 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Error Accumulation in Co-Speech Motion Generation via Global Rotation Diffusion and Multi-Level Constraints
Nov 13, 2025Reliable co-speech motion generation requires precise motion representation and consistent structural priors across all joints. Existing generative methods typically operate on local joint rotations, which are defined hierarchically based on the skeleton structure. This leads to cumulative errors during generation, manifesting as unstable and implausible motions at end-effectors. In this work, we propose GlobalDiff, a diffusion-based framework that operates directly in the space of global joint rotations for the first time, fundamentally decoupling each joint's prediction from upstream dependencies and alleviating hierarchical error accumulation. To compensate for the absence of structural priors in global rotation space, we introduce a multi-level constraint scheme. Specifically, a joint structure constraint introduces virtual anchor points around each joint to better capture fine-grained orientation. A skeleton structure constraint enforces angular consistency across bones to maintain structural integrity. A temporal structure constraint utilizes a multi-scale variational encoder to align the generated motion with ground-truth temporal patterns. These constraints jointly regularize the global diffusion process and reinforce structural awareness. Extensive evaluations on standard co-speech benchmarks show that GlobalDiff generates smooth and accurate motions, improving the performance by 46.0 % compared to the current SOTA under multiple speaker identities.
* AAAI 2026
EchoMask: Speech-Queried Attention-based Mask Modeling for Holistic Co-Speech Motion Generation
Apr 15, 2025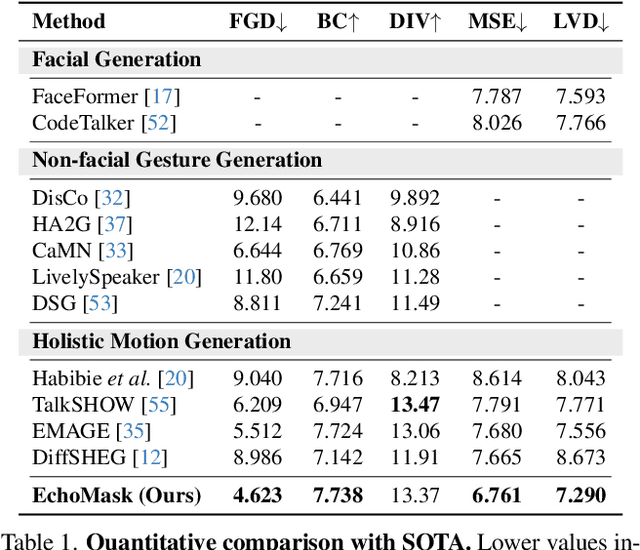
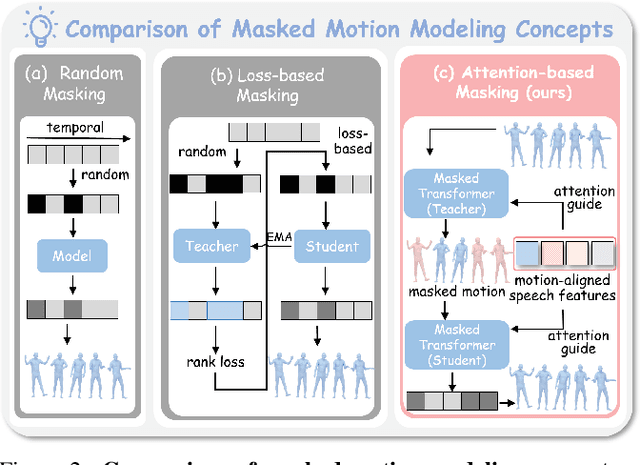
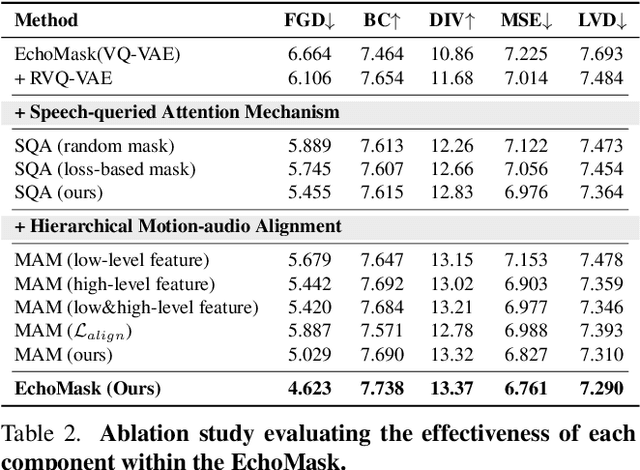
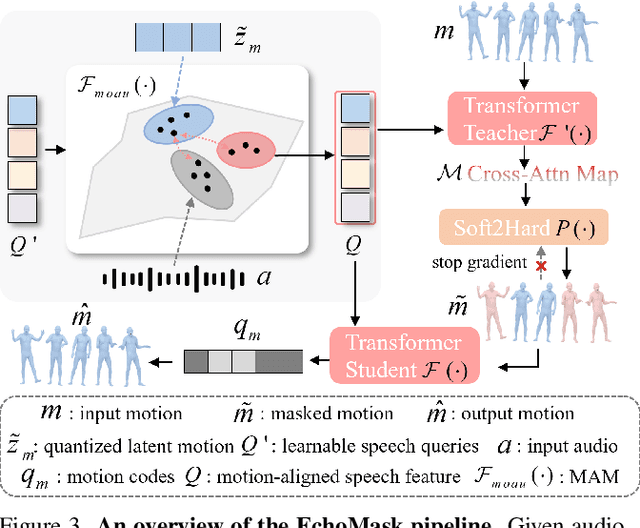
Masked modeling framework has shown promise in co-speech motion generation. However, it struggles to identify semantically significant frames for effective motion masking. In this work, we propose a speech-queried attention-based mask modeling framework for co-speech motion generation. Our key insight is to leverage motion-aligned speech features to guide the masked motion modeling process, selectively masking rhythm-related and semantically expressive motion frames. Specifically, we first propose a motion-audio alignment module (MAM) to construct a latent motion-audio joint space. In this space, both low-level and high-level speech features are projected, enabling motion-aligned speech representation using learnable speech queries. Then, a speech-queried attention mechanism (SQA) is introduced to compute frame-level attention scores through