 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexPose: Pose Distribution Adaptation with Limited Guidance
Dec 18, 2024



Numerous well-annotated human key-point datasets are publicly available to date. However, annotating human poses for newly collected images is still a costly and time-consuming progress. Pose distributions from different datasets share similar pose hinge-structure priors with different geometric transformations, such as pivot orientation, joint rotation, and bone length ratio. The difference between Pose distributions is essentially the difference between the transformation distributions. Inspired by this fact, we propose a method to calibrate a pre-trained pose generator in which the pose prior has already been learned to an adapted one following a new pose distribution. We treat the representation of human pose joint coordinates as skeleton image and transfer a pre-trained pose annotation generator with only a few annotation guidance. By fine-tuning a limited number of linear layers that closely related to the pose transformation, the adapted generator is able to produce any number of pose annotations that are similar to the target poses. We evaluate our proposed method, FlexPose, on several cross-dataset settings both qualitatively and quantitatively, which demonstrates that our approach achieves state-of-the-art performance compared to the existing generative-model-based transfer learning methods when given limited annotation guidance.
Learning Anchor Transformations for 3D Garment Animation
Apr 03, 2023



This paper proposes an anchor-based deformation model, namely AnchorDEF, to predict 3D garment animation from a body motion sequence. It deforms a garment mesh template by a mixture of rigid transformations with extra nonlinear displacements. A set of anchors around the mesh surface is introduced to guide the learning of rigid transformation matrices. Once the anchor transformations are found, per-vertex nonlinear displacements of the garment template can be regressed in a canonical space, which reduces the complexity of deformation space learning. By explicitly constraining the transformed anchors to satisfy the consistencies of position, normal and direction, the physical meaning of learned anchor transformations in space is guaranteed for better generalization. Furthermore, an adaptive anchor updating is proposed to optimize the anchor position by being aware of local mesh topology for learning representative anchor transformations. Qualitative and quantitative experiments on different types of garments demonstrate that AnchorDEF achieves the state-of-the-art performance on 3D garment deformation prediction in motion, especially for loose-fitting garments.
Skinned Motion Retargeting with Residual Perception of Motion Semantics & Geometry
Mar 15, 2023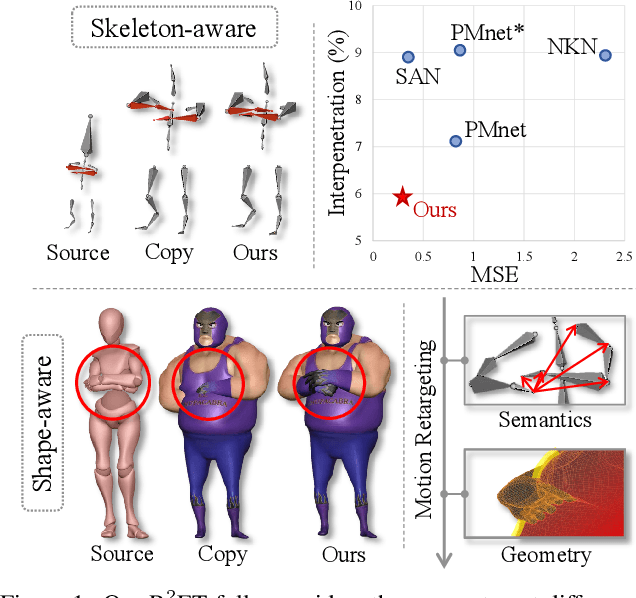
