 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComPose: When to Trust Hands for Object Pose Tracking
May 22, 2026Reconstructing the motion of objects from videos is a key component for embodied AI and robot manipulation. While diverse approaches to object pose tracking have been studied, they rely heavily on strong external priors, such as depth data or 3D templates, and remain highly vulnerable to severe occlusions by hand grasps despite the use of explicit masks. In this work, we present ComPose, a 6DoF object tracking framework designed for hand-aware object pose estimation from RGB video. Rather than treating the hand purely as an occluder, our method harmonizes hand motions as a \textit{complementary cue} for object tracking. In detail, we recover a variety of object motions over time by combining object and hand cues from foundation models within a unified tracking pipeline. Here, ComPose adaptively selects informative hand joints, combines object- and hand-derived cues for motion estimation, and refines the resulting object motion using visible geometric evidence and a learned correction. We further enforce the temporal consistency over both rotation and translation, yielding stable 3D object trajectories over time without any external smoothing. Extensive experiments show that our method is accurate, efficient, and robust under severe hand occlusion and geometric ambiguity. In addition, the resulting trajectories can also effectively transfer to downstream robot manipulation by enabling robots to reconstruct human actions from online videos.
Relaxed Rigidity with Ray-based Grouping for Dynamic Gaussian Splatting
Mar 27, 2026The reconstruction of dynamic 3D scenes using 3D Gaussian Splatting has shown significant promise. A key challenge, however, remains in modeling realistic motion, as most methods fail to align the motion of Gaussians with real-world physical dynamics. This misalignment is particularly problematic for monocular video datasets, where failing to maintain coherent motion undermines local geometric structure, ultimately leading to degraded reconstruction quality. Consequently, many state-of-the-art approaches rely heavily on external priors, such as optical flow or 2D tracks, to enforce temporal coherence. In this work, we propose a novel method to explicitly preserve the local geometric structure of Gaussians across time in 4D scenes. Our core idea is to introduce a view-space ray grouping strategy that clusters Gaussians intersected by the same ray, considering only those whose $α$-blending weights exceed a threshold. We then apply constraints to these groups to maintain a consistent spatial distribution, effectively preserving their local geometry. This approach enforces a more physically plausible motion model by ensuring that local geometry remains stable over time, eliminating the reliance on external guidance. We demonstrate the efficacy of our method by integrating it into two distinct baseline models. Extensive experiments on challenging monocular datasets show that our approach significantly outperforms existing methods, achieving superior temporal consistency and reconstruction quality.
Continuous Locomotive Crowd Behavior Generation
Apr 07, 2025



Modeling and reproducing crowd behaviors are important in various domains including psychology, robotics, transport engineering and virtual environments. Conventional methods have focused on synthesizing momentary scenes, which have difficulty in replicating the continuous nature of real-world crowds. In this paper, we introduce a novel method for automatically generating continuous, realistic crowd trajectories with heterogeneous behaviors and interactions among individuals. We first design a crowd emitter model. To do this, we obtain spatial layouts from single input images, including a segmentation map, appearance map, population density map and population probability, prior to crowd generation. The emitter then continually places individuals on the timeline by assigning independent behavior characteristics such as agents' type, pace, and start/end positions using diffusion models. Next, our crowd simulator produces their long-term locomotions. To simulate diverse actions, it can augment their behaviors based on a Markov chain. As a result, our overall framework populates the scenes with heterogeneous crowd behaviors by alternating between the proposed emitter and simulator. Note that all the components in the proposed framework are user-controllable. Lastly, we propose a benchmark protocol to evaluate the realism and quality of the generated crowds in terms of the scene-level population dynamics and the individual-level trajectory accuracy. We demonstrate that our approach effectively models diverse crowd behavior patterns and generalizes well across different geographical environments. Code is publicly available at https://github.com/InhwanBae/CrowdES .
