 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork compression and faster inference using spatial basis filters
Paper and Code
Oct 25, 2021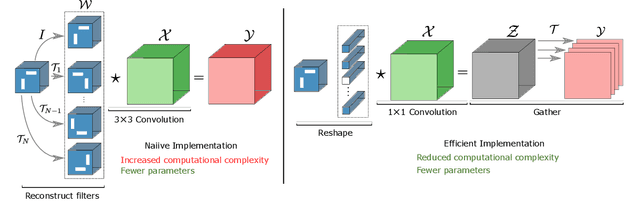
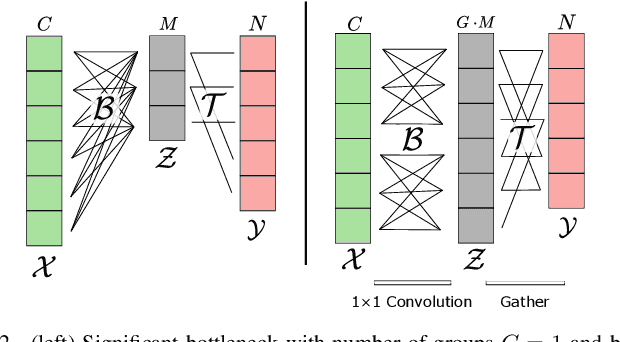
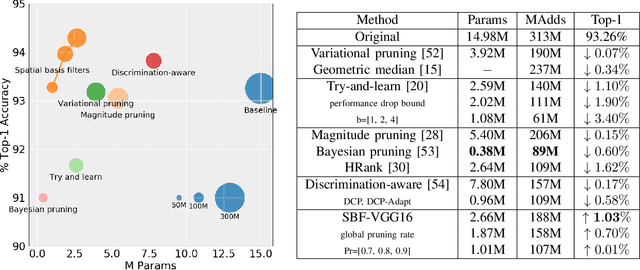
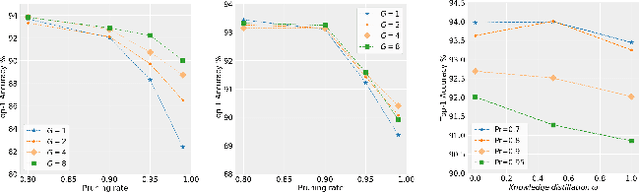
We present an efficient alternative to the convolutional layer through utilising spatial basis filters (SBF). SBF layers exploit the spatial redundancy in the convolutional filters across the depth to achieve overall model compression, while maintaining the top-end accuracy of their dense counter-parts. Training SBF-Nets is modelled as a simple pruning problem, but instead of zeroing out the pruned channels, they are replaced with inexpensive transformations from the set of non-pruned features. To enable an adoption of these SBF layers, we provide a flexible training pipeline and an efficient implementation in CUDA with low latency. To further demonstrate the effective capacity of these models, we apply semi-supervised knowledge distillation that leads to significant performance improvements over the baseline networks. Our experiments show that SBF-Nets are effective and achieve comparable or improved performance to state-of-the-art across CIFAR10, CIFAR100, Tiny-ImageNet, and ILSCRC-2012.