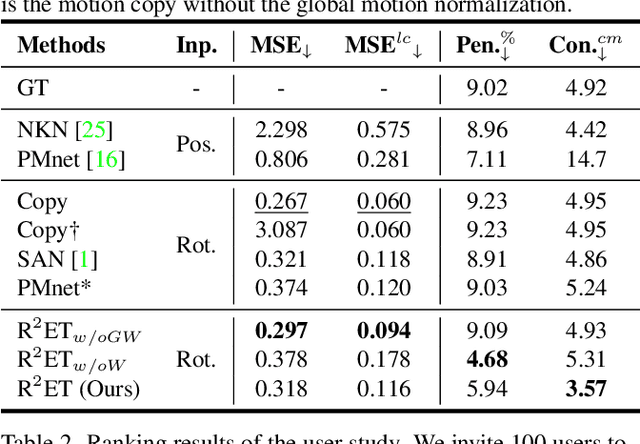
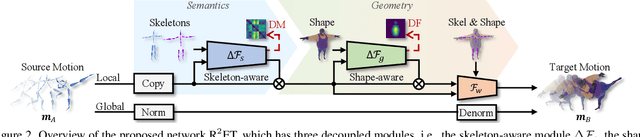
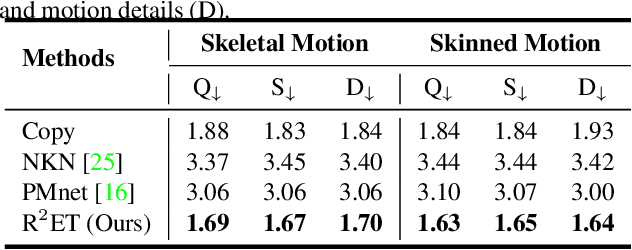
A good motion retargeting cannot be reached without reasonable consideration of source-target differences on both the skeleton and shape geometry levels. In this work, we propose a novel Residual RETargeting network (R2ET) structure, which relies on two neural modification modules, to adjust the source motions to fit the target skeletons and shapes progressively. In particular, a skeleton-aware module is introduced to preserve the source motion semantics. A shape-aware module is designed to perceive the geometries of target characters to reduce interpenetration and contact-missing. Driven by our explored distance-based losses that explicitly model the motion semantics and geometry, these two modules can learn residual motion modifications on the source motion to generate plausible retargeted motion in a single inference without post-processing. To balance these two modifications, we further present a balancing gate to conduct linear interpolation between them. Extensive experiments on the public dataset Mixamo demonstrate that our R2ET achieves the state-of-the-art performance, and provides a good balance between the preservation of motion semantics as well as the attenuation of interpenetration and contact-missing. Code is available at https://github.com/Kebii/R2ET.
Truncate-Split-Contrast: A Framework for Learning from Mislabeled Videos
Dec 29, 2022



Learning with noisy label (LNL) is a classic problem that has been extensively studied for image tasks, but much less for video in the literature. A straightforward migration from images to videos without considering the properties of videos, such as computational cost and redundant information, is not a sound choice. In this paper, we propose two new strategies for video analysis with noisy labels: 1) A lightweight channel selection method dubbed as Channel Truncation for feature-based label noise detection. This method selects the most discriminative channels to split clean and noisy instances in each category; 2) A novel contrastive strategy dubbed as Noise Contrastive Learning, which constructs the relationship between clean and noisy instances to regularize model training. Experiments on three well-known benchmark datasets for video classification show that our proposed tru{\bf N}cat{\bf E}-split-contr{\bf A}s{\bf T} (NEAT) significantly outperforms the existing baselines. By reducing the dimension to 10\% of it, our method achieves over 0.4 noise detection F1-score and 5\% classification accuracy improvement on Mini-Kinetics dataset under severe noise (symmetric-80\%). Thanks to Noise Contrastive Learning, the average classification accuracy improvement on Mini-Kinetics and Sth-Sth-V1 is over 1.6\%.
