 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStegoNGP: 3D Cryptographic Steganography using Instant-NGP
Mar 01, 2026Recently, Instant Neural Graphics Primitives (Instant-NGP) has achieved significant success in rapid 3D scene reconstruction, but securely embedding high-capacity hidden data, such as an entire 3D scene, remains a challenge. Existing methods rely on external decoders, require architectural modifications, and suffer from limited capacity, which makes them easily detectable. We propose a novel parameter-free 3D Cryptographic Steganography using Instant-NGP (StegoNGP), which leverages the Instant-NGP hash encoding function as a key-controlled scene switcher. By associating a default key with a cover scene and a secret key with a hidden scene, our method trains a single model to interweave both representations within the same network weights. The resulting model is indistinguishable from a standard Instant-NGP in architecture and parameter count. We also introduce an enhanced Multi-Key scheme, which assigns multiple independent keys across hash levels, dramatically expanding the key space and providing high robustness against partial key disclosure attacks. Experimental results demonstrated that StegoNGP can hide a complete high-quality 3D scene with strong imperceptibility and security, providing a new paradigm for high-capacity, undetectable information hiding in neural fields. The code can be found at https://github.com/jiang-wenxiang/StegoNGP.
IPA-NeRF: Illusory Poisoning Attack Against Neural Radiance Fields
Jul 16, 2024
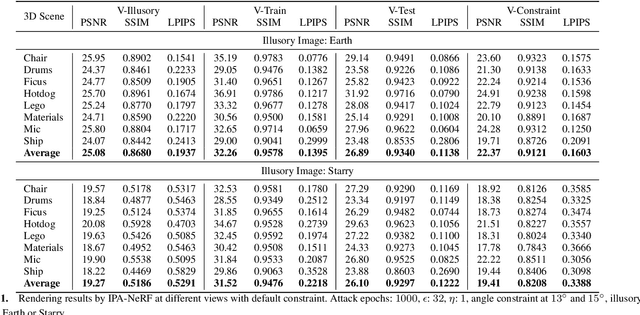
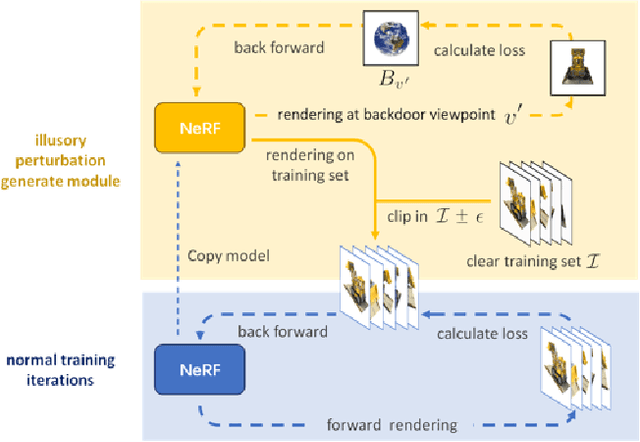
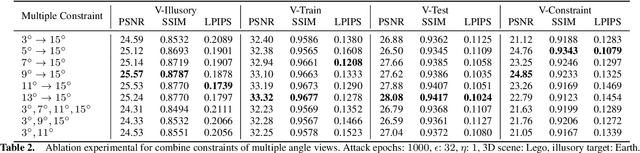
Neural Radiance Field (NeRF) represents a significant advancement in computer vision, offering implicit neural network-based scene representation and novel view synthesis capabilities. Its applications span diverse fields including robotics, urban mapping, autonomous navigation, virtual reality/augmented reality, etc., some of which are considered high-risk AI applications. However, despite its widespread adoption, the robustness and security of NeRF remain largely unexplored. In this study, we contribute to this area by introducing the Illusory Poisoning Attack against Neural Radiance Fields (IPA-NeRF). This attack involves embedding a hidden backdoor view into NeRF, allowing it to produce predetermined outputs, i.e. illusory, when presented with the specified backdoor view while maintaining normal performance with standard inputs. Our attack is specifically designed to deceive users or downstream models at a particular position while ensuring that any abnormalities in NeRF remain undetectable from other viewpoints. Experimental results demonstrate the effectiveness of our Illusory Poisoning Attack, successfully presenting the desired illusory on the specified viewpoint without impacting other views. Notably, we achieve this attack by introducing small perturbations solely to the training set. The code can be found at https://github.com/jiang-wenxiang/IPA-NeRF.
