 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelaxed Rigidity with Ray-based Grouping for Dynamic Gaussian Splatting
Mar 27, 2026The reconstruction of dynamic 3D scenes using 3D Gaussian Splatting has shown significant promise. A key challenge, however, remains in modeling realistic motion, as most methods fail to align the motion of Gaussians with real-world physical dynamics. This misalignment is particularly problematic for monocular video datasets, where failing to maintain coherent motion undermines local geometric structure, ultimately leading to degraded reconstruction quality. Consequently, many state-of-the-art approaches rely heavily on external priors, such as optical flow or 2D tracks, to enforce temporal coherence. In this work, we propose a novel method to explicitly preserve the local geometric structure of Gaussians across time in 4D scenes. Our core idea is to introduce a view-space ray grouping strategy that clusters Gaussians intersected by the same ray, considering only those whose $α$-blending weights exceed a threshold. We then apply constraints to these groups to maintain a consistent spatial distribution, effectively preserving their local geometry. This approach enforces a more physically plausible motion model by ensuring that local geometry remains stable over time, eliminating the reliance on external guidance. We demonstrate the efficacy of our method by integrating it into two distinct baseline models. Extensive experiments on challenging monocular datasets show that our approach significantly outperforms existing methods, achieving superior temporal consistency and reconstruction quality.
Continuous Locomotive Crowd Behavior Generation
Apr 07, 2025



Modeling and reproducing crowd behaviors are important in various domains including psychology, robotics, transport engineering and virtual environments. Conventional methods have focused on synthesizing momentary scenes, which have difficulty in replicating the continuous nature of real-world crowds. In this paper, we introduce a novel method for automatically generating continuous, realistic crowd trajectories with heterogeneous behaviors and interactions among individuals. We first design a crowd emitter model. To do this, we obtain spatial layouts from single input images, including a segmentation map, appearance map, population density map and population probability, prior to crowd generation. The emitter then continually places individuals on the timeline by assigning independent behavior characteristics such as agents' type, pace, and start/end positions using diffusion models. Next, our crowd simulator produces their long-term locomotions. To simulate diverse actions, it can augment their behaviors based on a Markov chain. As a result, our overall framework populates the scenes with heterogeneous crowd behaviors by alternating between the proposed emitter and simulator. Note that all the components in the proposed framework are user-controllable. Lastly, we propose a benchmark protocol to evaluate the realism and quality of the generated crowds in terms of the scene-level population dynamics and the individual-level trajectory accuracy. We demonstrate that our approach effectively models diverse crowd behavior patterns and generalizes well across different geographical environments. Code is publicly available at https://github.com/InhwanBae/CrowdES .
Fully Explicit Dynamic Gaussian Splatting
Oct 21, 2024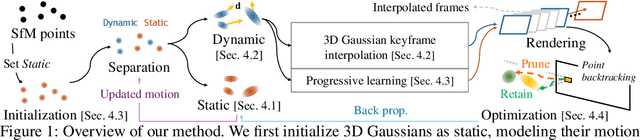
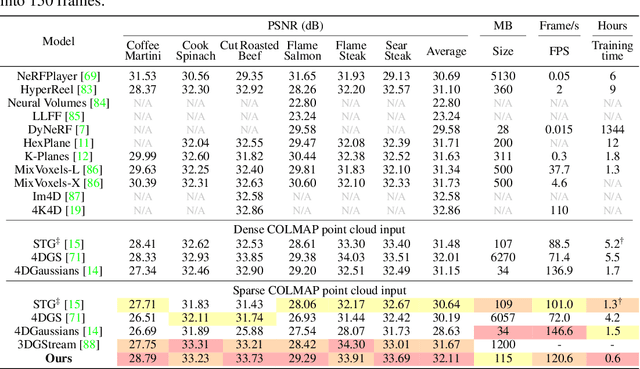
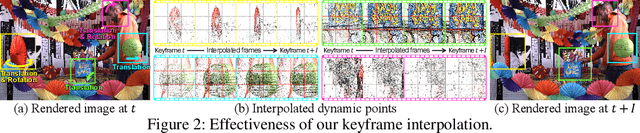
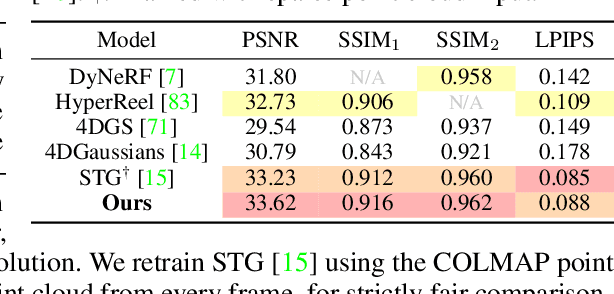
3D Gaussian Splatting has shown fast and high-quality rendering results in static scenes by leveraging dense 3D prior and explicit representations. Unfortunately, the benefits of the prior and representation do not involve novel view synthesis for dynamic motions. Ironically, this is because the main barrier is the reliance on them, which requires increasing training and rendering times to account for dynamic motions. In this paper, we design a Explicit 4D Gaussian Splatting(Ex4DGS). Our key idea is to firstly separate static and dynamic Gaussians during training, and to explicitly sample positions and rotations of the dynamic Gaussians at sparse timestamps. The sampled positions and rotations are then interpolated to represent both spatially and temporally continuous motions of objects in dynamic scenes as well as reducing computational cost. Additionally, we introduce a progressive training scheme and a point-backtracking technique that improves Ex4DGS's convergence. We initially train Ex4DGS using short timestamps and progressively extend timestamps, which makes it work well with a few point clouds. The point-backtracking is used to quantify the cumulative error of each Gaussian over time, enabling the detection and removal of erroneous Gaussians in dynamic scenes. Comprehensive experiments on various scenes demonstrate the state-of-the-art rendering quality from our method, achieving fast rendering of 62 fps on a single 2080Ti GPU.
