 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRehearsalNeRF: Decoupling Intrinsic Neural Fields of Dynamic Illuminations for Scene Editing
Apr 02, 2026Although there has been significant progress in neural radiance fields, an issue on dynamic illumination changes still remains unsolved. Different from relevant works that parameterize time-variant/-invariant components in scenes, subjects' radiance is highly entangled with their own emitted radiance and lighting colors in spatio-temporal domain. In this paper, we present a new effective method to learn disentangled neural fields under the severe illumination changes, named RehearsalNeRF. Our key idea is to leverage scenes captured under stable lighting like rehearsal stages, easily taken before dynamic illumination occurs, to enforce geometric consistency between the different lighting conditions. In particular, RehearsalNeRF employs a learnable vector for lighting effects which represents illumination colors in a temporal dimension and is used to disentangle projected light colors from scene radiance. Furthermore, our RehearsalNeRF is also able to reconstruct the neural fields of dynamic objects by simply adopting off-the-shelf interactive masks. To decouple the dynamic objects, we propose a new regularization leveraging optical flow, which provides coarse supervision for the color disentanglement. We demonstrate the effectiveness of RehearsalNeRF by showing robust performances on novel view synthesis and scene editing under dynamic illumination conditions. Our source code and video datasets will be publicly available.
BenchSeg: A Large-Scale Dataset and Benchmark for Multi-View Food Video Segmentation
Jan 12, 2026Food image segmentation is a critical task for dietary analysis, enabling accurate estimation of food volume and nutrients. However, current methods suffer from limited multi-view data and poor generalization to new viewpoints. We introduce BenchSeg, a novel multi-view food video segmentation dataset and benchmark. BenchSeg aggregates 55 dish scenes (from Nutrition5k, Vegetables & Fruits, MetaFood3D, and FoodKit) with 25,284 meticulously annotated frames, capturing each dish under free 360° camera motion. We evaluate a diverse set of 20 state-of-the-art segmentation models (e.g., SAM-based, transformer, CNN, and large multimodal) on the existing FoodSeg103 dataset and evaluate them (alone and combined with video-memory modules) on BenchSeg. Quantitative and qualitative results demonstrate that while standard image segmenters degrade sharply under novel viewpoints, memory-augmented methods maintain temporal consistency across frames. Our best model based on a combination of SeTR-MLA+XMem2 outperforms prior work (e.g., improving over FoodMem by ~2.63% mAP), offering new insights into food segmentation and tracking for dietary analysis. We release BenchSeg to foster future research. The project page including the dataset annotations and the food segmentation models can be found at https://amughrabi.github.io/benchseg.
GCE-Pose: Global Context Enhancement for Category-level Object Pose Estimation
Feb 06, 2025A key challenge in model-free category-level pose estimation is the extraction of contextual object features that generalize across varying instances within a specific category. Recent approaches leverage foundational features to capture semantic and geometry cues from data. However, these approaches fail under partial visibility. We overcome this with a first-complete-then-aggregate strategy for feature extraction utilizing class priors. In this paper, we present GCE-Pose, a method that enhances pose estimation for novel instances by integrating category-level global context prior. GCE-Pose performs semantic shape reconstruction with a proposed Semantic Shape Reconstruction (SSR) module. Given an unseen partial RGB-D object instance, our SSR module reconstructs the instance's global geometry and semantics by deforming category-specific 3D semantic prototypes through a learned deep Linear Shape Model. We further introduce a Global Context Enhanced (GCE) feature fusion module that effectively fuses features from partial RGB-D observations and the reconstructed global context. Extensive experiments validate the impact of our global context prior and the effectiveness of the GCE fusion module, demonstrating that GCE-Pose significantly outperforms existing methods on challenging real-world datasets HouseCat6D and NOCS-REAL275. Our project page is available at https://colin-de.github.io/GCE-Pose/.
