 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaGesture: Single-Reference Co-Speech Gesture Personalization for Unseen Speakers
May 07, 2026We propose PersonaGesture, a diffusion-based pipeline for single-reference co-speech gesture personalization of unseen speakers. Given target speech and one motion clip from a new speaker, the model must synthesize gestures that follow the new utterance while retaining speaker-specific pose choices, without per-speaker optimization. This setting is useful for avatars and virtual agents, but it is hard because the reference mixes stable speaker habits with utterance-specific trajectories. PersonaGesture consists of two key components, Adaptive Style Infusion (ASI) and Implicit Distribution Rectification (IDR), to separate temporal identity evidence from residual statistic correction. A Style Perceiver first encodes the variable-length reference into compact speaker-memory tokens. ASI injects these tokens into denoising through zero-initialized residual cross-attention, enabling style evidence to affect motion formation without replacing the pretrained speech-to-motion prior. Building on this, IDR applies a length-aware diagonal affine map in latent space to correct residual channel-wise moments estimated from the same reference. Across BEAT2 and ZeroEGGS, we evaluate quantitative metrics, reference-identity controls, same-audio diagnostics, qualitative comparisons, and human preference. Experiments show that separating denoising-time speaker memory from conservative post-generation moment correction improves unseen-speaker personalization over collapsed style codes, full-reference attention, and one-clip finetuning. Project: https://xiangyue-zhang.github.io/PersonaGesture.
FlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
Bridging Your Imagination with Audio-Video Generation via a Unified Director
Dec 29, 2025Existing AI-driven video creation systems typically treat script drafting and key-shot design as two disjoint tasks: the former relies on large language models, while the latter depends on image generation models. We argue that these two tasks should be unified within a single framework, as logical reasoning and imaginative thinking are both fundamental qualities of a film director. In this work, we propose UniMAGE, a unified director model that bridges user prompts with well-structured scripts, thereby empowering non-experts to produce long-context, multi-shot films by leveraging existing audio-video generation models. To achieve this, we employ the Mixture-of-Transformers architecture that unifies text and image generation. To further enhance narrative logic and keyframe consistency, we introduce a ``first interleaving, then disentangling'' training paradigm. Specifically, we first perform Interleaved Concept Learning, which utilizes interleaved text-image data to foster the model's deeper understanding and imaginative interpretation of scripts. We then conduct Disentangled Expert Learning, which decouples script writing from keyframe generation, enabling greater flexibility and creativity in storytelling. Extensive experiments demonstrate that UniMAGE achieves state-of-the-art performance among open-source models, generating logically coherent video scripts and visually consistent keyframe images.
Mitigating Error Accumulation in Co-Speech Motion Generation via Global Rotation Diffusion and Multi-Level Constraints
Nov 13, 2025Reliable co-speech motion generation requires precise motion representation and consistent structural priors across all joints. Existing generative methods typically operate on local joint rotations, which are defined hierarchically based on the skeleton structure. This leads to cumulative errors during generation, manifesting as unstable and implausible motions at end-effectors. In this work, we propose GlobalDiff, a diffusion-based framework that operates directly in the space of global joint rotations for the first time, fundamentally decoupling each joint's prediction from upstream dependencies and alleviating hierarchical error accumulation. To compensate for the absence of structural priors in global rotation space, we introduce a multi-level constraint scheme. Specifically, a joint structure constraint introduces virtual anchor points around each joint to better capture fine-grained orientation. A skeleton structure constraint enforces angular consistency across bones to maintain structural integrity. A temporal structure constraint utilizes a multi-scale variational encoder to align the generated motion with ground-truth temporal patterns. These constraints jointly regularize the global diffusion process and reinforce structural awareness. Extensive evaluations on standard co-speech benchmarks show that GlobalDiff generates smooth and accurate motions, improving the performance by 46.0 % compared to the current SOTA under multiple speaker identities.