LocVTP: Video-Text Pre-training for Temporal Localization
Jul 21, 2022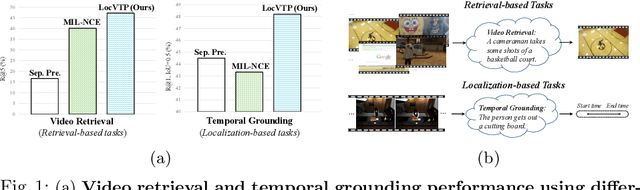
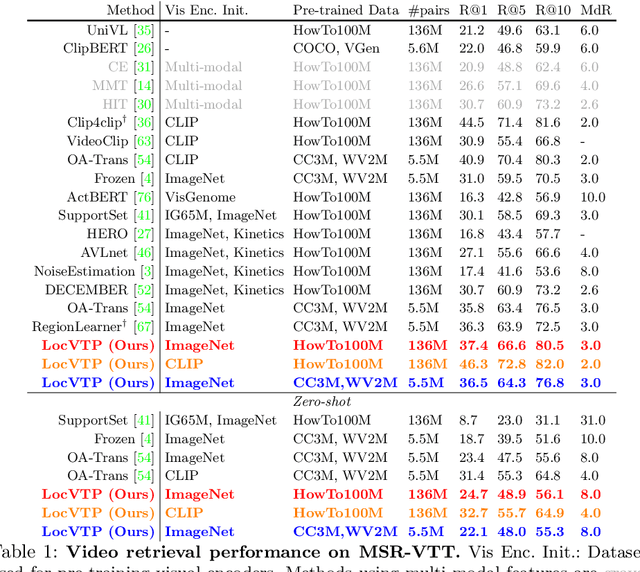

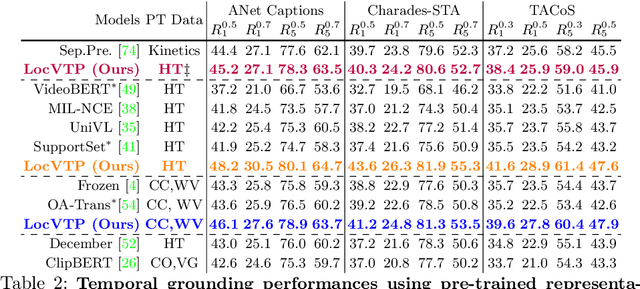
Video-Text Pre-training (VTP) aims to learn transferable representations for various downstream tasks from large-scale web videos. To date, almost all existing VTP methods are limited to retrieval-based downstream tasks, e.g., video retrieval, whereas their transfer potentials on localization-based tasks, e.g., temporal grounding, are under-explored. In this paper, we experimentally analyze and demonstrate the incompatibility of current VTP methods with localization tasks, and propose a novel Localization-oriented Video-Text Pre-training framework, dubbed as LocVTP. Specifically, we perform the fine-grained contrastive alignment as a complement to the coarse-grained one by a clip-word correspondence discovery scheme. To further enhance the temporal reasoning ability of the learned feature, we propose a context projection head and a temporal aware contrastive loss to perceive the contextual relationships. Extensive experiments on four downstream tasks across six datasets demonstrate that our LocVTP achieves state-of-the-art performance on both retrieval-based and localization-based tasks. Furthermore, we conduct comprehensive ablation studies and thorough analyses to explore the optimum model designs and training strategies.
Unsupervised Pre-training for Temporal Action Localization Tasks
Mar 25, 2022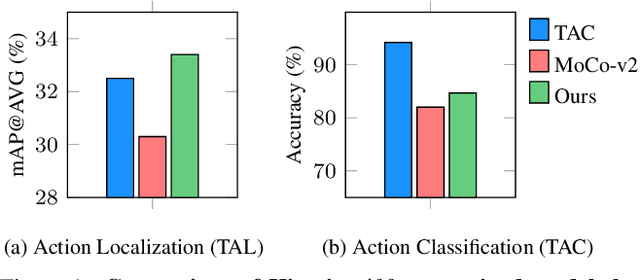
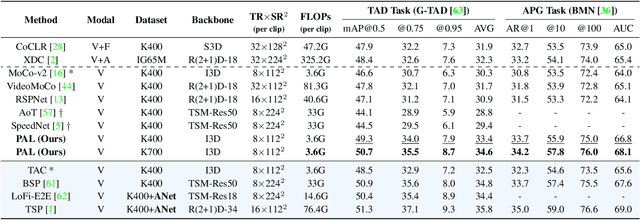
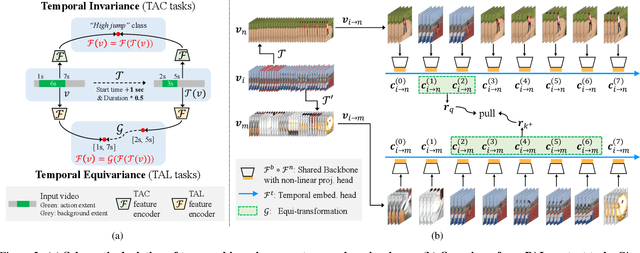

Unsupervised video representation learning has made remarkable achievements in recent years. However, most existing methods are designed and optimized for video classification. These pre-trained models can be sub-optimal for temporal localization tasks due to the inherent discrepancy between video-level classification and clip-level localization. To bridge this gap, we make the first attempt to propose a self-supervised pretext task, coined as Pseudo Action Localization (PAL) to Unsupervisedly Pre-train feature encoders for Temporal Action Localization tasks (UP-TAL). Specifically, we first randomly select temporal regions, each of which contains multiple clips, from one video as pseudo actions and then paste them onto different temporal positions of the other two videos. The pretext task is to align the features of pasted pseudo action regions from two synthetic videos and maximize the agreement between them. Compared to the existing unsupervised video representation learning approaches, our PAL adapts better to downstream TAL tasks by introducing a temporal equivariant contrastive learning paradigm in a temporally dense and scale-aware manner. Extensive experiments show that PAL can utilize large-scale unlabeled video data to significantly boost the performance of existing TAL methods. Our codes and models will be made publicly available at https://github.com/zhang-can/UP-TAL.