Fully Explicit Dynamic Gaussian Splatting
Oct 21, 2024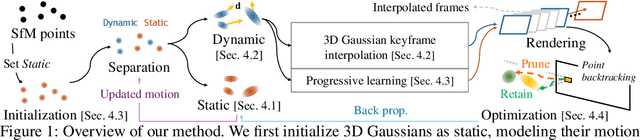
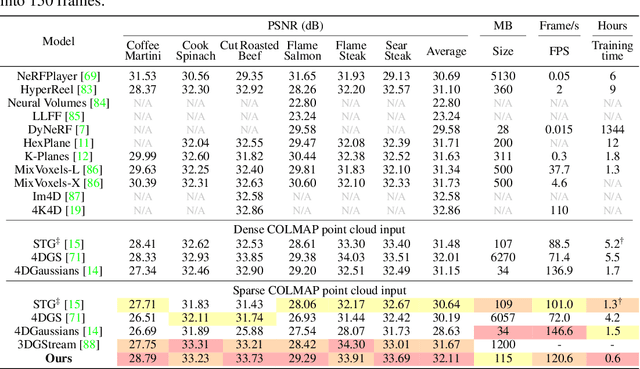
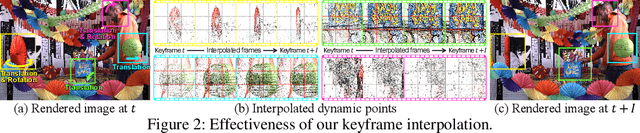
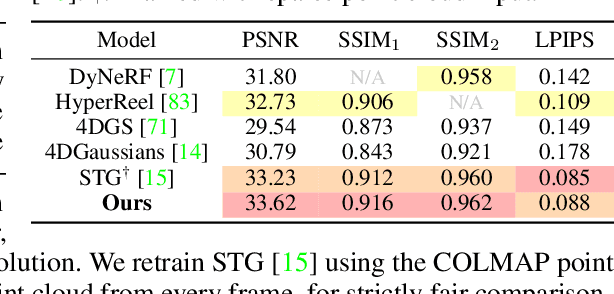
3D Gaussian Splatting has shown fast and high-quality rendering results in static scenes by leveraging dense 3D prior and explicit representations. Unfortunately, the benefits of the prior and representation do not involve novel view synthesis for dynamic motions. Ironically, this is because the main barrier is the reliance on them, which requires increasing training and rendering times to account for dynamic motions. In this paper, we design a Explicit 4D Gaussian Splatting(Ex4DGS). Our key idea is to firstly separate static and dynamic Gaussians during training, and to explicitly sample positions and rotations of the dynamic Gaussians at sparse timestamps. The sampled positions and rotations are then interpolated to represent both spatially and temporally continuous motions of objects in dynamic scenes as well as reducing computational cost. Additionally, we introduce a progressive training scheme and a point-backtracking technique that improves Ex4DGS's convergence. We initially train Ex4DGS using short timestamps and progressively extend timestamps, which makes it work well with a few point clouds. The point-backtracking is used to quantify the cumulative error of each Gaussian over time, enabling the detection and removal of erroneous Gaussians in dynamic scenes. Comprehensive experiments on various scenes demonstrate the state-of-the-art rendering quality from our method, achieving fast rendering of 62 fps on a single 2080Ti GPU.
Kinetic Typography Diffusion Model
Jul 15, 2024



This paper introduces a method for realistic kinetic typography that generates user-preferred animatable 'text content'. We draw on recent advances in guided video diffusion models to achieve visually-pleasing text appearances. To do this, we first construct a kinetic typography dataset, comprising about 600K videos. Our dataset is made from a variety of combinations in 584 templates designed by professional motion graphics designers and involves changing each letter's position, glyph, and size (i.e., flying, glitches, chromatic aberration, reflecting effects, etc.). Next, we propose a video diffusion model for kinetic typography. For this, there are three requirements: aesthetic appearances, motion effects, and readable letters. This paper identifies the requirements. For this, we present static and dynamic captions used as spatial and temporal guidance of a video diffusion model, respectively. The static caption describes the overall appearance of the video, such as colors, texture and glyph which represent a shape of each letter. The dynamic caption accounts for the movements of letters and backgrounds. We add one more guidance with zero convolution to determine which text content should be visible in the video. We apply the zero convolution to the text content, and impose it on the diffusion model. Lastly, our glyph loss, only minimizing a difference between the predicted word and its ground-truth, is proposed to make the prediction letters readable. Experiments show that our model generates kinetic typography videos with legible and artistic letter motions based on text prompts.
