 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowing from Reasoning to Motion: Learning 3D Hand Trajectory Prediction from Egocentric Human Interaction Videos
Dec 18, 2025Prior works on 3D hand trajectory prediction are constrained by datasets that decouple motion from semantic supervision and by models that weakly link reasoning and action. To address these, we first present the EgoMAN dataset, a large-scale egocentric dataset for interaction stage-aware 3D hand trajectory prediction with 219K 6DoF trajectories and 3M structured QA pairs for semantic, spatial, and motion reasoning. We then introduce the EgoMAN model, a reasoning-to-motion framework that links vision-language reasoning and motion generation via a trajectory-token interface. Trained progressively to align reasoning with motion dynamics, our approach yields accurate and stage-aware trajectories with generalization across real-world scenes.
Mesh2NeRF: Direct Mesh Supervision for Neural Radiance Field Representation and Generation
Mar 28, 2024We present Mesh2NeRF, an approach to derive ground-truth radiance fields from textured meshes for 3D generation tasks. Many 3D generative approaches represent 3D scenes as radiance fields for training. Their ground-truth radiance fields are usually fitted from multi-view renderings from a large-scale synthetic 3D dataset, which often results in artifacts due to occlusions or under-fitting issues. In Mesh2NeRF, we propose an analytic solution to directly obtain ground-truth radiance fields from 3D meshes, characterizing the density field with an occupancy function featuring a defined surface thickness, and determining view-dependent color through a reflection function considering both the mesh and environment lighting. Mesh2NeRF extracts accurate radiance fields which provides direct supervision for training generative NeRFs and single scene representation. We validate the effectiveness of Mesh2NeRF across various tasks, achieving a noteworthy 3.12dB improvement in PSNR for view synthesis in single scene representation on the ABO dataset, a 0.69 PSNR enhancement in the single-view conditional generation of ShapeNet Cars, and notably improved mesh extraction from NeRF in the unconditional generation of Objaverse Mugs.
PHRIT: Parametric Hand Representation with Implicit Template
Sep 26, 2023



We propose PHRIT, a novel approach for parametric hand mesh modeling with an implicit template that combines the advantages of both parametric meshes and implicit representations. Our method represents deformable hand shapes using signed distance fields (SDFs) with part-based shape priors, utilizing a deformation field to execute the deformation. The model offers efficient high-fidelity hand reconstruction by deforming the canonical template at infinite resolution. Additionally, it is fully differentiable and can be easily used in hand modeling since it can be driven by the skeleton and shape latent codes. We evaluate PHRIT on multiple downstream tasks, including skeleton-driven hand reconstruction, shapes from point clouds, and single-view 3D reconstruction, demonstrating that our approach achieves realistic and immersive hand modeling with state-of-the-art performance.
S4R: Self-Supervised Semantic Scene Reconstruction from RGB-D Scans
Feb 21, 2023



Most deep learning approaches to comprehensive semantic modeling of 3D indoor spaces require costly dense annotations in the 3D domain. In this work, we explore a central 3D scene modeling task, namely, semantic scene reconstruction, using a fully self-supervised approach. To this end, we design a trainable model that employs both incomplete 3D reconstructions and their corresponding source RGB-D images, fusing cross-domain features into volumetric embeddings to predict complete 3D geometry, color, and semantics. Our key technical innovation is to leverage differentiable rendering of color and semantics, using the observed RGB images and a generic semantic segmentation model as color and semantics supervision, respectively. We additionally develop a method to synthesize an augmented set of virtual training views complementing the original real captures, enabling more efficient self-supervision for semantics. In this work we propose an end-to-end trainable solution jointly addressing geometry completion, colorization, and semantic mapping from a few RGB-D images, without 3D or 2D ground-truth. Our method is the first, to our knowledge, fully self-supervised method addressing completion and semantic segmentation of real-world 3D scans. It performs comparably well with the 3D supervised baselines, surpasses baselines with 2D supervision on real datasets, and generalizes well to unseen scenes.
MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video
Mar 27, 2022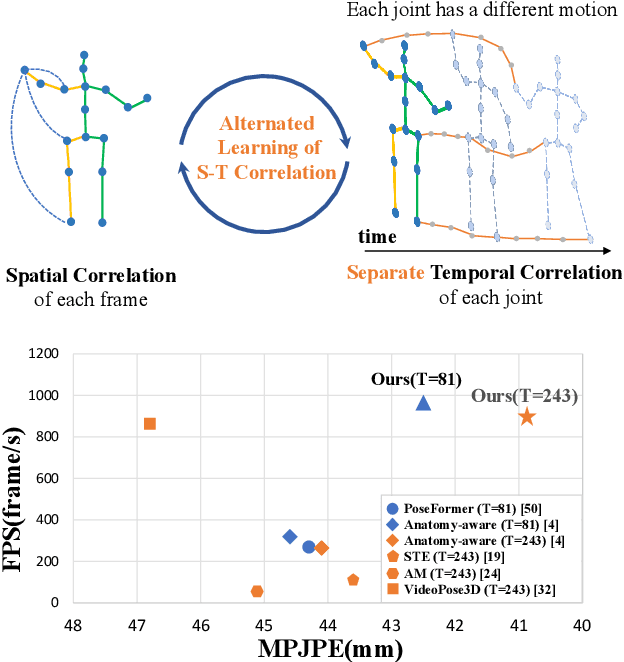

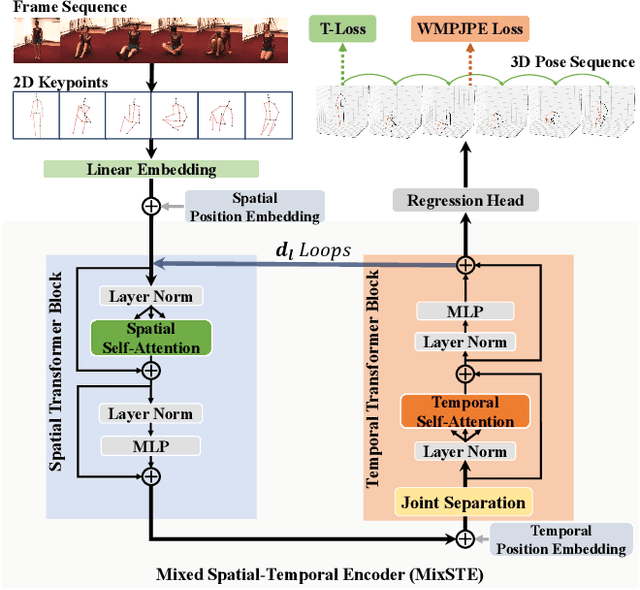

Recent transformer-based solutions have been introduced to estimate 3D human pose from 2D keypoint sequence by considering body joints among all frames globally to learn spatio-temporal correlation. We observe that the motions of different joints differ significantly. However, the previous methods cannot efficiently model the solid inter-frame correspondence of each joint, leading to insufficient learning of spatial-temporal correlation. We propose MixSTE (Mixed Spatio-Temporal Encoder), which has a temporal transformer block to separately model the temporal motion of each joint and a spatial transformer block to learn inter-joint spatial correlation. These two blocks are utilized alternately to obtain better spatio-temporal feature encoding. In addition, the network output is extended from the central frame to entire frames of the input video, thereby improving the coherence between the input and output sequences. Extensive experiments are conducted on three benchmarks (Human3.6M, MPI-INF-3DHP, and HumanEva). The results show that our model outperforms the state-of-the-art approach by 10.9% P-MPJPE and 7.6% MPJPE. The code is available at https://github.com/JinluZhang1126/MixSTE.
