 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLPerf: a Unified Framework for Benchmarking Split Learning
Apr 04, 2023Data privacy concerns has made centralized training of data, which is scattered across silos, infeasible, leading to the need for collaborative learning frameworks. To address that, two prominent frameworks emerged, i.e., federated learning (FL) and split learning (SL). While FL has established various benchmark frameworks and research libraries, SL currently lacks a unified library despite its diversity in terms of label sharing, model aggregation, and cut layer choice. This lack of standardization makes comparing SL paradigms difficult. To address this, we propose SLPerf, a unified research framework and open research library for SL, and conduct extensive experiments on four widely-used datasets under both IID and Non-IID data settings. Our contributions include a comprehensive survey of recently proposed SL paradigms, a detailed benchmark comparison of different SL paradigms in different situations, and rich engineering take-away messages and research insights for improving SL paradigms. SLPerf can facilitate SL algorithm development and fair performance comparisons.
An Iterative Co-Training Transductive Framework for Zero Shot Learning
Mar 30, 2022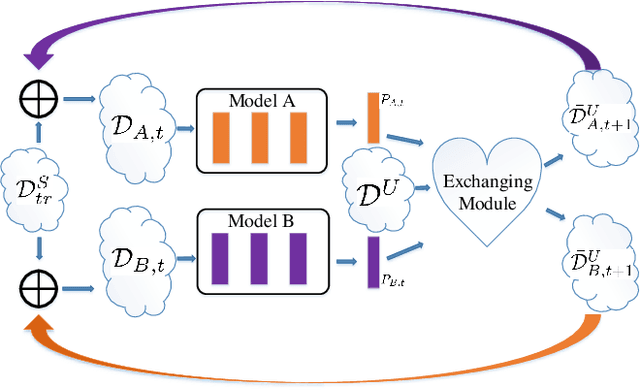
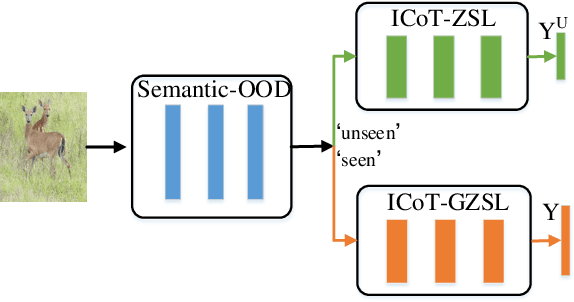
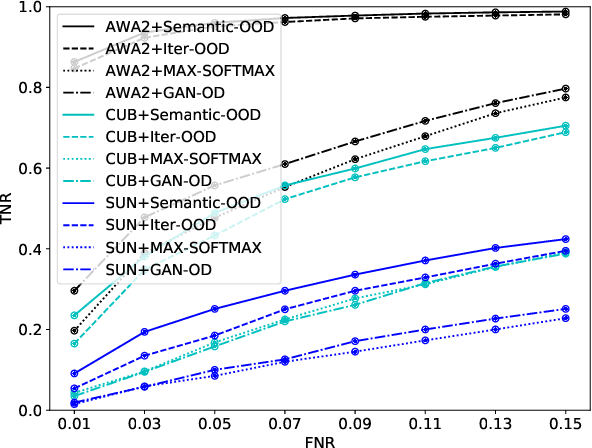
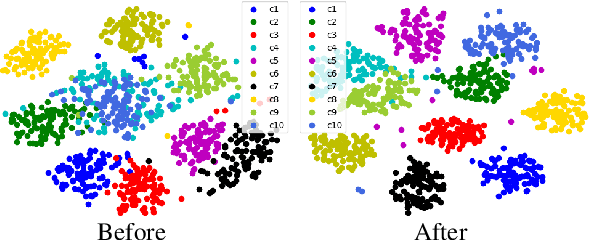
In zero-shot learning (ZSL) community, it is generally recognized that transductive learning performs better than inductive one as the unseen-class samples are also used in its training stage. How to generate pseudo labels for unseen-class samples and how to use such usually noisy pseudo labels are two critical issues in transductive learning. In this work, we introduce an iterative co-training framework which contains two different base ZSL models and an exchanging module. At each iteration, the two different ZSL models are co-trained to separately predict pseudo labels for the unseen-class samples, and the exchanging module exchanges the predicted pseudo labels, then the exchanged pseudo-labeled samples are added into the training sets for the next iteration. By such, our framework can gradually boost the ZSL performance by fully exploiting the potential complementarity of the two models' classification capabilities. In addition, our co-training framework is also applied to the generalized ZSL (GZSL), in which a semantic-guided OOD detector is proposed to pick out the most likely unseen-class samples before class-level classification to alleviate the bias problem in GZSL. Extensive experiments on three benchmarks show that our proposed methods could significantly outperform about $31$ state-of-the-art ones.