Depth Prompting for Sensor-Agnostic Depth Estimation
May 20, 2024
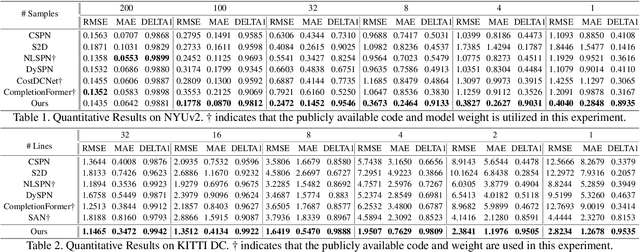
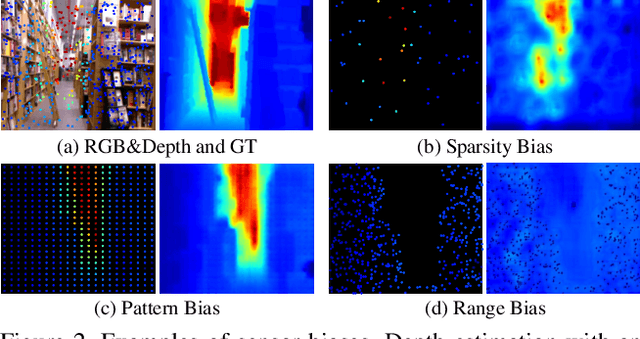

Dense depth maps have been used as a key element of visual perception tasks. There have been tremendous efforts to enhance the depth quality, ranging from optimization-based to learning-based methods. Despite the remarkable progress for a long time, their applicability in the real world is limited due to systematic measurement biases such as density, sensing pattern, and scan range. It is well-known that the biases make it difficult for these methods to achieve their generalization. We observe that learning a joint representation for input modalities (e.g., images and depth), which most recent methods adopt, is sensitive to the biases. In this work, we disentangle those modalities to mitigate the biases with prompt engineering. For this, we design a novel depth prompt module to allow the desirable feature representation according to new depth distributions from either sensor types or scene configurations. Our depth prompt can be embedded into foundation models for monocular depth estimation. Through this embedding process, our method helps the pretrained model to be free from restraint of depth scan range and to provide absolute scale depth maps. We demonstrate the effectiveness of our method through extensive evaluations. Source code is publicly available at https://github.com/JinhwiPark/DepthPrompting .
Can Language Beat Numerical Regression? Language-Based Multimodal Trajectory Prediction
Mar 27, 2024Language models have demonstrated impressive ability in context understanding and generative performance. Inspired by the recent success of language foundation models, in this paper, we propose LMTraj (Language-based Multimodal Trajectory predictor), which recasts the trajectory prediction task into a sort of question-answering problem. Departing from traditional numerical regression models, which treat the trajectory coordinate sequence as continuous signals, we consider them as discrete signals like text prompts. Specially, we first transform an input space for the trajectory coordinate into the natural language space. Here, the entire time-series trajectories of pedestrians are converted into a text prompt, and scene images are described as text information through image captioning. The transformed numerical and image data are then wrapped into the question-answering template for use in a language model. Next, to guide the language model in understanding and reasoning high-level knowledge, such as scene context and social relationships between pedestrians, we introduce an auxiliary multi-task question and answering. We then train a numerical tokenizer with the prompt data. We encourage the tokenizer to separate the integer and decimal parts well, and leverage it to capture correlations between the consecutive numbers in the language model. Lastly, we train the language model using the numerical tokenizer and all of the question-answer prompts. Here, we propose a beam-search-based most-likely prediction and a temperature-based multimodal prediction to implement both deterministic and stochastic inferences. Applying our LMTraj, we show that the language-based model can be a powerful pedestrian trajectory predictor, and outperforms existing numerical-based predictor methods. Code is publicly available at https://github.com/inhwanbae/LMTrajectory .