 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
GCE-Pose: Global Context Enhancement for Category-level Object Pose Estimation
Feb 06, 2025A key challenge in model-free category-level pose estimation is the extraction of contextual object features that generalize across varying instances within a specific category. Recent approaches leverage foundational features to capture semantic and geometry cues from data. However, these approaches fail under partial visibility. We overcome this with a first-complete-then-aggregate strategy for feature extraction utilizing class priors. In this paper, we present GCE-Pose, a method that enhances pose estimation for novel instances by integrating category-level global context prior. GCE-Pose performs semantic shape reconstruction with a proposed Semantic Shape Reconstruction (SSR) module. Given an unseen partial RGB-D object instance, our SSR module reconstructs the instance's global geometry and semantics by deforming category-specific 3D semantic prototypes through a learned deep Linear Shape Model. We further introduce a Global Context Enhanced (GCE) feature fusion module that effectively fuses features from partial RGB-D observations and the reconstructed global context. Extensive experiments validate the impact of our global context prior and the effectiveness of the GCE fusion module, demonstrating that GCE-Pose significantly outperforms existing methods on challenging real-world datasets HouseCat6D and NOCS-REAL275. Our project page is available at https://colin-de.github.io/GCE-Pose/.
Alignist: CAD-Informed Orientation Distribution Estimation by Fusing Shape and Correspondences
Sep 10, 2024
Object pose distribution estimation is crucial in robotics for better path planning and handling of symmetric objects. Recent distribution estimation approaches employ contrastive learning-based approaches by maximizing the likelihood of a single pose estimate in the absence of a CAD model. We propose a pose distribution estimation method leveraging symmetry respecting correspondence distributions and shape information obtained using a CAD model. Contrastive learning-based approaches require an exhaustive amount of training images from different viewpoints to learn the distribution properly, which is not possible in realistic scenarios. Instead, we propose a pipeline that can leverage correspondence distributions and shape information from the CAD model, which are later used to learn pose distributions. Besides, having access to pose distribution based on correspondences before learning pose distributions conditioned on images, can help formulate the loss between distributions. The prior knowledge of distribution also helps the network to focus on getting sharper modes instead. With the CAD prior, our approach converges much faster and learns distribution better by focusing on learning sharper distribution near all the valid modes, unlike contrastive approaches, which focus on a single mode at a time. We achieve benchmark results on SYMSOL-I and T-Less datasets.
MatchU: Matching Unseen Objects for 6D Pose Estimation from RGB-D Images
Mar 03, 2024



Recent learning methods for object pose estimation require resource-intensive training for each individual object instance or category, hampering their scalability in real applications when confronted with previously unseen objects. In this paper, we propose MatchU, a Fuse-Describe-Match strategy for 6D pose estimation from RGB-D images. MatchU is a generic approach that fuses 2D texture and 3D geometric cues for 6D pose prediction of unseen objects. We rely on learning geometric 3D descriptors that are rotation-invariant by design. By encoding pose-agnostic geometry, the learned descriptors naturally generalize to unseen objects and capture symmetries. To tackle ambiguous associations using 3D geometry only, we fuse additional RGB information into our descriptor. This is achieved through a novel attention-based mechanism that fuses cross-modal information, together with a matching loss that leverages the latent space learned from RGB data to guide the descriptor learning process. Extensive experiments reveal the generalizability of both the RGB-D fusion strategy as well as the descriptor efficacy. Benefiting from the novel designs, MatchU surpasses all existing methods by a significant margin in terms of both accuracy and speed, even without the requirement of expensive re-training or rendering.
S4R: Self-Supervised Semantic Scene Reconstruction from RGB-D Scans
Feb 21, 2023



Most deep learning approaches to comprehensive semantic modeling of 3D indoor spaces require costly dense annotations in the 3D domain. In this work, we explore a central 3D scene modeling task, namely, semantic scene reconstruction, using a fully self-supervised approach. To this end, we design a trainable model that employs both incomplete 3D reconstructions and their corresponding source RGB-D images, fusing cross-domain features into volumetric embeddings to predict complete 3D geometry, color, and semantics. Our key technical innovation is to leverage differentiable rendering of color and semantics, using the observed RGB images and a generic semantic segmentation model as color and semantics supervision, respectively. We additionally develop a method to synthesize an augmented set of virtual training views complementing the original real captures, enabling more efficient self-supervision for semantics. In this work we propose an end-to-end trainable solution jointly addressing geometry completion, colorization, and semantic mapping from a few RGB-D images, without 3D or 2D ground-truth. Our method is the first, to our knowledge, fully self-supervised method addressing completion and semantic segmentation of real-world 3D scans. It performs comparably well with the 3D supervised baselines, surpasses baselines with 2D supervision on real datasets, and generalizes well to unseen scenes.