Temporal Distinct Representation Learning for Action Recognition
Jul 15, 2020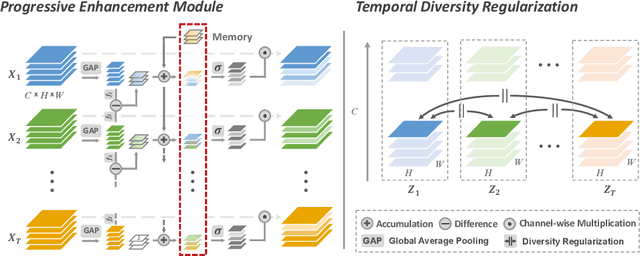

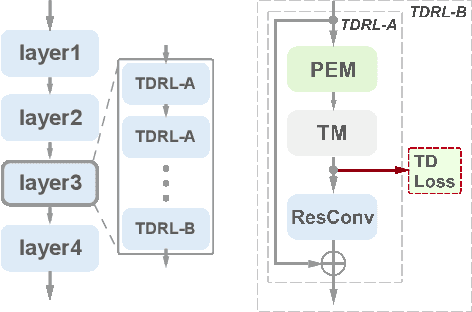
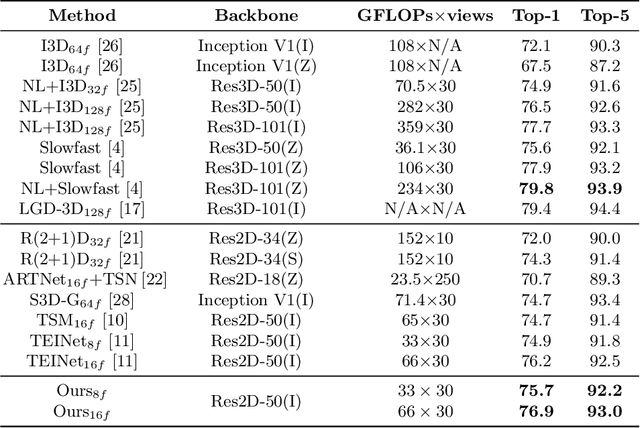
Motivated by the previous success of Two-Dimensional Convolutional Neural Network (2D CNN) on image recognition, researchers endeavor to leverage it to characterize videos. However, one limitation of applying 2D CNN to analyze videos is that different frames of a video share the same 2D CNN kernels, which may result in repeated and redundant information utilization, especially in the spatial semantics extraction process, hence neglecting the critical variations among frames. In this paper, we attempt to tackle this issue through two ways. 1) Design a sequential channel filtering mechanism, i.e., Progressive Enhancement Module (PEM), to excite the discriminative channels of features from different frames step by step, and thus avoid repeated information extraction. 2) Create a Temporal Diversity Loss (TD Loss) to force the kernels to concentrate on and capture the variations among frames rather than the image regions with similar appearance. Our method is evaluated on benchmark temporal reasoning datasets Something-Something V1 and V2, and it achieves visible improvements over the best competitor by 2.4% and 1.3%, respectively. Besides, performance improvements over the 2D-CNN-based state-of-the-arts on the large-scale dataset Kinetics are also witnessed.