 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECML: An Ensemble Cascade Metric Learning Mechanism towards Face Verification
Jul 11, 2020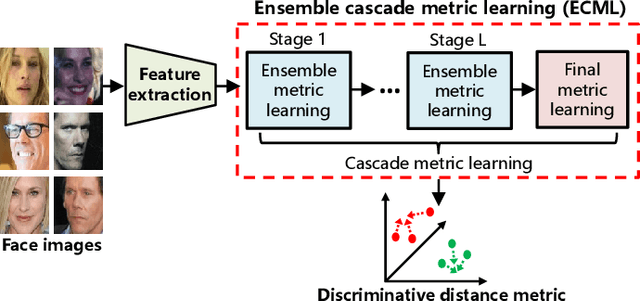
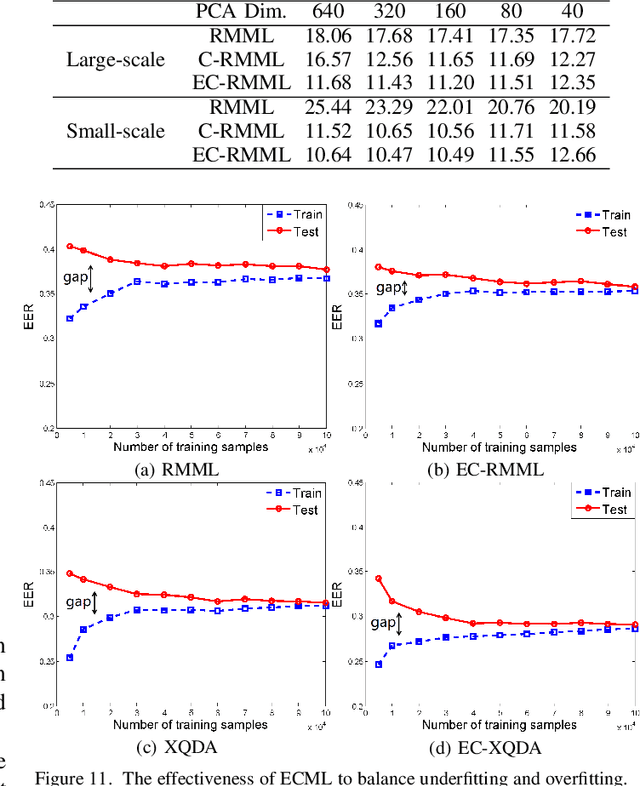
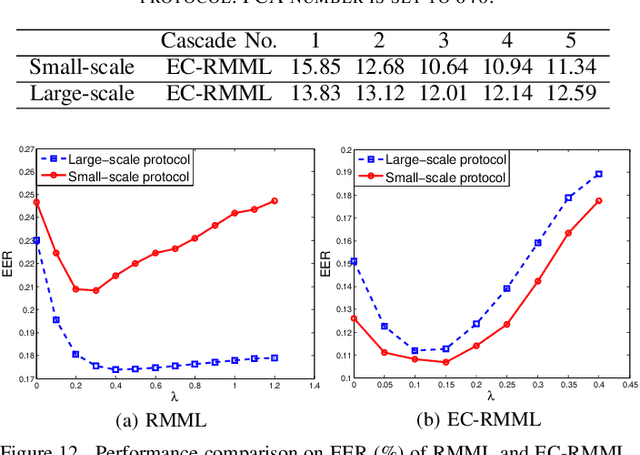
Face verification can be regarded as a 2-class fine-grained visual recognition problem. Enhancing the feature's discriminative power is one of the key problems to improve its performance. Metric learning technology is often applied to address this need, while achieving a good tradeoff between underfitting and overfitting plays the vital role in metric learning. Hence, we propose a novel ensemble cascade metric learning (ECML) mechanism. In particular, hierarchical metric learning is executed in the cascade way to alleviate underfitting. Meanwhile, at each learning level, the features are split into non-overlapping groups. Then, metric learning is executed among the feature groups in the ensemble manner to resist overfitting. Considering the feature distribution characteristics of faces, a robust Mahalanobis metric learning method (RMML) with closed-form solution is additionally proposed. It can avoid the computation failure issue on inverse matrix faced by some well-known metric learning approaches (e.g., KISSME). Embedding RMML into the proposed ECML mechanism, our metric learning paradigm (EC-RMML) can run in the one-pass learning manner. Experimental results demonstrate that EC-RMML is superior to state-of-the-art metric learning methods for face verification. And, the proposed ensemble cascade metric learning mechanism is also applicable to other metric learning approaches.