* 15 pages, 7 figures
Semantic-diversity transfer network for generalized zero-shot learning via inner disagreement based OOD detector
Mar 17, 2022
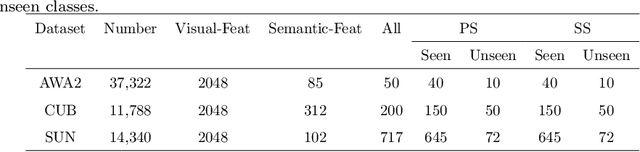
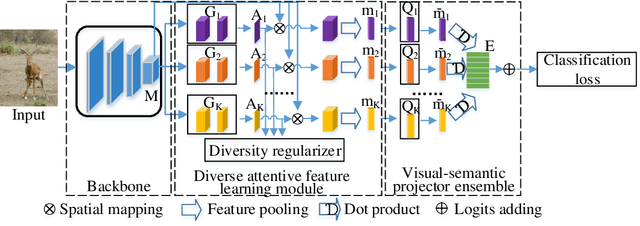

Zero-shot learning (ZSL) aims to recognize objects from unseen classes, where the kernel problem is to transfer knowledge from seen classes to unseen classes by establishing appropriate mappings between visual and semantic features. The knowledge transfer in many existing works is limited mainly due to the facts that 1) the widely used visual features are global ones but not totally consistent with semantic attributes; 2) only one mapping is learned in existing works, which is not able to effectively model diverse visual-semantic relations; 3) the bias problem in the generalized ZSL (GZSL) could not be effectively handled. In this paper, we propose two techniques to alleviate these limitations. Firstly, we propose a Semantic-diversity transfer Network (SetNet) addressing the first two limitations, where 1) a multiple-attention architecture and a diversity regularizer are proposed to learn multiple local visual features that are more consistent with semantic attributes and 2) a projector ensemble that geometrically takes diverse local features as inputs is proposed to model visual-semantic relations from diverse local perspectives. Secondly, we propose an inner disagreement based domain detection module (ID3M) for GZSL to alleviate the third limitation, which picks out unseen-class data before class-level classification. Due to the absence of unseen-class data in training stage, ID3M employs a novel self-contained training scheme and detects out unseen-class data based on a designed inner disagreement criterion. Experimental results on three public datasets demonstrate that the proposed SetNet with the explored ID3M achieves a significant improvement against $30$ state-of-the-art methods.
* 35 pages, 6 figures
Pursuing 3D Scene Structures with Optical Satellite Images from Affine Reconstruction to Euclidean Reconstruction
Jan 16, 2022
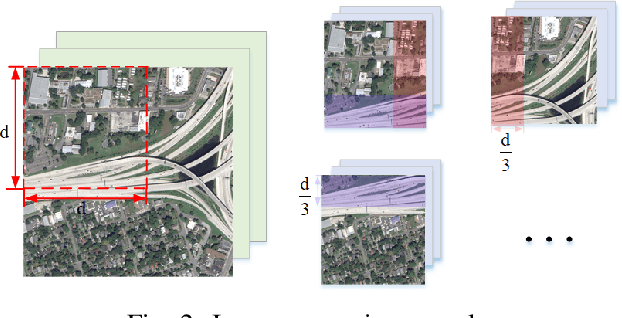
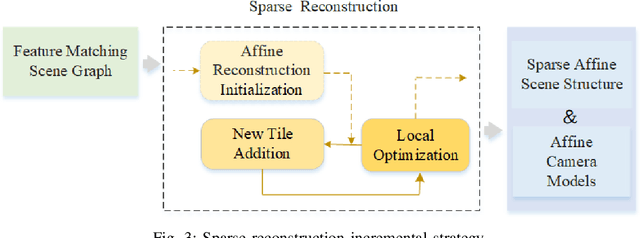

How to use multiple optical satellite images to recover the 3D scene structure is a challenging and important problem in the remote sensing field. Most existing methods in literature have been explored based on the classical RPC (rational polynomial camera) model which requires at least 39 GCPs (ground control points), however, it is not trivial to obtain such a large number of GCPs in many real scenes. Addressing this problem, we propose a hierarchical reconstruction framework based on multiple optical satellite images, which needs only 4 GCPs. The proposed framework is composed of an affine dense reconstruction stage and a followed affine-to-Euclidean upgrading stage: At the affine dense reconstruction stage, an affine dense reconstruction approach is explored for pursuing the 3D affine scene structure without any GCP from input satellite images. Then at the affine-to-Euclidean upgrading stage, the obtained 3D affine structure is upgraded to a Euclidean one with 4 GCPs. Experimental results on two public datasets demonstrate that the proposed method significantly outperforms three state-of-the-art methods in most cases.