Fully Explicit Dynamic Gaussian Splatting
Oct 21, 2024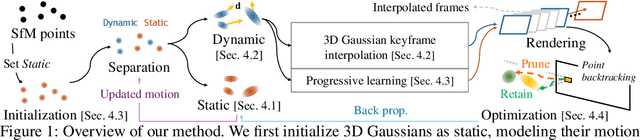
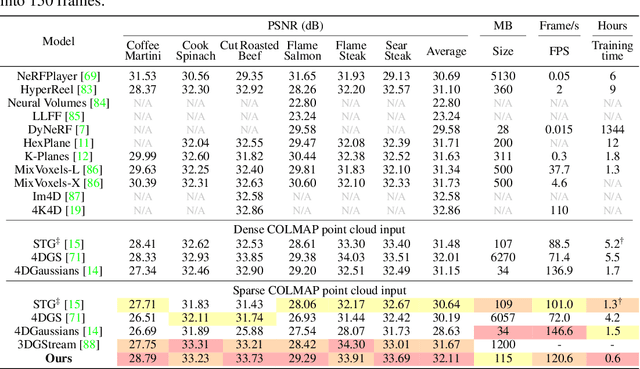
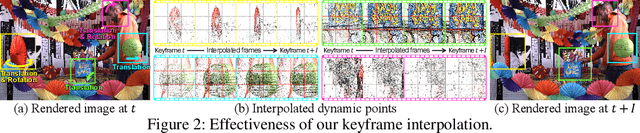
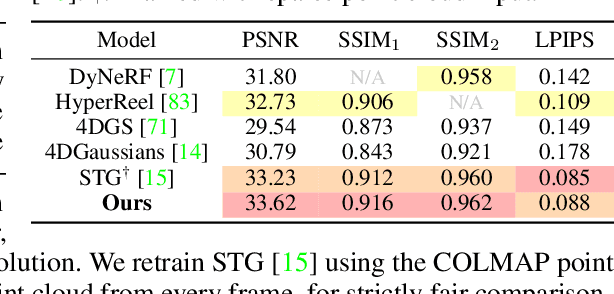
3D Gaussian Splatting has shown fast and high-quality rendering results in static scenes by leveraging dense 3D prior and explicit representations. Unfortunately, the benefits of the prior and representation do not involve novel view synthesis for dynamic motions. Ironically, this is because the main barrier is the reliance on them, which requires increasing training and rendering times to account for dynamic motions. In this paper, we design a Explicit 4D Gaussian Splatting(Ex4DGS). Our key idea is to firstly separate static and dynamic Gaussians during training, and to explicitly sample positions and rotations of the dynamic Gaussians at sparse timestamps. The sampled positions and rotations are then interpolated to represent both spatially and temporally continuous motions of objects in dynamic scenes as well as reducing computational cost. Additionally, we introduce a progressive training scheme and a point-backtracking technique that improves Ex4DGS's convergence. We initially train Ex4DGS using short timestamps and progressively extend timestamps, which makes it work well with a few point clouds. The point-backtracking is used to quantify the cumulative error of each Gaussian over time, enabling the detection and removal of erroneous Gaussians in dynamic scenes. Comprehensive experiments on various scenes demonstrate the state-of-the-art rendering quality from our method, achieving fast rendering of 62 fps on a single 2080Ti GPU.
MonoGraspNet: 6-DoF Grasping with a Single RGB Image
Sep 26, 2022
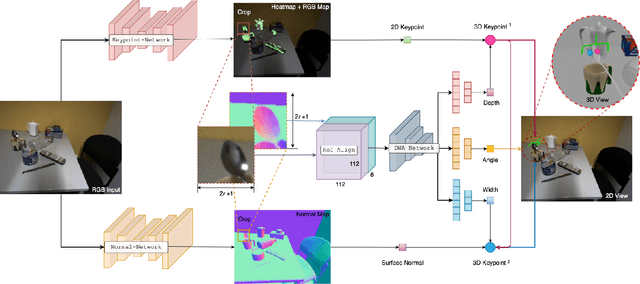
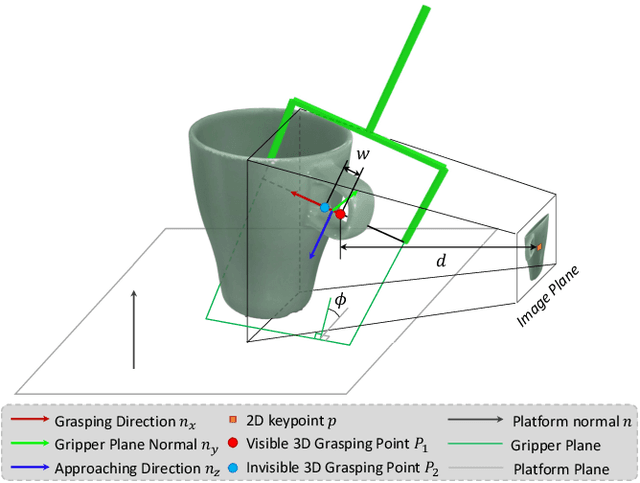

6-DoF robotic grasping is a long-lasting but unsolved problem. Recent methods utilize strong 3D networks to extract geometric grasping representations from depth sensors, demonstrating superior accuracy on common objects but perform unsatisfactorily on photometrically challenging objects, e.g., objects in transparent or reflective materials. The bottleneck lies in that the surface of these objects can not reflect back accurate depth due to the absorption or refraction of light. In this paper, in contrast to exploiting the inaccurate depth data, we propose the first RGB-only 6-DoF grasping pipeline called MonoGraspNet that utilizes stable 2D features to simultaneously handle arbitrary object grasping and overcome the problems induced by photometrically challenging objects. MonoGraspNet leverages keypoint heatmap and normal map to recover the 6-DoF grasping poses represented by our novel representation parameterized with 2D keypoints with corresponding depth, grasping direction, grasping width, and angle. Extensive experiments in real scenes demonstrate that our method can achieve competitive results in grasping common objects and surpass the depth-based competitor by a large margin in grasping photometrically challenging objects. To further stimulate robotic manipulation research, we additionally annotate and open-source a multi-view and multi-scene real-world grasping dataset, containing 120 objects of mixed photometric complexity with 20M accurate grasping labels.