* AAAI 2026
DreamDance: Animating Character Art via Inpainting Stable Gaussian Worlds
May 30, 2025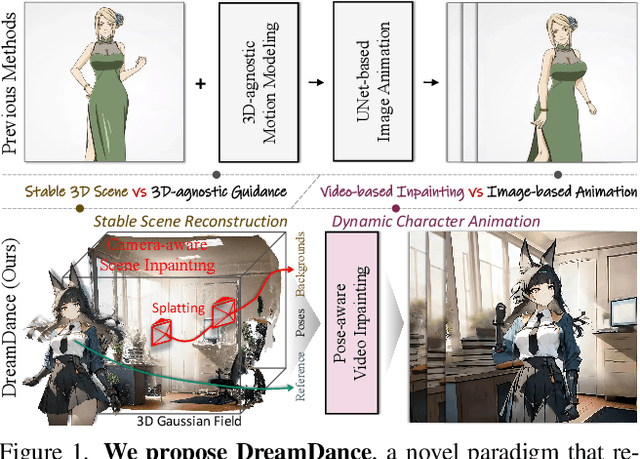

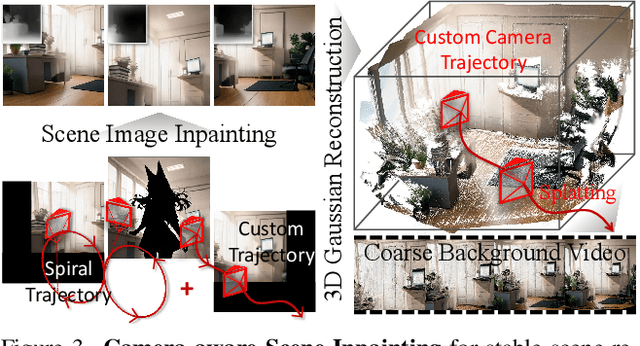
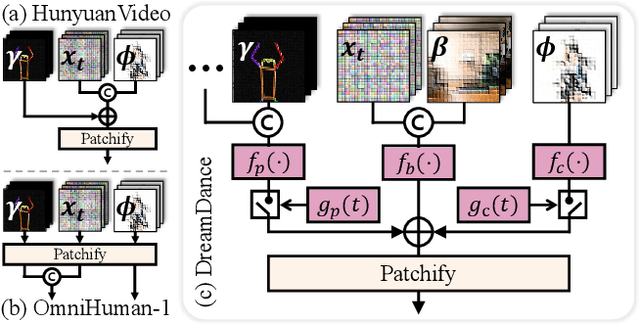
This paper presents DreamDance, a novel character art animation framework capable of producing stable, consistent character and scene motion conditioned on precise camera trajectories. To achieve this, we re-formulate the animation task as two inpainting-based steps: Camera-aware Scene Inpainting and Pose-aware Video Inpainting. The first step leverages a pre-trained image inpainting model to generate multi-view scene images from the reference art and optimizes a stable large-scale Gaussian field, which enables coarse background video rendering with camera trajectories. However, the rendered video is rough and only conveys scene motion. To resolve this, the second step trains a pose-aware video inpainting model that injects the dynamic character into the scene video while enhancing background quality. Specifically, this model is a DiT-based video generation model with a gating strategy that adaptively integrates the character's appearance and pose information into the base background video. Through extensive experiments, we demonstrate the effectiveness and generalizability of DreamDance, producing high-quality and consistent character animations with remarkable camera dynamics.
