 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSta: Efficient Training Scheme with Siestaed Gaussians for Monocular 3D Scene Reconstruction
Apr 09, 2025



Gaussian Splatting (GS) is a popular approach for 3D reconstruction, mostly due to its ability to converge reasonably fast, faithfully represent the scene and render (novel) views in a fast fashion. However, it suffers from large storage and memory requirements, and its training speed still lags behind the hash-grid based radiance field approaches (e.g. Instant-NGP), which makes it especially difficult to deploy them in robotics scenarios, where 3D reconstruction is crucial for accurate operation. In this paper, we propose GSta that dynamically identifies Gaussians that have converged well during training, based on their positional and color gradient norms. By forcing such Gaussians into a siesta and stopping their updates (freezing) during training, we improve training speed with competitive accuracy compared to state of the art. We also propose an early stopping mechanism based on the PSNR values computed on a subset of training images. Combined with other improvements, such as integrating a learning rate scheduler, GSta achieves an improved Pareto front in convergence speed, memory and storage requirements, while preserving quality. We also show that GSta can improve other methods and complement orthogonal approaches in efficiency improvement; once combined with Trick-GS, GSta achieves up to 5x faster training, 16x smaller disk size compared to vanilla GS, while having comparable accuracy and consuming only half the peak memory. More visualisations are available at https://anilarmagan.github.io/SRUK-GSta.
Trick-GS: A Balanced Bag of Tricks for Efficient Gaussian Splatting
Jan 24, 2025Gaussian splatting (GS) for 3D reconstruction has become quite popular due to their fast training, inference speeds and high quality reconstruction. However, GS-based reconstructions generally consist of millions of Gaussians, which makes them hard to use on computationally constrained devices such as smartphones. In this paper, we first propose a principled analysis of advances in efficient GS methods. Then, we propose Trick-GS, which is a careful combination of several strategies including (1) progressive training with resolution, noise and Gaussian scales, (2) learning to prune and mask primitives and SH bands by their significance, and (3) accelerated GS training framework. Trick-GS takes a large step towards resource-constrained GS, where faster run-time, smaller and faster-convergence of models is of paramount concern. Our results on three datasets show that Trick-GS achieves up to 2x faster training, 40x smaller disk size and 2x faster rendering speed compared to vanilla GS, while having comparable accuracy.
Finding Waldo: Towards Efficient Exploration of NeRF Scene Spaces
Mar 08, 2024Neural Radiance Fields (NeRF) have quickly become the primary approach for 3D reconstruction and novel view synthesis in recent years due to their remarkable performance. Despite the huge interest in NeRF methods, a practical use case of NeRFs has largely been ignored; the exploration of the scene space modelled by a NeRF. In this paper, for the first time in the literature, we propose and formally define the scene exploration framework as the efficient discovery of NeRF model inputs (i.e. coordinates and viewing angles), using which one can render novel views that adhere to user-selected criteria. To remedy the lack of approaches addressing scene exploration, we first propose two baseline methods called Guided-Random Search (GRS) and Pose Interpolation-based Search (PIBS). We then cast scene exploration as an optimization problem, and propose the criteria-agnostic Evolution-Guided Pose Search (EGPS) for efficient exploration. We test all three approaches with various criteria (e.g. saliency maximization, image quality maximization, photo-composition quality improvement) and show that our EGPS performs more favourably than other baselines. We finally highlight key points and limitations, and outline directions for future research in scene exploration.
TrickVOS: A Bag of Tricks for Video Object Segmentation
Jun 28, 2023Space-time memory (STM) network methods have been dominant in semi-supervised video object segmentation (SVOS) due to their remarkable performance. In this work, we identify three key aspects where we can improve such methods; i) supervisory signal, ii) pretraining and iii) spatial awareness. We then propose TrickVOS; a generic, method-agnostic bag of tricks addressing each aspect with i) a structure-aware hybrid loss, ii) a simple decoder pretraining regime and iii) a cheap tracker that imposes spatial constraints in model predictions. Finally, we propose a lightweight network and show that when trained with TrickVOS, it achieves competitive results to state-of-the-art methods on DAVIS and YouTube benchmarks, while being one of the first STM-based SVOS methods that can run in real-time on a mobile device.
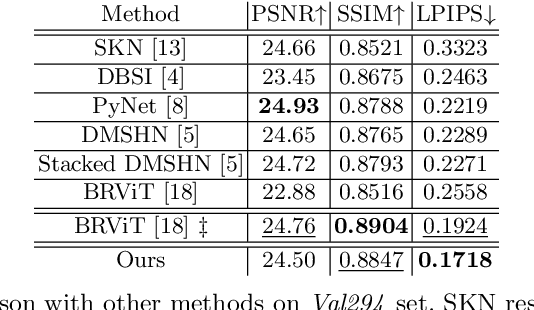
LP-IOANet: Efficient High Resolution Document Shadow Removal
Mar 22, 2023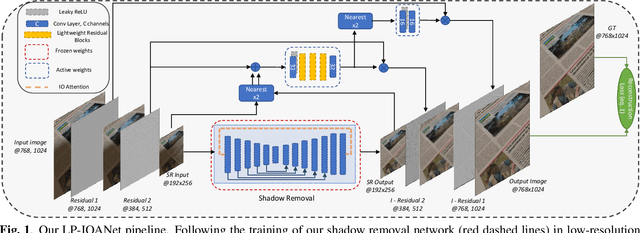