3DV: 3D Dynamic Voxel for Action Recognition in Depth Video
May 12, 2020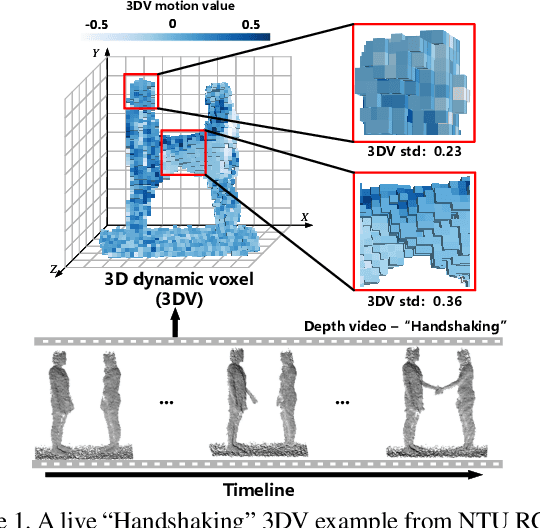
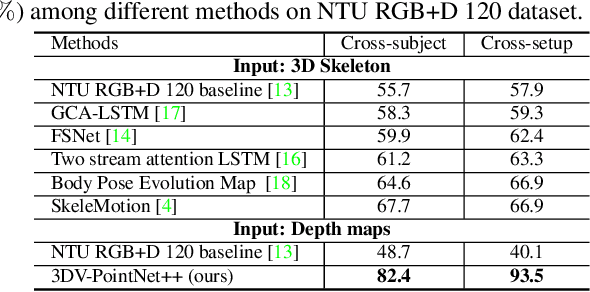
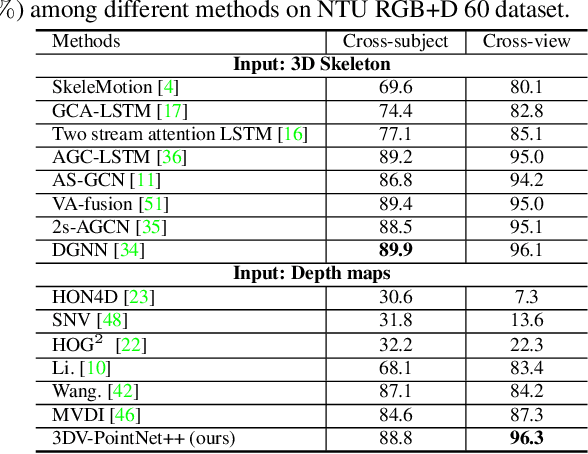
To facilitate depth-based 3D action recognition, 3D dynamic voxel (3DV) is proposed as a novel 3D motion representation. With 3D space voxelization, the key idea of 3DV is to encode 3D motion information within depth video into a regular voxel set (i.e., 3DV) compactly, via temporal rank pooling. Each available 3DV voxel intrinsically involves 3D spatial and motion feature jointly. 3DV is then abstracted as a point set and input into PointNet++ for 3D action recognition, in the end-to-end learning way. The intuition for transferring 3DV into the point set form is that, PointNet++ is lightweight and effective for deep feature learning towards point set. Since 3DV may lose appearance clue, a multi-stream 3D action recognition manner is also proposed to learn motion and appearance feature jointly. To extract richer temporal order information of actions, we also divide the depth video into temporal splits and encode this procedure in 3DV integrally. The extensive experiments on 4 well-established benchmark datasets demonstrate the superiority of our proposition. Impressively, we acquire the accuracy of 82.4% and 93.5% on NTU RGB+D 120 [13] with the cross-subject and crosssetup test setting respectively. 3DV's code is available at https://github.com/3huo/3DV-Action.
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
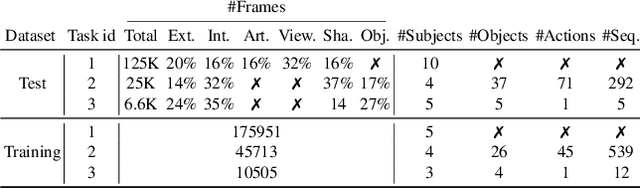
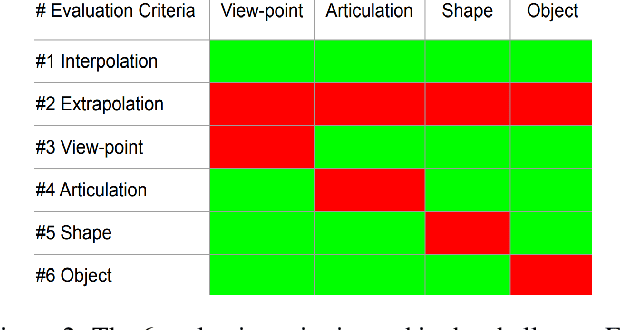
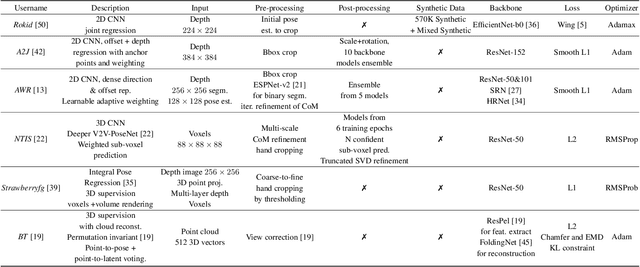
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.