EchoMask: Speech-Queried Attention-based Mask Modeling for Holistic Co-Speech Motion Generation
Apr 15, 2025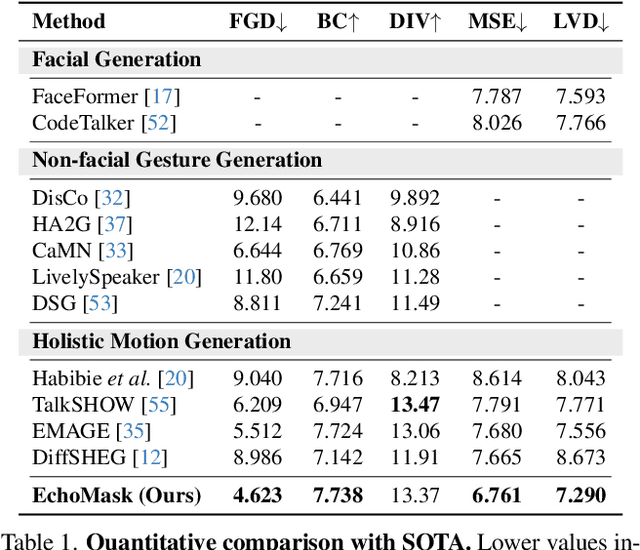
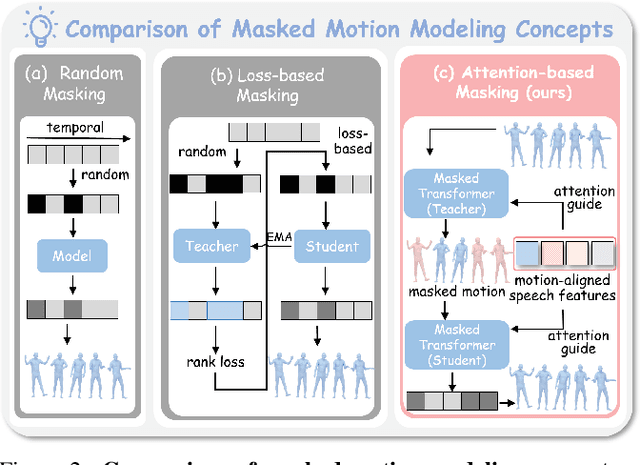
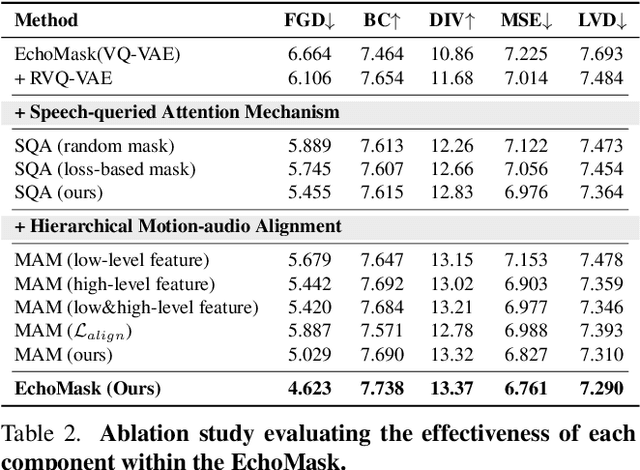
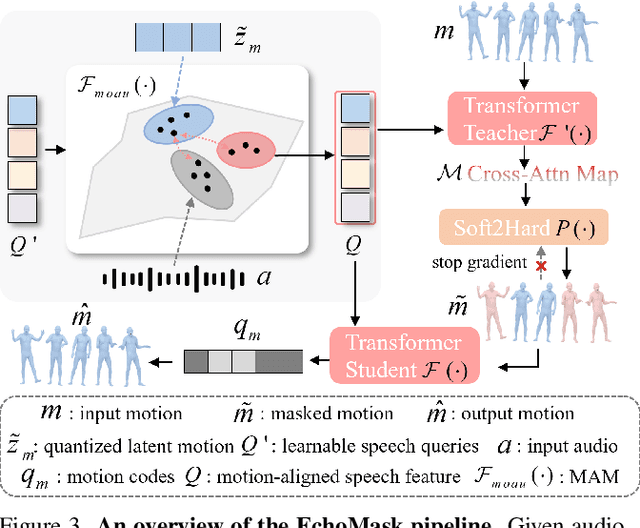
Masked modeling framework has shown promise in co-speech motion generation. However, it struggles to identify semantically significant frames for effective motion masking. In this work, we propose a speech-queried attention-based mask modeling framework for co-speech motion generation. Our key insight is to leverage motion-aligned speech features to guide the masked motion modeling process, selectively masking rhythm-related and semantically expressive motion frames. Specifically, we first propose a motion-audio alignment module (MAM) to construct a latent motion-audio joint space. In this space, both low-level and high-level speech features are projected, enabling motion-aligned speech representation using learnable speech queries. Then, a speech-queried attention mechanism (SQA) is introduced to compute frame-level attention scores through interactions between motion keys and speech queries, guiding selective masking toward motion frames with high attention scores. Finally, the motion-aligned speech features are also injected into the generation network to facilitate co-speech motion generation. Qualitative and quantitative evaluations confirm that our method outperforms existing state-of-the-art approaches, successfully producing high-quality co-speech motion.
