 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DV: 3D Dynamic Voxel for Action Recognition in Depth Video
Paper and Code
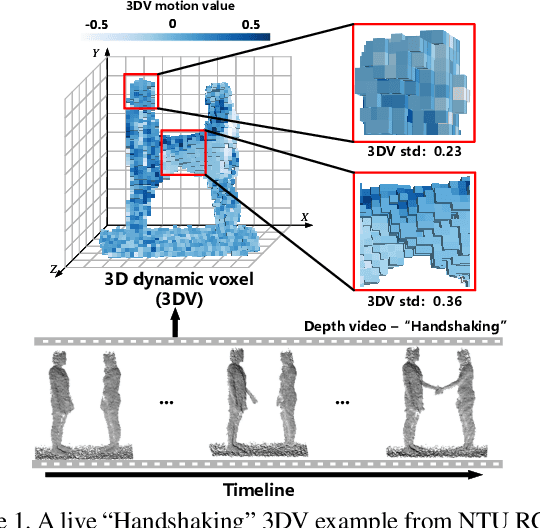
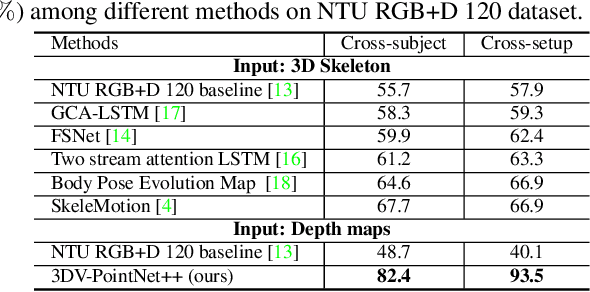
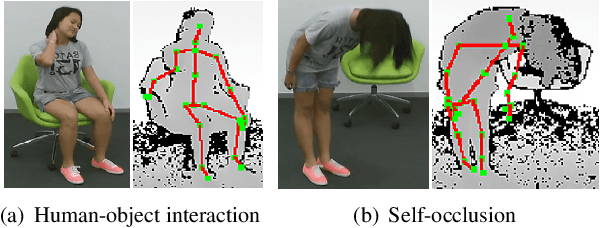
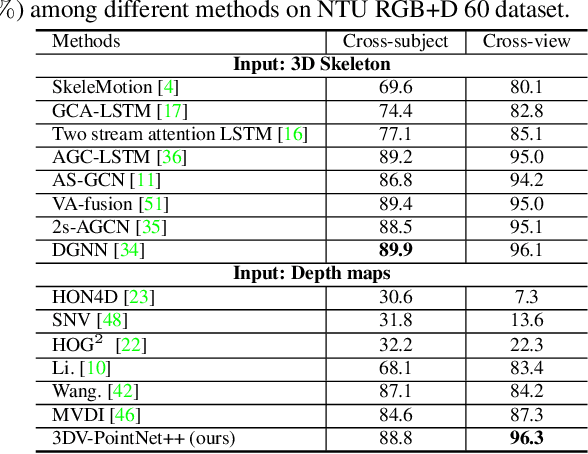
To facilitate depth-based 3D action recognition, 3D dynamic voxel (3DV) is proposed as a novel 3D motion representation. With 3D space voxelization, the key idea of 3DV is to encode 3D motion information within depth video into a regular voxel set (i.e., 3DV) compactly, via temporal rank pooling. Each available 3DV voxel intrinsically involves 3D spatial and motion feature jointly. 3DV is then abstracted as a point set and input into PointNet++ for 3D action recognition, in the end-to-end learning way. The intuition for transferring 3DV into the point set form is that, PointNet++ is lightweight and effective for deep feature learning towards point set. Since 3DV may lose appearance clue, a multi-stream 3D action recognition manner is also proposed to learn motion and appearance feature jointly. To extract richer temporal order information of actions, we also divide the depth video into temporal splits and encode this procedure in 3DV integrally. The extensive experiments on 4 well-established benchmark datasets demonstrate the superiority of our proposition. Impressively, we acquire the accuracy of 82.4% and 93.5% on NTU RGB+D 120 [13] with the cross-subject and crosssetup test setting respectively. 3DV's code is available at https://github.com/3huo/3DV-Action.