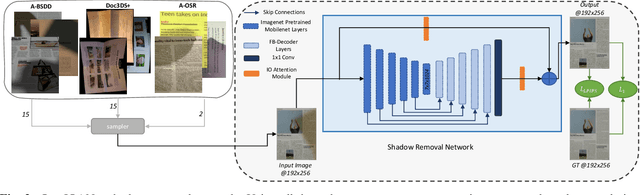

Document shadow removal is an integral task in document enhancement pipelines, as it improves visibility, readability and thus the overall quality. Assuming that the majority of practical document shadow removal scenarios require real-time, accurate models that can produce high-resolution outputs in-the-wild, we propose Laplacian Pyramid with Input/Output Attention Network (LP-IOANet), a novel pipeline with a lightweight architecture and an upsampling module. Furthermore, we propose three new datasets which cover a wide range of lighting conditions, images, shadow shapes and viewpoints. Our results show that we outperform the state-of-the-art by a 35% relative improvement in mean average error (MAE), while running real-time in four times the resolution (of the state-of-the-art method) on a mobile device.
MobileVOS: Real-Time Video Object Segmentation Contrastive Learning meets Knowledge Distillation
Mar 14, 2023This paper tackles the problem of semi-supervised video object segmentation on resource-constrained devices, such as mobile phones. We formulate this problem as a distillation task, whereby we demonstrate that small space-time-memory networks with finite memory can achieve competitive results with state of the art, but at a fraction of the computational cost (32 milliseconds per frame on a Samsung Galaxy S22). Specifically, we provide a theoretically grounded framework that unifies knowledge distillation with supervised contrastive representation learning. These models are able to jointly benefit from both pixel-wise contrastive learning and distillation from a pre-trained teacher. We validate this loss by achieving competitive J&F to state of the art on both the standard DAVIS and YouTube benchmarks, despite running up to 5x faster, and with 32x fewer parameters.
Adaptive Mask-based Pyramid Network for Realistic Bokeh Rendering
Oct 28, 2022
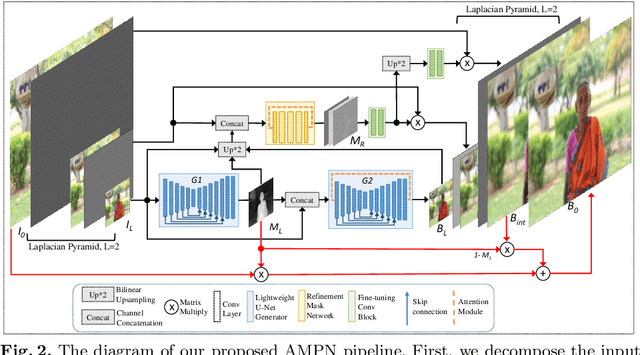
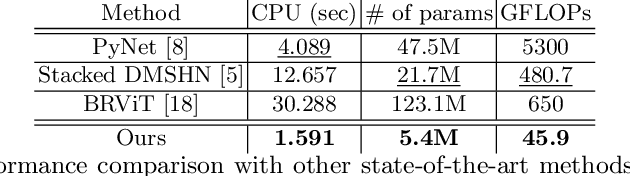
Bokeh effect highlights an object (or any part of the image) while blurring the rest of the image, and creates a visually pleasant artistic effect. Due to the sensor-based limitations on mobile devices, machine learning (ML) based bokeh rendering has gained attention as a reliable alternative. In this paper, we focus on several improvements in ML-based bokeh rendering; i) on-device performance with high-resolution images, ii) ability to guide bokeh generation with user-editable masks and iii) ability to produce varying blur strength. To this end, we propose Adaptive Mask-based Pyramid Network (AMPN), which is formed of a Mask-Guided Bokeh Generator (MGBG) block and a Laplacian Pyramid Refinement (LPR) block. MGBG consists of two lightweight networks stacked to each other to generate the bokeh effect, and LPR refines and upsamples the output of MGBG to produce the high-resolution bokeh image. We achieve i) via our lightweight, mobile-friendly design choices, ii) via the stacked-network design of MGBG and the weakly-supervised mask prediction scheme and iii) via manually or automatically editing the intensity values of the mask that guide the bokeh generation. In addition to these features, our results show that AMPN produces competitive or better results compared to existing methods on the EBB! dataset, while being faster and smaller than the alternatives.