 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Theoretic Representation Distillation
Dec 01, 2021

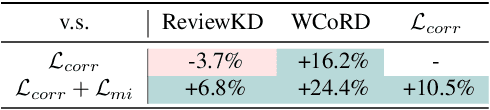

Despite the empirical success of knowledge distillation, there still lacks a theoretical foundation that can naturally lead to computationally inexpensive implementations. To address this concern, we forge an alternative connection between information theory and knowledge distillation using a recently proposed entropy-like functional. In doing so, we introduce two distinct complementary losses which aim to maximise the correlation and mutual information between the student and teacher representations. Our method achieves competitive performance to state-of-the-art on the knowledge distillation and cross-model transfer tasks, while incurring significantly less training overheads than closely related and similarly performing approaches. We further demonstrate the effectiveness of our method on a binary distillation task, whereby we shed light to a new state-of-the-art for binary quantisation. The code, evaluation protocols, and trained models will be publicly available.