Can Language Beat Numerical Regression? Language-Based Multimodal Trajectory Prediction
Mar 27, 2024Language models have demonstrated impressive ability in context understanding and generative performance. Inspired by the recent success of language foundation models, in this paper, we propose LMTraj (Language-based Multimodal Trajectory predictor), which recasts the trajectory prediction task into a sort of question-answering problem. Departing from traditional numerical regression models, which treat the trajectory coordinate sequence as continuous signals, we consider them as discrete signals like text prompts. Specially, we first transform an input space for the trajectory coordinate into the natural language space. Here, the entire time-series trajectories of pedestrians are converted into a text prompt, and scene images are described as text information through image captioning. The transformed numerical and image data are then wrapped into the question-answering template for use in a language model. Next, to guide the language model in understanding and reasoning high-level knowledge, such as scene context and social relationships between pedestrians, we introduce an auxiliary multi-task question and answering. We then train a numerical tokenizer with the prompt data. We encourage the tokenizer to separate the integer and decimal parts well, and leverage it to capture correlations between the consecutive numbers in the language model. Lastly, we train the language model using the numerical tokenizer and all of the question-answer prompts. Here, we propose a beam-search-based most-likely prediction and a temperature-based multimodal prediction to implement both deterministic and stochastic inferences. Applying our LMTraj, we show that the language-based model can be a powerful pedestrian trajectory predictor, and outperforms existing numerical-based predictor methods. Code is publicly available at https://github.com/inhwanbae/LMTrajectory .
SingularTrajectory: Universal Trajectory Predictor Using Diffusion Model
Mar 27, 2024There are five types of trajectory prediction tasks: deterministic, stochastic, domain adaptation, momentary observation, and few-shot. These associated tasks are defined by various factors, such as the length of input paths, data split and pre-processing methods. Interestingly, even though they commonly take sequential coordinates of observations as input and infer future paths in the same coordinates as output, designing specialized architectures for each task is still necessary. For the other task, generality issues can lead to sub-optimal performances. In this paper, we propose SingularTrajectory, a diffusion-based universal trajectory prediction framework to reduce the performance gap across the five tasks. The core of SingularTrajectory is to unify a variety of human dynamics representations on the associated tasks. To do this, we first build a Singular space to project all types of motion patterns from each task into one embedding space. We next propose an adaptive anchor working in the Singular space. Unlike traditional fixed anchor methods that sometimes yield unacceptable paths, our adaptive anchor enables correct anchors, which are put into a wrong location, based on a traversability map. Finally, we adopt a diffusion-based predictor to further enhance the prototype paths using a cascaded denoising process. Our unified framework ensures the generality across various benchmark settings such as input modality, and trajectory lengths. Extensive experiments on five public benchmarks demonstrate that SingularTrajectory substantially outperforms existing models, highlighting its effectiveness in estimating general dynamics of human movements. Code is publicly available at https://github.com/inhwanbae/SingularTrajectory .