interactions between motion keys and speech queries, guiding selective masking toward motion frames with high attention scores. Finally, the motion-aligned speech features are also injected into the generation network to facilitate co-speech motion generation. Qualitative and quantitative evaluations confirm that our method outperforms existing state-of-the-art approaches, successfully producing high-quality co-speech motion.
Make-A-Character 2: Animatable 3D Character Generation From a Single Image
Jan 15, 2025



This report introduces Make-A-Character 2, an advanced system for generating high-quality 3D characters from single portrait photographs, ideal for game development and digital human applications. Make-A-Character 2 builds upon its predecessor by incorporating several significant improvements for image-based head generation. We utilize the IC-Light method to correct non-ideal illumination in input photos and apply neural network-based color correction to harmonize skin tones between the photos and game engine renders. We also employ the Hierarchical Representation Network to capture high-frequency facial structures and conduct adaptive skeleton calibration for accurate and expressive facial animations. The entire image-to-3D-character generation process takes less than 2 minutes. Furthermore, we leverage transformer architecture to generate co-speech facial and gesture actions, enabling real-time conversation with the generated character. These technologies have been integrated into our conversational AI avatar products.
Cascaded Dual Vision Transformer for Accurate Facial Landmark Detection
Nov 08, 2024Facial landmark detection is a fundamental problem in computer vision for many downstream applications. This paper introduces a new facial landmark detector based on vision transformers, which consists of two unique designs: Dual Vision Transformer (D-ViT) and Long Skip Connections (LSC). Based on the observation that the channel dimension of feature maps essentially represents the linear bases of the heatmap space, we propose learning the interconnections between these linear bases to model the inherent geometric relations among landmarks via Channel-split ViT. We integrate such channel-split ViT into the standard vision transformer (i.e., spatial-split ViT), forming our Dual Vision Transformer to constitute the prediction blocks. We also suggest using long skip connections to deliver low-level image features to all prediction blocks, thereby preventing useful information from being discarded by intermediate supervision. Extensive experiments are conducted to evaluate the performance of our proposal on the widely used benchmarks, i.e., WFLW, COFW, and 300W, demonstrating that our model outperforms the previous SOTAs across all three benchmarks.
