 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyRoom: Room-aware Transformer for Floorplan Reconstruction
Jul 15, 2024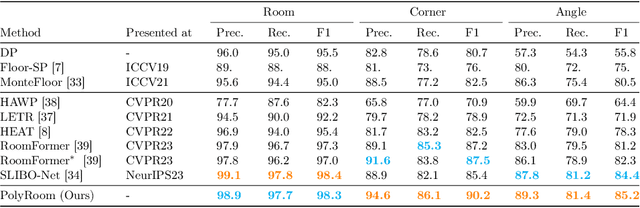
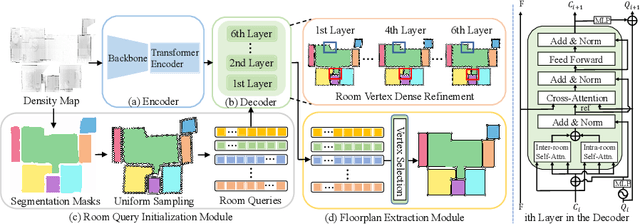
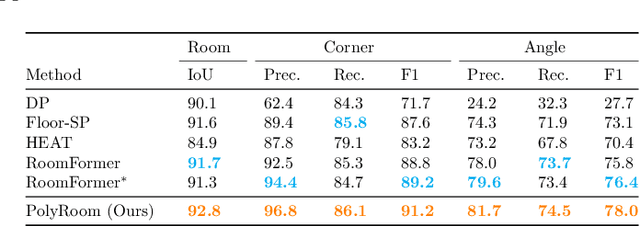

Reconstructing geometry and topology structures from raw unstructured data has always been an important research topic in indoor mapping research. In this paper, we aim to reconstruct the floorplan with a vectorized representation from point clouds. Despite significant advancements achieved in recent years, current methods still encounter several challenges, such as missing corners or edges, inaccuracies in corner positions or angles, self-intersecting or overlapping polygons, and potentially implausible topology. To tackle these challenges, we present PolyRoom, a room-aware Transformer that leverages uniform sampling representation, room-aware query initialization, and room-aware self-attention for floorplan reconstruction. Specifically, we adopt a uniform sampling floorplan representation to enable dense supervision during training and effective utilization of angle information. Additionally, we propose a room-aware query initialization scheme to prevent non-polygonal sequences and introduce room-aware self-attention to enhance memory efficiency and model performance. Experimental results on two widely used datasets demonstrate that PolyRoom surpasses current state-of-the-art methods both quantitatively and qualitatively. Our code is available at: https://github.com/3dv-casia/PolyRoom/.
GAT-CADNet: Graph Attention Network for Panoptic Symbol Spotting in CAD Drawings
Jan 10, 2022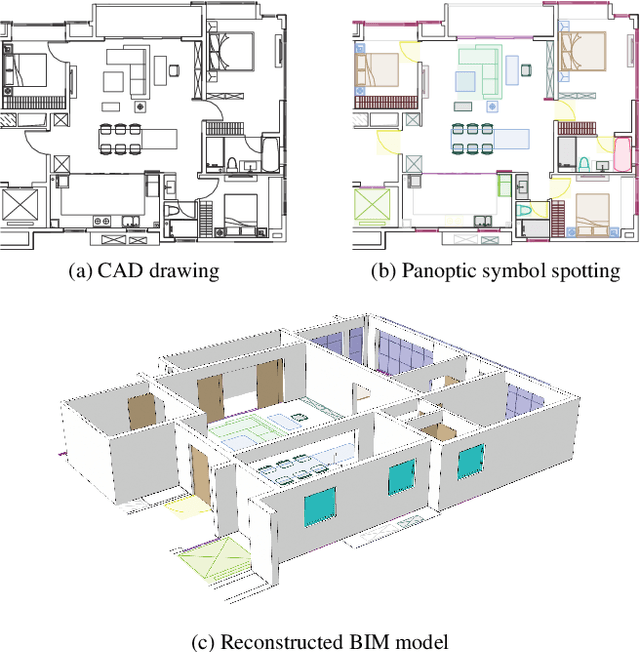
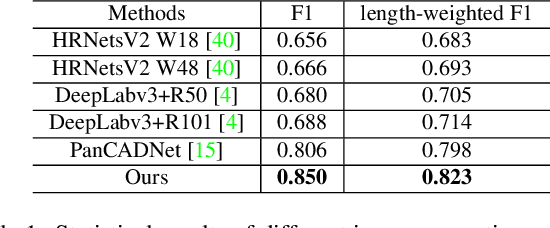
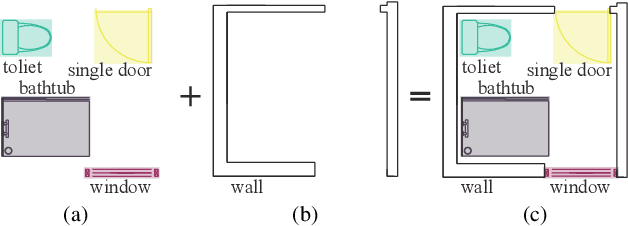
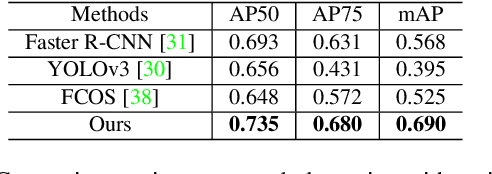
Spotting graphical symbols from the computer-aided design (CAD) drawings is essential to many industrial applications. Different from raster images, CAD drawings are vector graphics consisting of geometric primitives such as segments, arcs, and circles. By treating each CAD drawing as a graph, we propose a novel graph attention network GAT-CADNet to solve the panoptic symbol spotting problem: vertex features derived from the GAT branch are mapped to semantic labels, while their attention scores are cascaded and mapped to instance prediction. Our key contributions are three-fold: 1) the instance