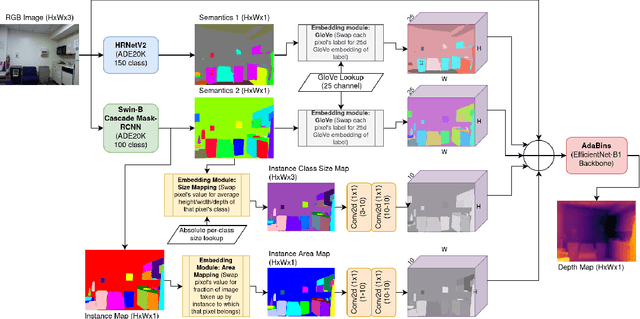
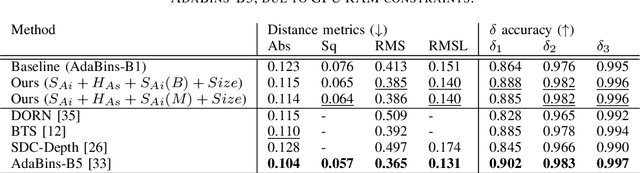

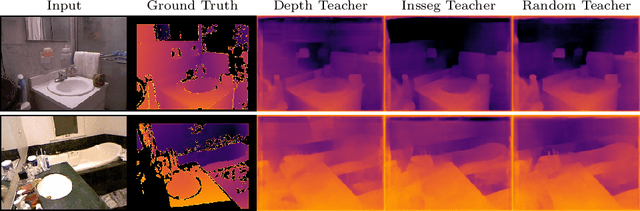
Monocular depth estimation (MDE) aims to transform an RGB image of a scene into a pixelwise depth map from the same camera view. It is fundamentally ill-posed due to missing information: any single image can have been taken from many possible 3D scenes. Part of the MDE task is, therefore, to learn which visual cues in the image can be used for depth estimation, and how. With training data limited by cost of annotation or network capacity limited by computational power, this is challenging. In this work we demonstrate that explicitly injecting visual cue information into the model is beneficial for depth estimation. Following research into biological vision systems, we focus on semantic information and prior knowledge of object sizes and their relations, to emulate the biological cues of relative size, familiar size, and absolute size. We use state-of-the-art semantic and instance segmentation models to provide external information, and exploit language embeddings to encode relational information between classes. We also provide a prior on the average real-world size of objects. This external information overcomes the limitation in data availability, and ensures that the limited capacity of a given network is focused on known-helpful cues, therefore improving performance. We experimentally validate our hypothesis and evaluate the proposed model on the widely used NYUD2 indoor depth estimation benchmark. The results show improvements in depth prediction when the semantic information, size prior and instance size are explicitly provided along with the RGB images, and our method can be easily adapted to any depth estimation system.