 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint-bone Fusion Graph Convolutional Network for Semi-supervised Skeleton Action Recognition
Paper and Code
Feb 08, 2022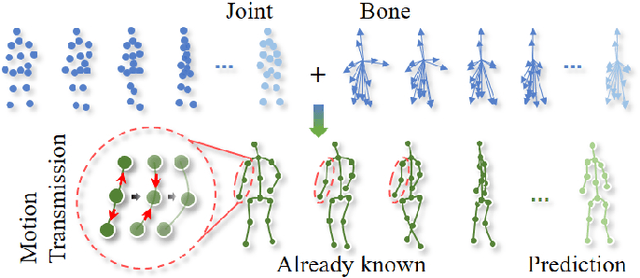
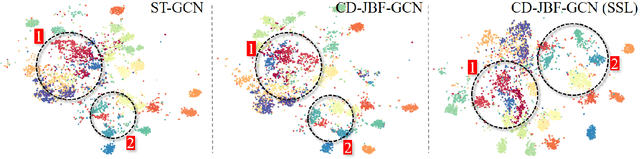
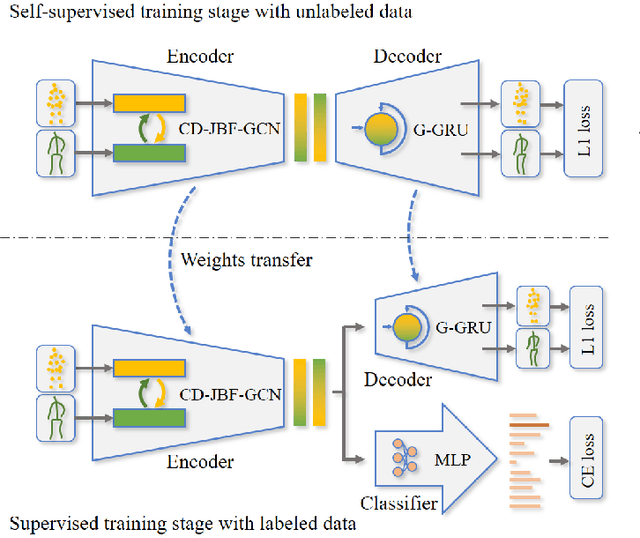
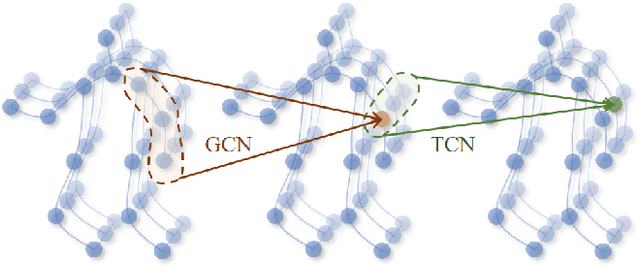
In recent years, graph convolutional networks (GCNs) play an increasingly critical role in skeleton-based human action recognition. However, most GCN-based methods still have two main limitations: 1) They only consider the motion information of the joints or process the joints and bones separately, which are unable to fully explore the latent functional correlation between joints and bones for action recognition. 2) Most of these works are performed in the supervised learning way, which heavily relies on massive labeled training data. To address these issues, we propose a semi-supervised skeleton-based action recognition method which has been rarely exploited before. We design a novel correlation-driven joint-bone fusion graph convolutional network (CD-JBF-GCN) as an encoder and use a pose prediction head as a decoder to achieve semi-supervised learning. Specifically, the CD-JBF-GC can explore the motion transmission between the joint stream and the bone stream, so that promoting both streams to learn more discriminative feature representations. The pose prediction based auto-encoder in the self-supervised training stage allows the network to learn motion representation from unlabeled data, which is essential for action recognition. Extensive experiments on two popular datasets, i.e. NTU-RGB+D and Kinetics-Skeleton, demonstrate that our model achieves the state-of-the-art performance for semi-supervised skeleton-based action recognition and is also useful for fully-supervised methods.