 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossGLG: LLM Guides One-shot Skeleton-based 3D Action Recognition in a Cross-level Manner
Mar 15, 2024
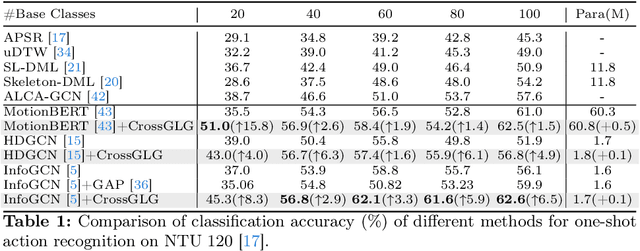
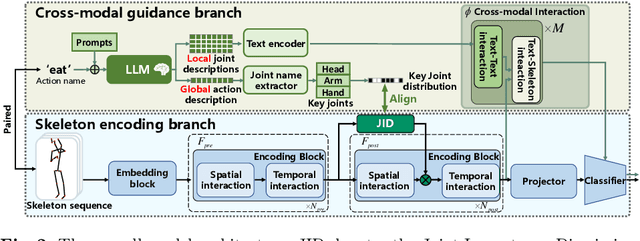
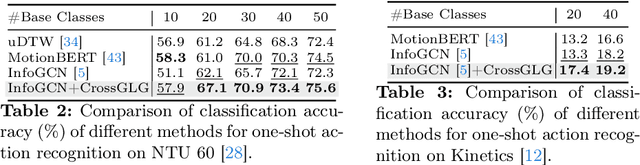
Most existing one-shot skeleton-based action recognition focuses on raw low-level information (e.g., joint location), and may suffer from local information loss and low generalization ability. To alleviate these, we propose to leverage text description generated from large language models (LLM) that contain high-level human knowledge, to guide feature learning, in a global-local-global way. Particularly, during training, we design $2$ prompts to gain global and local text descriptions of each action from an LLM. We first utilize the global text description to guide the skeleton encoder focus on informative joints (i.e.,global-to-local). Then we build non-local interaction between local text and joint features, to form the final global representation (i.e., local-to-global). To mitigate the asymmetry issue between the training and inference phases, we further design a dual-branch architecture that allows the model to perform novel class inference without any text input, also making the additional inference cost neglectable compared with the base skeleton encoder. Extensive experiments on three different benchmarks show that CrossGLG consistently outperforms the existing SOTA methods with large margins, and the inference cost (model size) is only $2.8$\% than the previous SOTA. CrossGLG can also serve as a plug-and-play module that can substantially enhance the performance of different SOTA skeleton encoders with a neglectable cost during inference. The source code will be released soon.
Real-time Multi-person Eyeblink Detection in the Wild for Untrimmed Video
Mar 28, 2023Real-time eyeblink detection in the wild can widely serve for fatigue detection, face anti-spoofing, emotion analysis, etc. The existing research efforts generally focus on single-person cases towards trimmed video. However, multi-person scenario within untrimmed videos is also important for practical applications, which has not been well concerned yet. To address this, we shed light on this research field for the first time with essential contributions on dataset, theory, and practices. In particular, a large-scale dataset termed MPEblink that involves 686 untrimmed videos with 8748 eyeblink events is proposed under multi-person conditions. The samples are captured from unconstrained films to reveal "in the wild" characteristics. Meanwhile, a real-time multi-person eyeblink detection method is also proposed. Being different from the existing counterparts, our proposition runs in a one-stage spatio-temporal way with end-to-end learning capacity. Specifically, it simultaneously addresses the sub-tasks of face detection, face tracking, and human instance-level eyeblink detection. This paradigm holds 2 main advantages: (1) eyeblink features can be facilitated via the face's global context (e.g., head pose and illumination condition) with joint optimization and interaction, and (2) addressing these sub-tasks in parallel instead of sequential manner can save time remarkably to meet the real-time running requirement. Experiments on MPEblink verify the essential challenges of real-time multi-person eyeblink detection in the wild for untrimmed video. Our method also outperforms existing approaches by large margins and with a high inference speed.