EigenTrajectory: Low-Rank Descriptors for Multi-Modal Trajectory Forecasting
Jul 18, 2023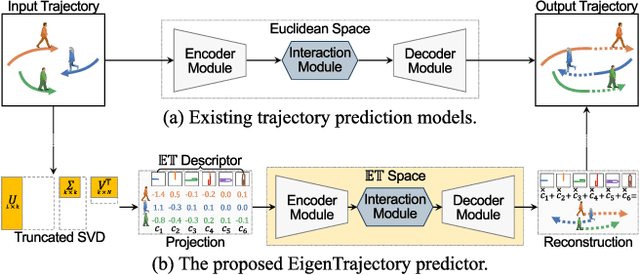



Capturing high-dimensional social interactions and feasible futures is essential for predicting trajectories. To address this complex nature, several attempts have been devoted to reducing the dimensionality of the output variables via parametric curve fitting such as the B\'ezier curve and B-spline function. However, these functions, which originate in computer graphics fields, are not suitable to account for socially acceptable human dynamics. In this paper, we present EigenTrajectory ($\mathbb{ET}$), a trajectory prediction approach that uses a novel trajectory descriptor to form a compact space, known here as $\mathbb{ET}$ space, in place of Euclidean space, for representing pedestrian movements. We first reduce the complexity of the trajectory descriptor via a low-rank approximation. We transform the pedestrians' history paths into our $\mathbb{ET}$ space represented by spatio-temporal principle components, and feed them into off-the-shelf trajectory forecasting models. The inputs and outputs of the models as well as social interactions are all gathered and aggregated in the corresponding $\mathbb{ET}$ space. Lastly, we propose a trajectory anchor-based refinement method to cover all possible futures in the proposed $\mathbb{ET}$ space. Extensive experiments demonstrate that our EigenTrajectory predictor can significantly improve both the prediction accuracy and reliability of existing trajectory forecasting models on public benchmarks, indicating that the proposed descriptor is suited to represent pedestrian behaviors. Code is publicly available at https://github.com/inhwanbae/EigenTrajectory .
Learning Pedestrian Group Representations for Multi-modal Trajectory Prediction
Jul 20, 2022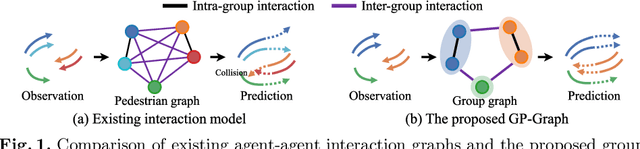
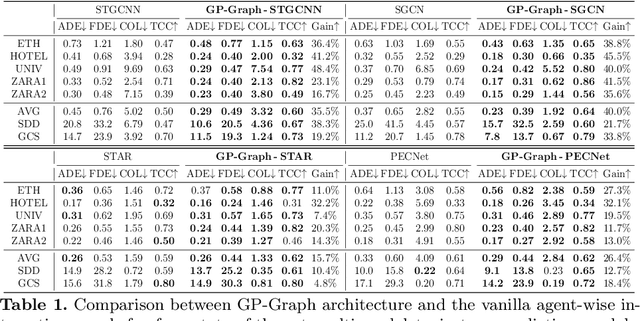
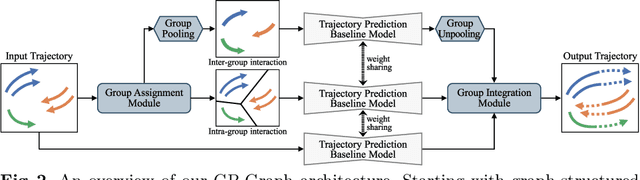

Modeling the dynamics of people walking is a problem of long-standing interest in computer vision. Many previous works involving pedestrian trajectory prediction define a particular set of individual actions to implicitly model group actions. In this paper, we present a novel architecture named GP-Graph which has collective group representations for effective pedestrian trajectory prediction in crowded environments, and is compatible with all types of existing approaches. A key idea of GP-Graph is to model both individual-wise and group-wise relations as graph representations. To do this, GP-Graph first learns to assign each pedestrian into the most likely behavior group. Using this assignment information, GP-Graph then forms both intra- and inter-group interactions as graphs, accounting for human-human relations within a group and group-group relations, respectively. To be specific, for the intra-group interaction, we mask pedestrian graph edges out of an associated group. We also propose group pooling&unpooling operations to represent a group with multiple pedestrians as one graph node. Lastly, GP-Graph infers a probability map for socially-acceptable future trajectories from the integrated features of both group interactions. Moreover, we introduce a group-level latent vector sampling to ensure collective inferences over a set of possible future trajectories. Extensive experiments are conducted to validate the effectiveness of our architecture, which demonstrates consistent performance improvements with publicly available benchmarks. Code is publicly available at https://github.com/inhwanbae/GPGraph.