OmniSVG: A Unified Scalable Vector Graphics Generation Model
Apr 08, 2025
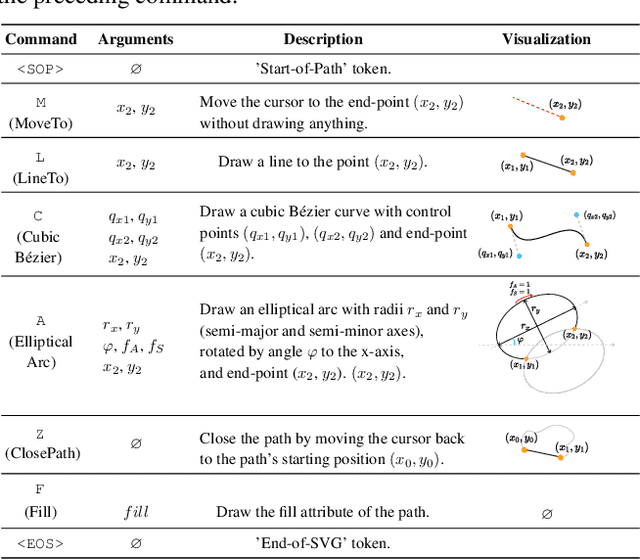
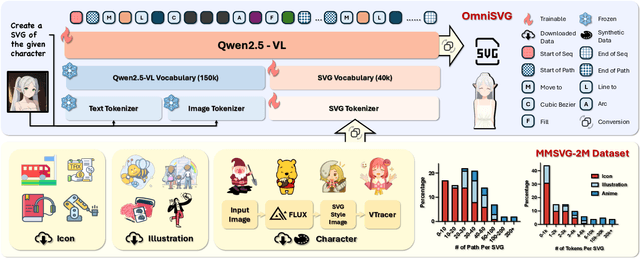
Scalable Vector Graphics (SVG) is an important image format widely adopted in graphic design because of their resolution independence and editability. The study of generating high-quality SVG has continuously drawn attention from both designers and researchers in the AIGC community. However, existing methods either produces unstructured outputs with huge computational cost or is limited to generating monochrome icons of over-simplified structures. To produce high-quality and complex SVG, we propose OmniSVG, a unified framework that leverages pre-trained Vision-Language Models (VLMs) for end-to-end multimodal SVG generation. By parameterizing SVG commands and coordinates into discrete tokens, OmniSVG decouples structural logic from low-level geometry for efficient training while maintaining the expressiveness of complex SVG structure. To further advance the development of SVG synthesis, we introduce MMSVG-2M, a multimodal dataset with two million richly annotated SVG assets, along with a standardized evaluation protocol for conditional SVG generation tasks. Extensive experiments show that OmniSVG outperforms existing methods and demonstrates its potential for integration into professional SVG design workflows.
SemTalk: Holistic Co-speech Motion Generation with Frame-level Semantic Emphasis
Dec 21, 2024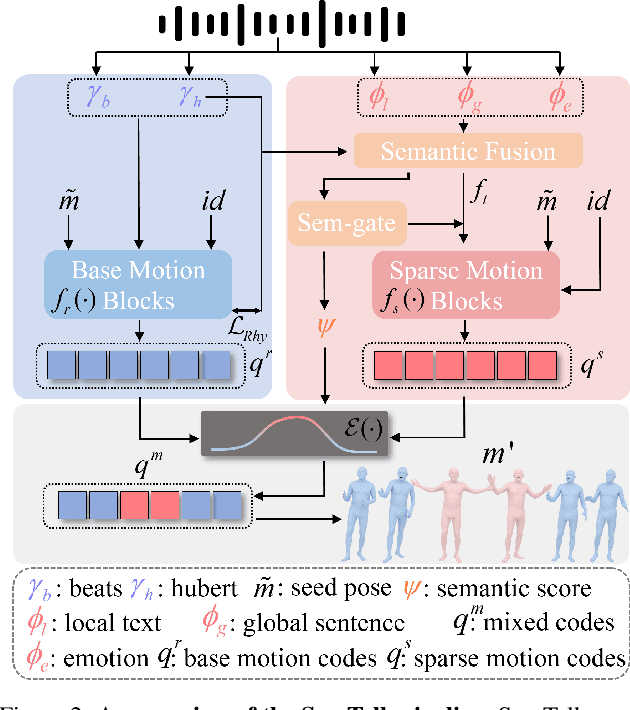
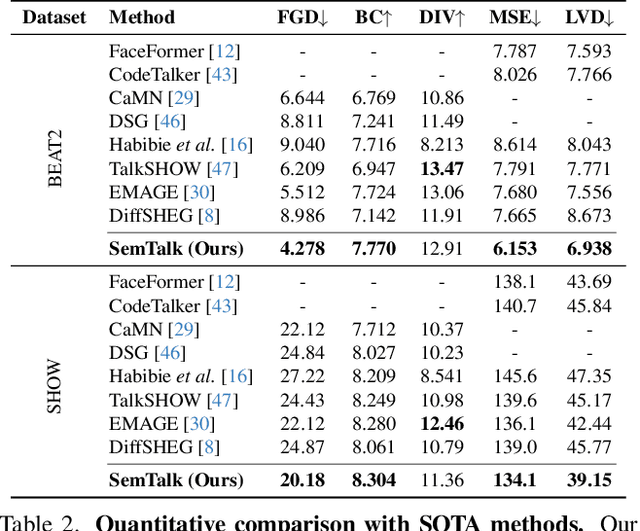
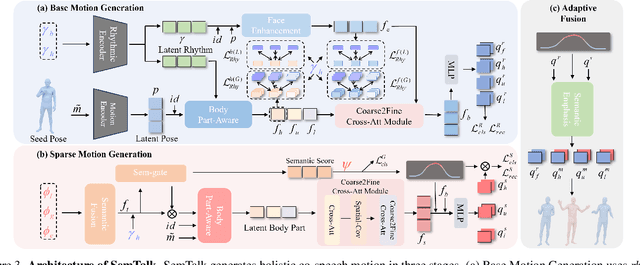

A good co-speech motion generation cannot be achieved without a careful integration of common rhythmic motion and rare yet essential semantic motion. In this work, we propose SemTalk for holistic co-speech motion generation with frame-level semantic emphasis. Our key insight is to separately learn general motions and sparse motions, and then adaptively fuse them. In particular, rhythmic consistency