symbol spotting task is formulated as a subgraph detection problem and solved by predicting the adjacency matrix; 2) a relative spatial encoding (RSE) module explicitly encodes the relative positional and geometric relation among vertices to enhance the vertex attention; 3) a cascaded edge encoding (CEE) module extracts vertex attentions from multiple stages of GAT and treats them as edge encoding to predict the adjacency matrix. The proposed GAT-CADNet is intuitive yet effective and manages to solve the panoptic symbol spotting problem in one consolidated network. Extensive experiments and ablation studies on the public benchmark show that our graph-based approach surpasses existing state-of-the-art methods by a large margin.
FloorPlanCAD: A Large-Scale CAD Drawing Dataset for Panoptic Symbol Spotting
May 15, 2021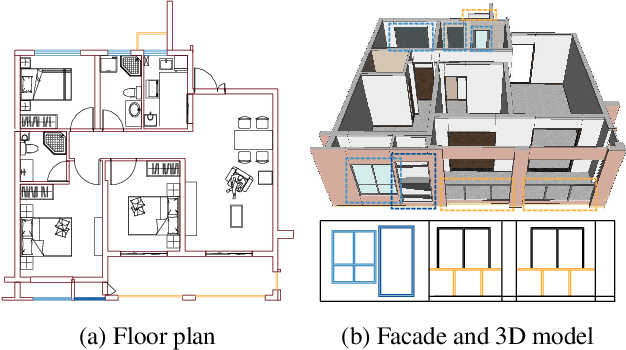


Access to large and diverse computer-aided design (CAD) drawings is critical for developing symbol spotting algorithms. In this paper, we present FloorPlanCAD, a large-scale real-world CAD drawing dataset containing over 10,000 floor plans, ranging from residential to commercial buildings. CAD drawings in the dataset are all represented as vector graphics, which enable us to provide line-grained annotations of 30 object categories. Equipped by such annotations, we introduce the task of panoptic symbol spotting, which requires to spot not only instances of countable things, but also the semantic of uncountable stuff. Aiming to solve this task, we propose a novel method by combining Graph Convolutional Networks (GCNs) with Convolutional Neural Networks (CNNs), which captures both non-Euclidean and Euclidean features and can be trained end-to-end. The proposed CNN-GCN method achieved state-of-the-art (SOTA) performance on the task of semantic symbol spotting, and help us build a baseline network for the panoptic symbol spotting task. Our contributions are three-fold: 1) to the best of our knowledge, the presented CAD drawing dataset is the first of its kind; 2) the panoptic symbol spotting task considers the spotting of both thing instances and stuff semantic as one recognition problem; and 3) we presented a baseline solution to the panoptic symbol spotting task based on a novel CNN-GCN method, which achieved SOTA performance on semantic symbol spotting. We believe that these contributions will boost research in related areas.