Non-Probability Sampling Network for Stochastic Human Trajectory Prediction
Mar 25, 2022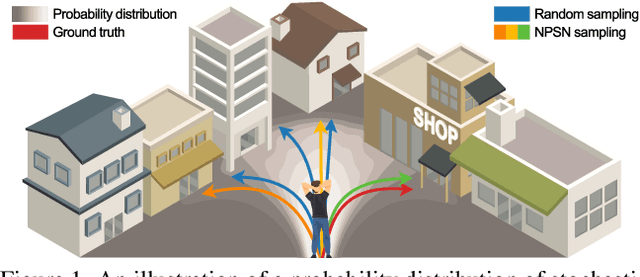
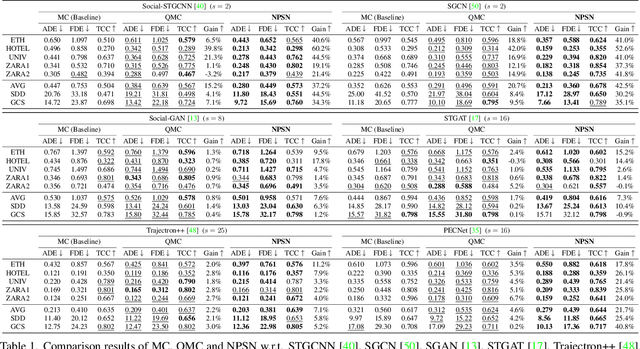
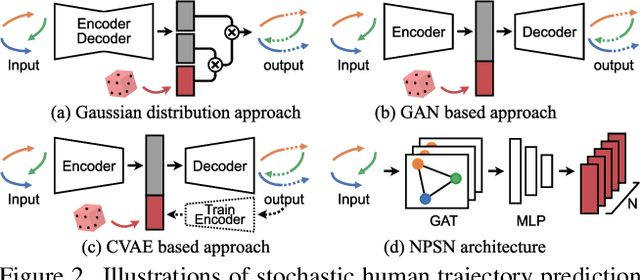
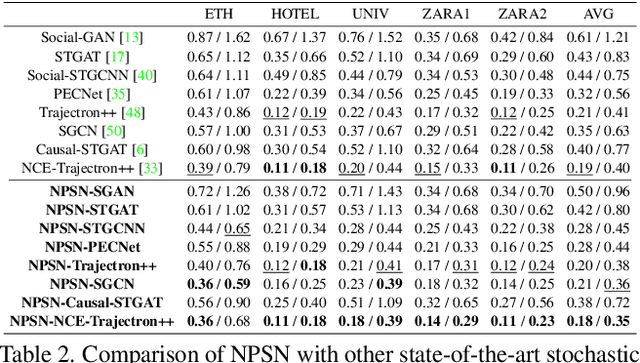
Capturing multimodal natures is essential for stochastic pedestrian trajectory prediction, to infer a finite set of future trajectories. The inferred trajectories are based on observation paths and the latent vectors of potential decisions of pedestrians in the inference step. However, stochastic approaches provide varying results for the same data and parameter settings, due to the random sampling of the latent vector. In this paper, we analyze the problem by reconstructing and comparing probabilistic distributions from prediction samples and socially-acceptable paths, respectively. Through this analysis, we observe that the inferences of all stochastic models are biased toward the random sampling, and fail to generate a set of realistic paths from finite samples. The problem cannot be resolved unless an infinite number of samples is available, which is infeasible in practice. We introduce that the Quasi-Monte Carlo (QMC) method, ensuring uniform coverage on the sampling space, as an alternative to the conventional random sampling. With the same finite number of samples, the QMC improves all the multimodal prediction results. We take an additional step ahead by incorporating a learnable sampling network into the existing networks for trajectory prediction. For this purpose, we propose the Non-Probability Sampling Network (NPSN), a very small network (~5K parameters) that generates purposive sample sequences using the past paths of pedestrians and their social interactions. Extensive experiments confirm that NPSN can significantly improve both the prediction accuracy (up to 60%) and reliability of the public pedestrian trajectory prediction benchmark. Code is publicly available at https://github.com/inhwanbae/NPSN .