3DV: 3D Dynamic Voxel for Action Recognition in Depth Video
May 12, 2020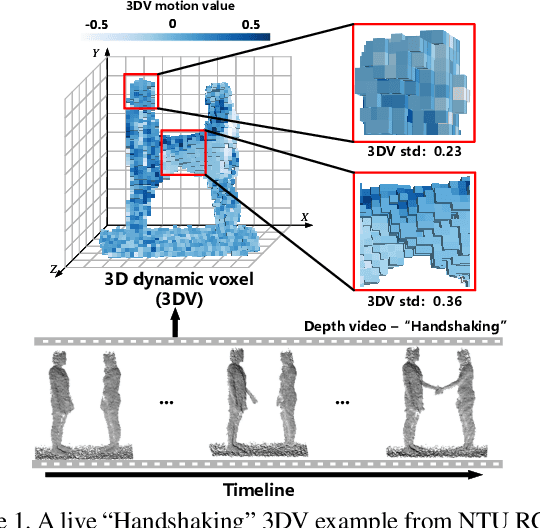
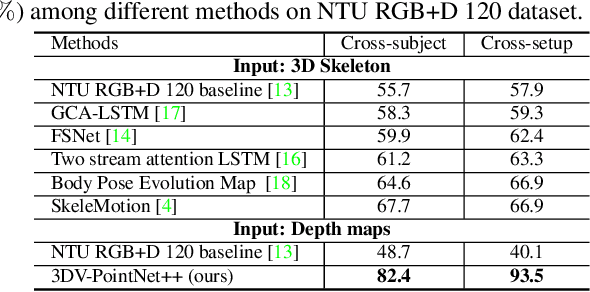
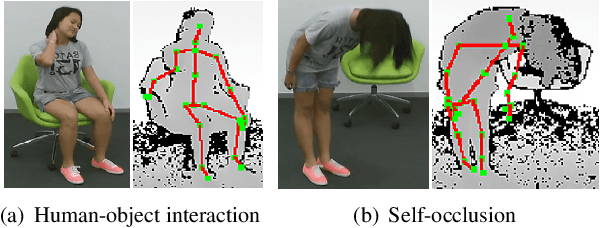
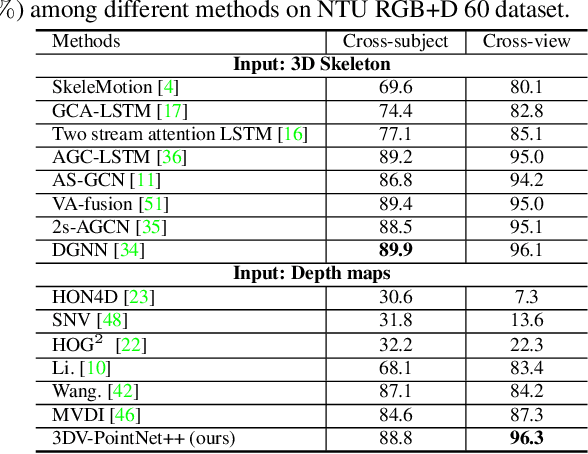
To facilitate depth-based 3D action recognition, 3D dynamic voxel (3DV) is proposed as a novel 3D motion representation. With 3D space voxelization, the key idea of 3DV is to encode 3D motion information within depth video into a regular voxel set (i.e., 3DV) compactly, via temporal rank pooling. Each available 3DV voxel intrinsically involves 3D spatial and motion feature jointly. 3DV is then abstracted as a point set and input into PointNet++ for 3D action recognition, in the end-to-end learning way. The intuition for transferring 3DV into the point set form is that, PointNet++ is lightweight and effective for deep feature learning towards point set. Since 3DV may lose appearance clue, a multi-stream 3D action recognition manner is also proposed to learn motion and appearance feature jointly. To extract richer temporal order information of actions, we also divide the depth video into temporal splits and encode this procedure in 3DV integrally. The extensive experiments on 4 well-established benchmark datasets demonstrate the superiority of our proposition. Impressively, we acquire the accuracy of 82.4% and 93.5% on NTU RGB+D 120 [13] with the cross-subject and crosssetup test setting respectively. 3DV's code is available at https://github.com/3huo/3DV-Action.