StablePose: Learning 6D Object Poses from Geometrically Stable Patches
Feb 18, 2021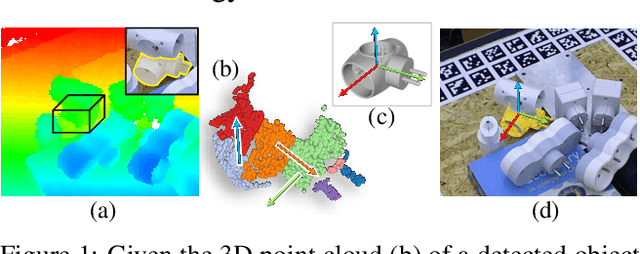
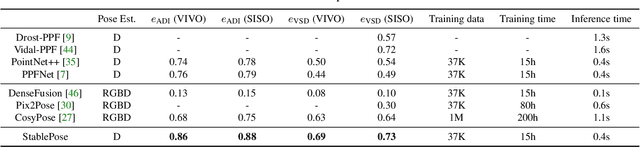
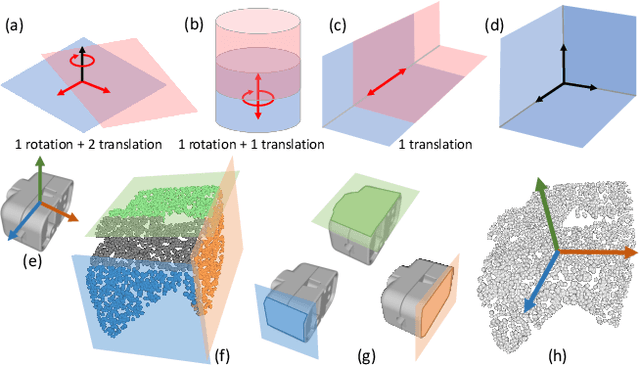
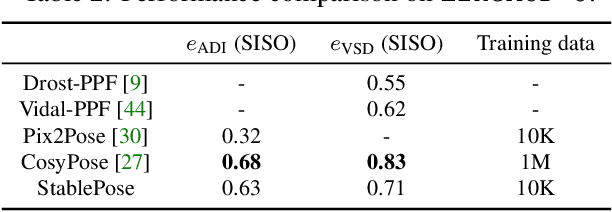
We introduce the concept of geometric stability to the problem of 6D object pose estimation and propose to learn pose inference based on geometrically stable patches extracted from observed 3D point clouds. According to the theory of geometric stability analysis, a minimal set of three planar/cylindrical patches are geometrically stable and determine the full 6DoFs of the object pose. We train a deep neural network to regress 6D object pose based on geometrically stable patch groups via learning both intra-patch geometric features and inter-patch contextual features. A subnetwork is jointly trained to predict per-patch poses. This auxiliary task is a relaxation of the group pose prediction: A single patch cannot determine the full 6DoFs but is able to improve pose accuracy in its corresponding DoFs. Working with patch groups makes our method generalize well for random occlusion and unseen instances. The method is easily amenable to resolve symmetry ambiguities. Our method achieves the state-of-the-art results on public benchmarks compared not only to depth-only but also to RGBD methods. It also performs well in category-level pose estimation.
SymmetryNet: Learning to Predict Reflectional and Rotational Symmetries of 3D Shapes from Single-View RGB-D Images
Aug 30, 2020
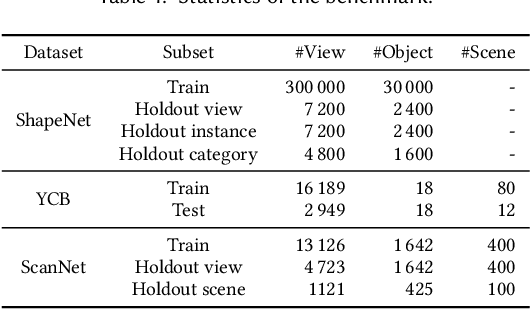
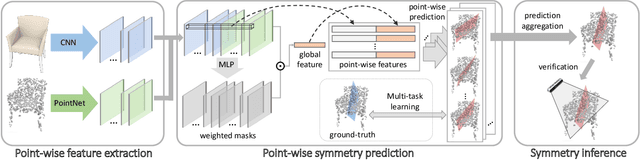
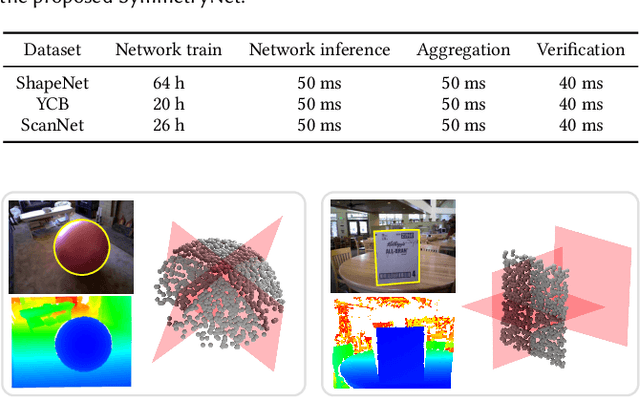
We study the problem of symmetry detection of 3D shapes from single-view RGB-D images, where severely missing data renders geometric detection approach infeasible. We propose an end-to-end deep neural network which is able to predict both reflectional and rotational symmetries of 3D objects present in the input RGB-D image. Directly training a deep model for symmetry prediction, however, can quickly run into the issue of overfitting. We adopt a multi-task learning approach. Aside from symmetry axis prediction, our network is also trained to predict symmetry correspondences. In particular, given the 3D points present in the RGB-D image, our network outputs for each 3D point its symmetric counterpart corresponding to a specific predicted symmetry. In addition, our network is able to detect for a given shape multiple symmetries of different types. We also contribute a benchmark of 3D symmetry detection based on single-view RGB-D images. Extensive evaluation on the benchmark demonstrates the strong generalization ability of our method, in terms of high accuracy of both symmetry axis prediction and counterpart estimation. In particular, our method is robust in handling unseen object instances with large variation in shape, multi-symmetry composition, as well as novel object categories.
* 15 pages