Make-A-Character: High Quality Text-to-3D Character Generation within Minutes
Dec 24, 2023



There is a growing demand for customized and expressive 3D characters with the emergence of AI agents and Metaverse, but creating 3D characters using traditional computer graphics tools is a complex and time-consuming task. To address these challenges, we propose a user-friendly framework named Make-A-Character (Mach) to create lifelike 3D avatars from text descriptions. The framework leverages the power of large language and vision models for textual intention understanding and intermediate image generation, followed by a series of human-oriented visual perception and 3D generation modules. Our system offers an intuitive approach for users to craft controllable, realistic, fully-realized 3D characters that meet their expectations within 2 minutes, while also enabling easy integration with existing CG pipeline for dynamic expressiveness. For more information, please visit the project page at https://human3daigc.github.io/MACH/.
GAT-CADNet: Graph Attention Network for Panoptic Symbol Spotting in CAD Drawings
Jan 10, 2022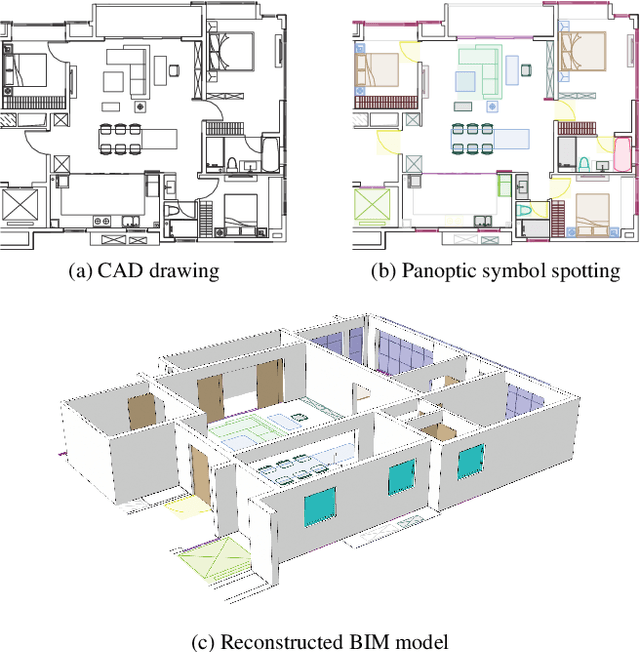
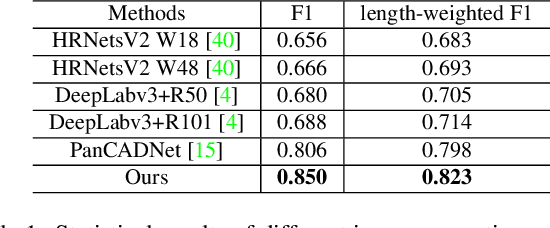
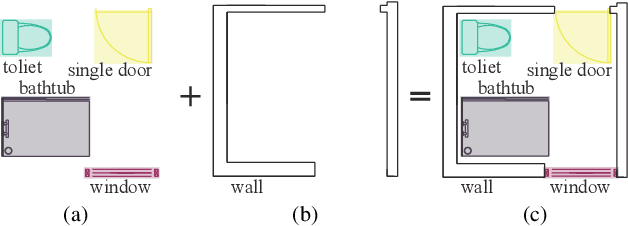
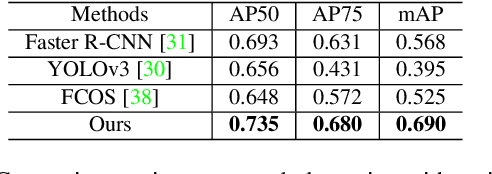
Spotting graphical symbols from the computer-aided design (CAD) drawings is essential to many industrial applications. Different from raster images, CAD drawings are vector graphics consisting of geometric primitives such as segments, arcs, and circles. By treating each CAD drawing as a graph, we propose a novel graph attention network GAT-CADNet to solve the panoptic symbol spotting problem: vertex features derived from the GAT branch are mapped to semantic labels, while their attention scores are cascaded and mapped to instance prediction. Our key contributions are three-fold: 1) the instance symbol spotting task is formulated as a subgraph detection problem and solved by predicting the adjacency matrix; 2) a relative spatial encoding (RSE) module explicitly encodes the relative positional and geometric relation among vertices to enhance the vertex attention; 3) a cascaded edge encoding (CEE) module extracts vertex attentions from multiple stages of GAT and treats them as edge encoding to predict the adjacency matrix. The proposed GAT-CADNet is intuitive yet effective and manages to solve the panoptic symbol spotting problem in one consolidated network. Extensive experiments and ablation studies on the public benchmark show that our graph-based approach surpasses existing state-of-the-art methods by a large margin.