A2J: Anchor-to-Joint Regression Network for 3D Articulated Pose Estimation from a Single Depth Image
Aug 27, 2019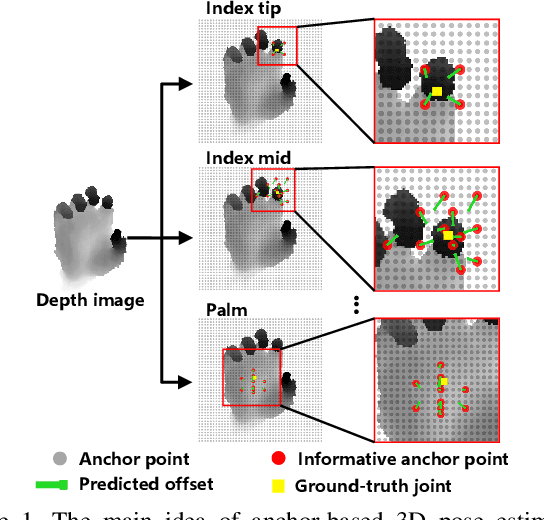

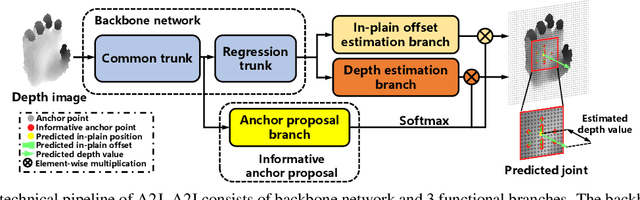
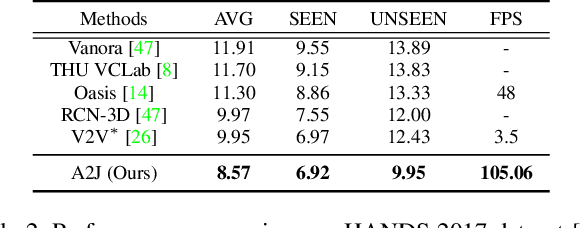
For 3D hand and body pose estimation task in depth image, a novel anchor-based approach termed Anchor-to-Joint regression network (A2J) with the end-to-end learning ability is proposed. Within A2J, anchor points able to capture global-local spatial context information are densely set on depth image as local regressors for the joints. They contribute to predict the positions of the joints in ensemble way to enhance generalization ability. The proposed 3D articulated pose estimation paradigm is different from the state-of-the-art encoder-decoder based FCN, 3D CNN and point-set based manners. To discover informative anchor points towards certain joint, anchor proposal procedure is also proposed for A2J. Meanwhile 2D CNN (i.e., ResNet-50) is used as backbone network to drive A2J, without using time-consuming 3D convolutional or deconvolutional layers. The experiments on 3 hand datasets and 2 body datasets verify A2J's superiority. Meanwhile, A2J is of high running speed around 100 FPS on single NVIDIA 1080Ti GPU.
Towards Good Practices on Building Effective CNN Baseline Model for Person Re-identification
Jul 29, 2018Person re-identification is indeed a challenging visual recognition task due to the critical issues of human pose variation, human body occlusion, camera view variation, etc. To address this, most of the state-of-the-art approaches are proposed based on deep convolutional neural network (CNN), being leveraged by its strong feature learning power and classification boundary fitting capacity. Although the vital role towards person re-identification, how to build effective CNN baseline model has not been well studied yet. To answer this open question, we propose 3 good practices in this paper from the perspectives of adjusting CNN architecture and training procedure. In particular, they are adding batch normalization after the global pooling layer, executing identity categorization directly using only one fully-connected, and using Adam as optimizer. The extensive experiments on 3 widely-used benchmark datasets demonstrate that, our propositions essentially facilitate the CNN baseline model to achieve the state-of-the-art performance without any other high-level domain knowledge or low-level technical trick.