Joint-bone Fusion Graph Convolutional Network for Semi-supervised Skeleton Action Recognition
Feb 08, 2022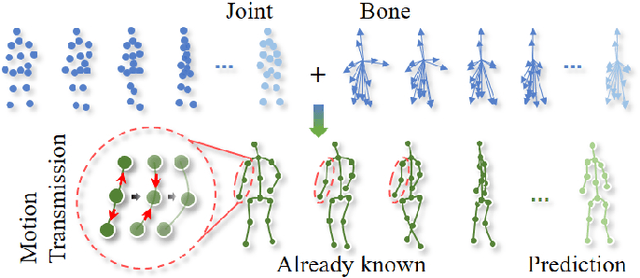
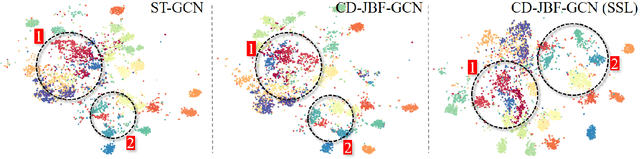
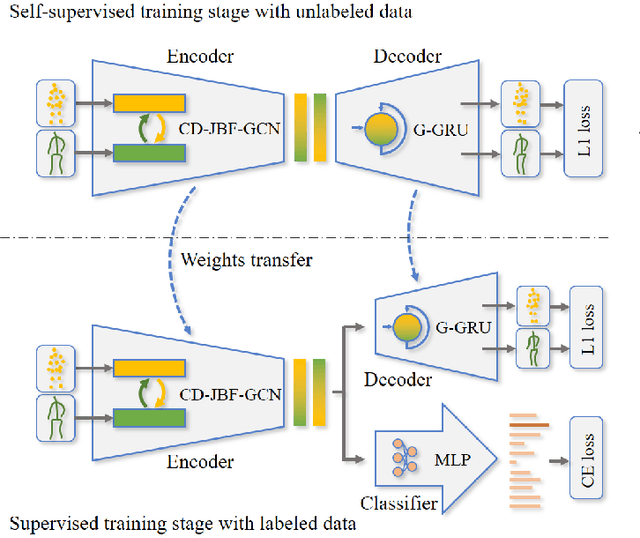
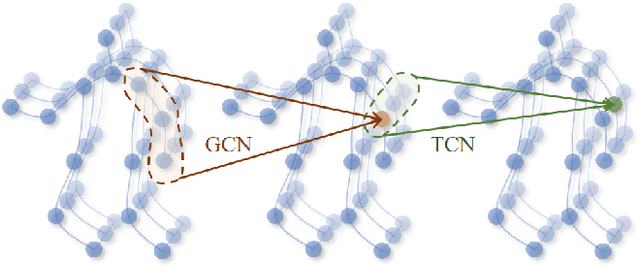
In recent years, graph convolutional networks (GCNs) play an increasingly critical role in skeleton-based human action recognition. However, most GCN-based methods still have two main limitations: 1) They only consider the motion information of the joints or process the joints and bones separately, which are unable to fully explore the latent functional correlation between joints and bones for action recognition. 2) Most of these works are performed in the supervised learning way, which heavily relies on massive labeled training data. To address these issues, we propose a semi-supervised skeleton-based action recognition method which has been rarely exploited before. We design a novel correlation-driven joint-bone fusion graph convolutional network (CD-JBF-GCN) as an encoder and use a pose prediction head as a decoder to achieve semi-supervised learning. Specifically, the CD-JBF-GC can explore the motion transmission between the joint stream and the bone stream, so that promoting both streams to learn more discriminative feature representations. The pose prediction based auto-encoder in the self-supervised training stage allows the network to learn motion representation from unlabeled data, which is essential for action recognition. Extensive experiments on two popular datasets, i.e. NTU-RGB+D and Kinetics-Skeleton, demonstrate that our model achieves the state-of-the-art performance for semi-supervised skeleton-based action recognition and is also useful for fully-supervised methods.