Complete Scene Reconstruction by Merging Images and Laser Scans
May 17, 2019
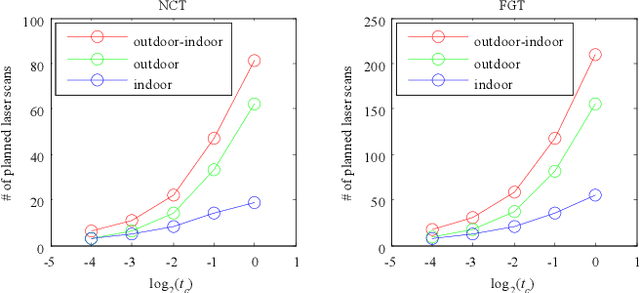
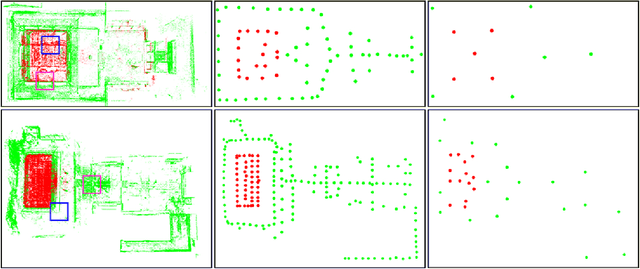

Image based modeling and laser scanning are two commonly used approaches in large-scale architectural scene reconstruction nowadays. In order to generate a complete scene reconstruction, an effective way is to completely cover the scene using ground and aerial images, supplemented by laser scanning on certain regions with low texture and complicated structure. Thus, the key issue is to accurately calibrate cameras and register laser scans in a unified framework. To this end, we proposed a three-step pipeline for complete scene reconstruction by merging images and laser scans. First, images are captured around the architecture in a multi-view and multi-scale way and are feed into a structure-from-motion (SfM) pipeline to generate SfM points. Then, based on the SfM result, the laser scanning locations are automatically planned by considering textural richness, structural complexity of the scene and spatial layout of the laser scans. Finally, the images and laser scans are accurately merged in a coarse-to-fine manner. Experimental evaluations on two ancient Chinese architecture datasets demonstrate the effectiveness of our proposed complete scene reconstruction pipeline.
Visual Localization Using Sparse Semantic 3D Map
May 17, 2019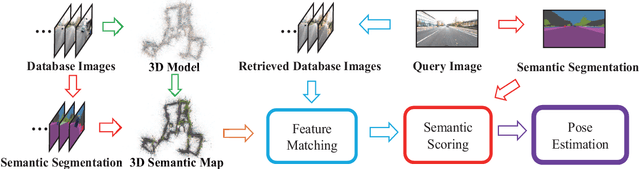
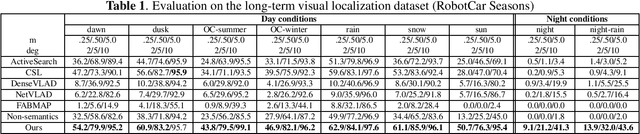
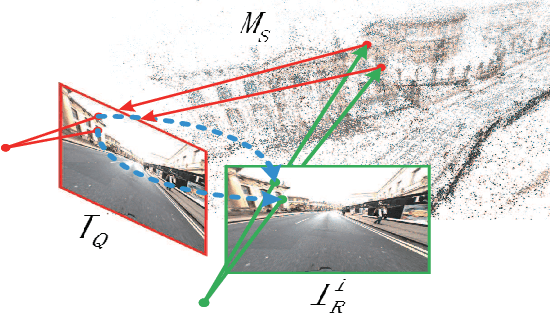

Accurate and robust visual localization under a wide range of viewing condition variations including season and illumination changes, as well as weather and day-night variations, is the key component for many computer vision and robotics applications. Under these conditions, most traditional methods would fail to locate the camera. In this paper we present a visual localization algorithm that combines structure-based method and image-based method with semantic information. Given semantic information about the query and database images, the retrieved images are scored according to the semantic consistency of the 3D model and the query image. Then the semantic matching score is used as weight for RANSAC's sampling and the pose is solved by a standard PnP solver. Experiments on the challenging long-term visual localization benchmark dataset demonstrate that our method has significant improvement compared with the state-of-the-arts.