Towards Real-time Eyeblink Detection in The Wild:Dataset,Theory and Practices
Feb 21, 2019
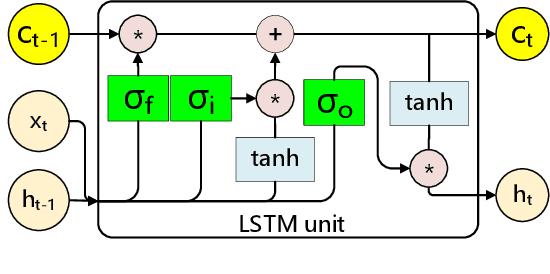
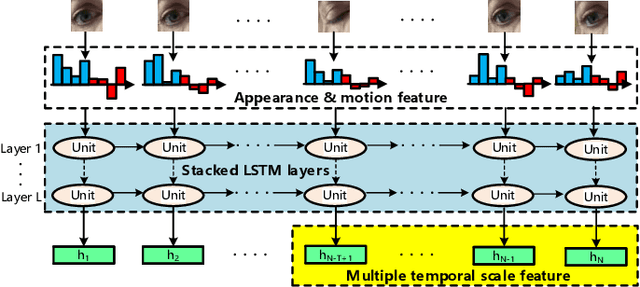
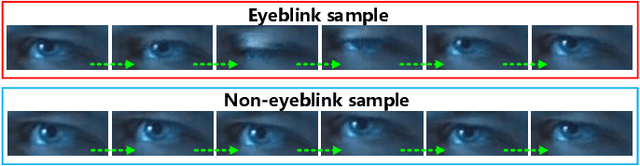
Effective and real-time eyeblink detection is of wide-range applications, such as deception detection, drive fatigue detection, face anti-spoofing, etc. Although numerous of efforts have already been paid, most of them focus on addressing the eyeblink detection problem under the constrained indoor conditions with the relative consistent subject and environment setup. Nevertheless, towards the practical applications eyeblink detection in the wild is more required, and of greater challenges. However, to our knowledge this has not been well studied before. In this paper, we shed the light to this research topic. A labelled eyeblink in the wild dataset (i.e., HUST-LEBW) of 673 eyeblink video samples (i.e., 381 positives, and 292 negatives) is first established by us. These samples are captured from the unconstrained movies, with the dramatic variation on human attribute, human pose, illumination condition, imaging configuration, etc. Then, we formulate eyeblink detection task as a spatial-temporal pattern recognition problem. After locating and tracking human eye using SeetaFace engine and KCF tracker respectively, a modified LSTM model able to capture the multi-scale temporal information is proposed to execute eyeblink verification. A feature extraction approach that reveals appearance and motion characteristics simultaneously is also proposed. The experiments on HUST-LEBW reveal the superiority and efficiency of our approach. It also verifies that, the existing eyeblink detection methods cannot achieve satisfactory performance in the wild.
Towards Good Practices on Building Effective CNN Baseline Model for Person Re-identification
Jul 29, 2018Person re-identification is indeed a challenging visual recognition task due to the critical issues of human pose variation, human body occlusion, camera view variation, etc. To address this, most of the state-of-the-art approaches are proposed based on deep convolutional neural network (CNN), being leveraged by its strong feature learning power and classification boundary fitting capacity. Although the vital role towards person re-identification, how to build effective CNN baseline model has not been well studied yet. To answer this open question, we propose 3 good practices in this paper from the perspectives of adjusting CNN architecture and training procedure. In particular, they are adding batch normalization after the global pooling layer, executing identity categorization directly using only one fully-connected, and using Adam as optimizer. The extensive experiments on 3 widely-used benchmark datasets demonstrate that, our propositions essentially facilitate the CNN baseline model to achieve the state-of-the-art performance without any other high-level domain knowledge or low-level technical trick.