Consistent 3D Hand Reconstruction in Video via self-supervised Learning
Jan 24, 2022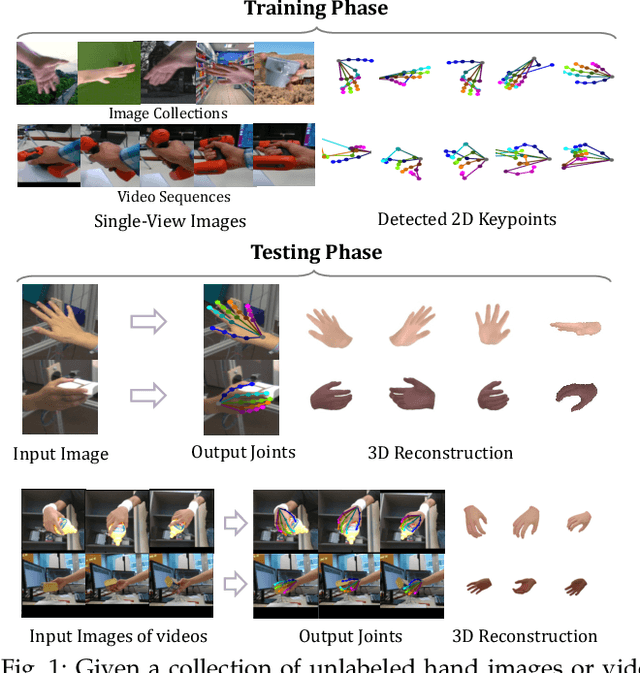
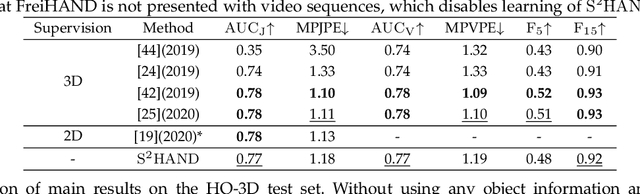
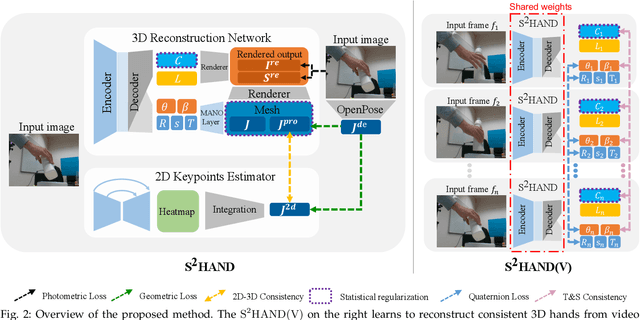
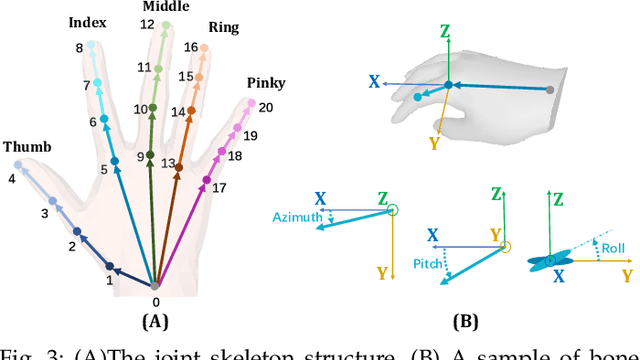
We present a method for reconstructing accurate and consistent 3D hands from a monocular video. We observe that detected 2D hand keypoints and the image texture provide important cues about the geometry and texture of the 3D hand, which can reduce or even eliminate the requirement on 3D hand annotation. Thus we propose ${\rm {S}^{2}HAND}$, a self-supervised 3D hand reconstruction model, that can jointly estimate pose, shape, texture, and the camera viewpoint from a single RGB input through the supervision of easily accessible 2D detected keypoints. We leverage the continuous hand motion information contained in the unlabeled video data and propose ${\rm {S}^{2}HAND(V)}$, which uses a set of weights shared ${\rm {S}^{2}HAND}$ to process each frame and exploits additional motion, texture, and shape consistency constrains to promote more accurate hand poses and more consistent shapes and textures. Experiments on benchmark datasets demonstrate that our self-supervised approach produces comparable hand reconstruction performance compared with the recent full-supervised methods in single-frame as input setup, and notably improves the reconstruction accuracy and consistency when using video training data.