learning is explored to establish rhythm-related base motion, ensuring a coherent foundation that synchronizes gestures with the speech rhythm. Subsequently, textit{semantic emphasis learning is designed to generate semantic-aware sparse motion, focusing on frame-level semantic cues. Finally, to integrate sparse motion into the base motion and generate semantic-emphasized co-speech gestures, we further leverage a learned semantic score for adaptive synthesis. Qualitative and quantitative comparisons on two public datasets demonstrate that our method outperforms the state-of-the-art, delivering high-quality co-speech motion with enhanced semantic richness over a stable base motion.
MikuDance: Animating Character Art with Mixed Motion Dynamics
Nov 14, 2024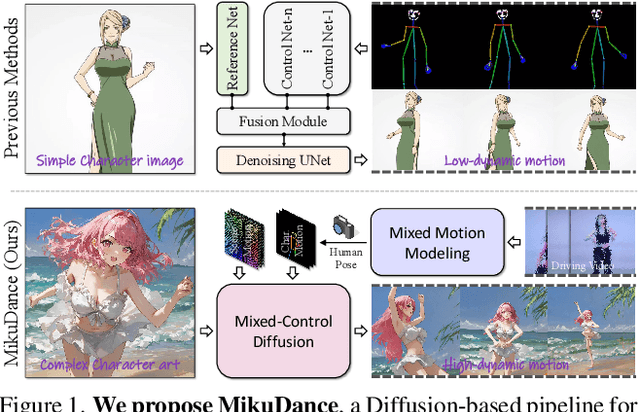
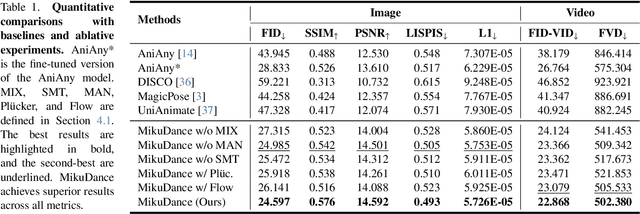
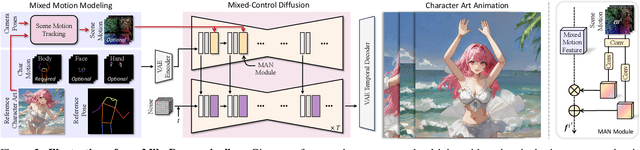
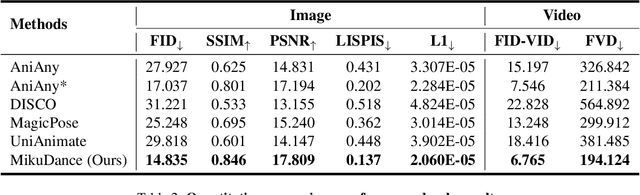
We propose MikuDance, a diffusion-based pipeline incorporating mixed motion dynamics to animate stylized character art. MikuDance consists of two key techniques: Mixed Motion Modeling and Mixed-Control Diffusion, to address the challenges of high-dynamic motion and reference-guidance misalignment in character art animation. Specifically, a Scene Motion Tracking strategy is presented to explicitly model the dynamic camera in pixel-wise space, enabling unified character-scene motion modeling. Building on this, the Mixed-Control Diffusion implicitly aligns the scale and body shape of diverse characters with motion guidance, allowing flexible control of local character motion. Subsequently, a Motion-Adaptive Normalization module is incorporated to effectively inject global scene motion, paving the way for comprehensive character art animation. Through extensive experiments, we demonstrate the effectiveness and generalizability of MikuDance across various character art and motion guidance, consistently producing high-quality animations with remarkable motion dynamics.
