 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent 3D Hand Reconstruction in Video via self-supervised Learning
Paper and Code
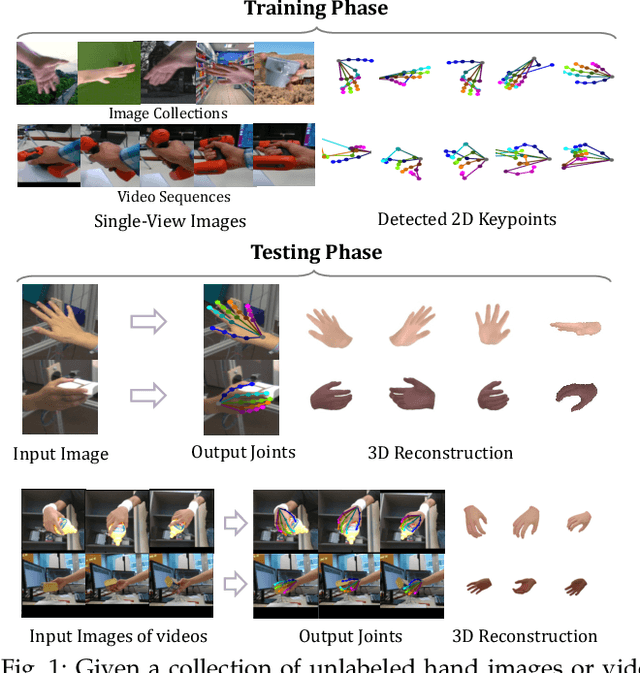
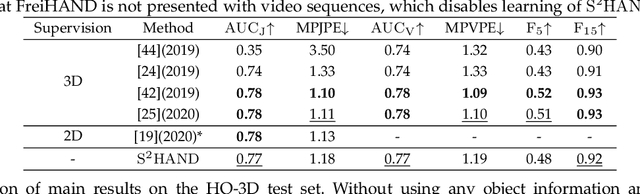
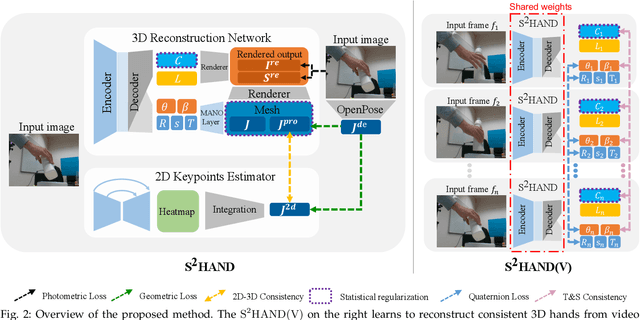
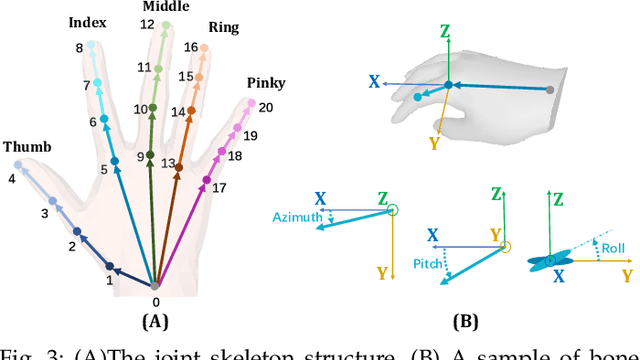
We present a method for reconstructing accurate and consistent 3D hands from a monocular video. We observe that detected 2D hand keypoints and the image texture provide important cues about the geometry and texture of the 3D hand, which can reduce or even eliminate the requirement on 3D hand annotation. Thus we propose ${\rm {S}^{2}HAND}$, a self-supervised 3D hand reconstruction model, that can jointly estimate pose, shape, texture, and the camera viewpoint from a single RGB input through the supervision of easily accessible 2D detected keypoints. We leverage the continuous hand motion information contained in the unlabeled video data and propose ${\rm {S}^{2}HAND(V)}$, which uses a set of weights shared ${\rm {S}^{2}HAND}$ to process each frame and exploits additional motion, texture, and shape consistency constrains to promote more accurate hand poses and more consistent shapes and textures. Experiments on benchmark datasets demonstrate that our self-supervised approach produces comparable hand reconstruction performance compared with the recent full-supervised methods in single-frame as input setup, and notably improves the reconstruction accuracy and consistency when using video training data.