4DContrast: Contrastive Learning with Dynamic Correspondences for 3D Scene Understanding
Dec 06, 2021


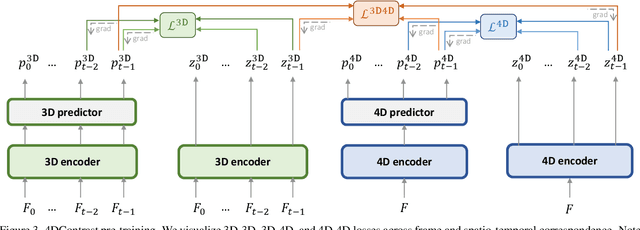
We present a new approach to instill 4D dynamic object priors into learned 3D representations by unsupervised pre-training. We observe that dynamic movement of an object through an environment provides important cues about its objectness, and thus propose to imbue learned 3D representations with such dynamic understanding, that can then be effectively transferred to improved performance in downstream 3D semantic scene understanding tasks. We propose a new data augmentation scheme leveraging synthetic 3D shapes moving in static 3D environments, and employ contrastive learning under 3D-4D constraints that encode 4D invariances into the learned 3D representations. Experiments demonstrate that our unsupervised representation learning results in improvement in downstream 3D semantic segmentation, object detection, and instance segmentation tasks, and moreover, notably improves performance in data-scarce scenarios.
Model-based 3D Hand Reconstruction via Self-Supervised Learning
Mar 22, 2021



Reconstructing a 3D hand from a single-view RGB image is challenging due to various hand configurations and depth ambiguity. To reliably reconstruct a 3D hand from a monocular image, most state-of-the-art methods heavily rely on 3D annotations at the training stage, but obtaining 3D annotations is expensive. To alleviate reliance on labeled training data, we propose S2HAND, a self-supervised 3D hand reconstruction network that can jointly estimate pose, shape, texture, and the camera viewpoint. Specifically, we obtain geometric cues from the input image through easily accessible 2D detected keypoints. To learn an accurate hand reconstruction model from these noisy geometric cues, we utilize the consistency between 2D and 3D representations and propose a set of novel losses to rationalize outputs of the neural network. For the first time, we demonstrate the feasibility of training an accurate 3D hand reconstruction network without relying on manual annotations. Our experiments show that the proposed method achieves comparable performance with recent fully-supervised methods while using fewer supervision data.
Joint Hand-object 3D Reconstruction from a Single Image with Cross-branch Feature Fusion
Jun 28, 2020

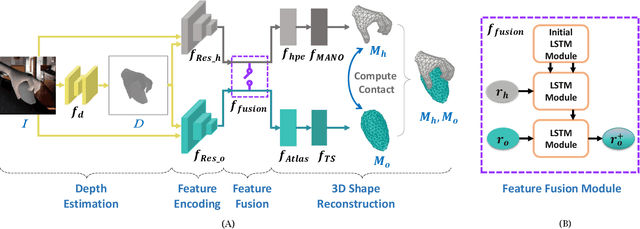

Accurate 3D reconstruction of the hand and object shape from a hand-object image is important for understanding human-object interaction as well as human daily activities. Different from bare hand pose estimation, hand-object interaction poses a strong constraint on both the hand and its manipulated object, which suggests that hand configuration may be crucial contextual information for the object, and vice versa. However, current approaches address this task by training a two-branch network to reconstruct the hand and object separately with little communication between the two branches. In this work, we propose to consider hand and object jointly in feature space and explore the reciprocity of the two branches. We extensively investigate cross-branch feature fusion architectures with MLP or LSTM units. Among the investigated architectures, a variant with LSTM units that enhances object feature with hand feature shows the best performance gain. Moreover, we employ an auxiliary depth estimation module to augment the input RGB image with the estimated depth map, which further improves the reconstruction accuracy. Experiments conducted on public datasets demonstrate that our approach significantly outperforms existing approaches in terms of the reconstruction accuracy of objects.