Expressive Keypoints for Skeleton-based Action Recognition via Skeleton Transformation
Jun 26, 2024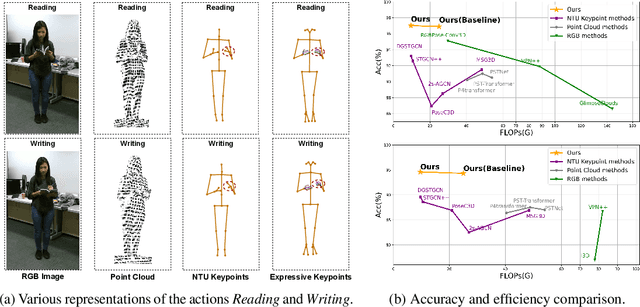
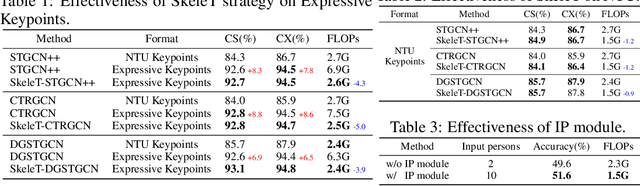
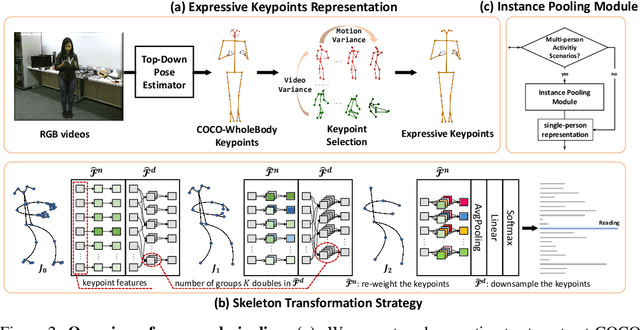
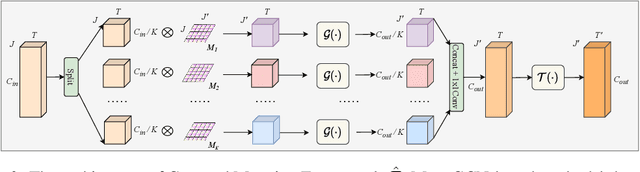
In the realm of skeleton-based action recognition, the traditional methods which rely on coarse body keypoints fall short of capturing subtle human actions. In this work, we propose Expressive Keypoints that incorporates hand and foot details to form a fine-grained skeletal representation, improving the discriminative ability for existing models in discerning intricate actions. To efficiently model Expressive Keypoints, the Skeleton Transformation strategy is presented to gradually downsample the keypoints and prioritize prominent joints by allocating the importance weights. Additionally, a plug-and-play Instance Pooling module is exploited to extend our approach to multi-person scenarios without surging computation costs. Extensive experimental results over seven datasets present the superiority of our method compared to the state-of-the-art for skeleton-based human action recognition. Code is available at https://github.com/YijieYang23/SkeleT-GCN.