HardBoost: Boosting Zero-Shot Learning with Hard Classes
Jan 14, 2022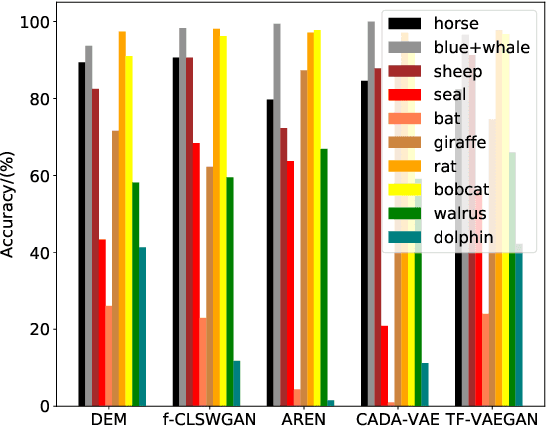
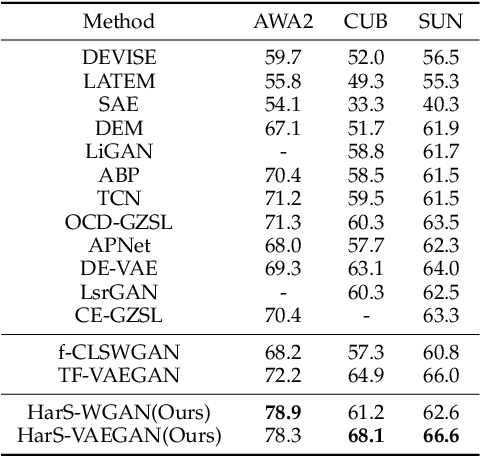
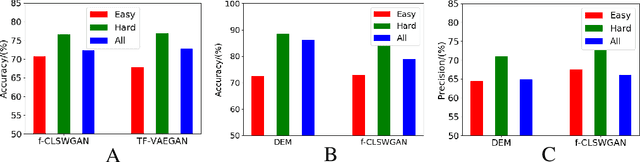
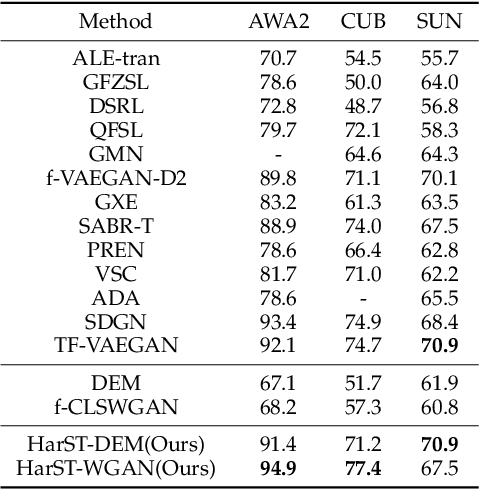
This work is a systematical analysis on the so-called hard class problem in zero-shot learning (ZSL), that is, some unseen classes disproportionally affect the ZSL performances than others, as well as how to remedy the problem by detecting and exploiting hard classes. At first, we report our empirical finding that the hard class problem is a ubiquitous phenomenon and persists regardless of used specific methods in ZSL. Then, we find that high semantic affinity among unseen classes is a plausible underlying cause of hardness and design two metrics to detect hard classes. Finally, two frameworks are proposed to remedy the problem by detecting and exploiting hard classes, one under inductive setting, the other under transductive setting. The proposed frameworks could accommodate most existing ZSL methods to further significantly boost their performances with little efforts. Extensive experiments on three popular benchmarks demonstrate the benefits by identifying and exploiting the hard classes in ZSL.
Rotation Transformation Network: Learning View-Invariant Point Cloud for Classification and Segmentation
Jul 07, 2021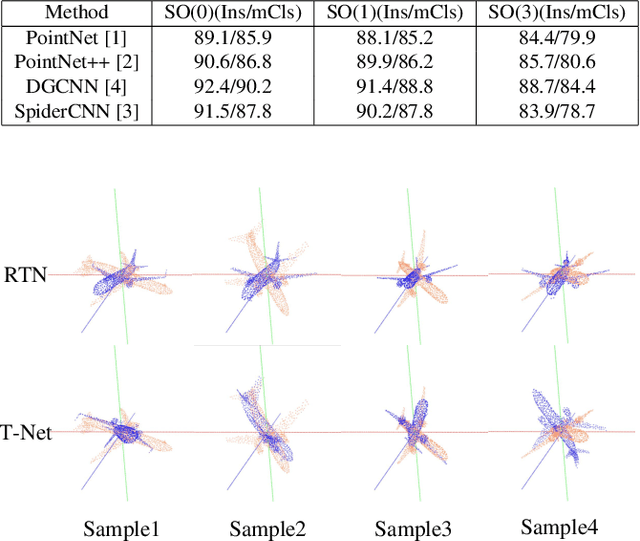
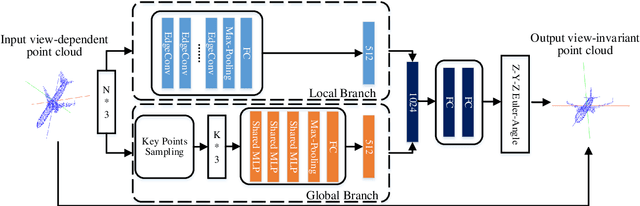

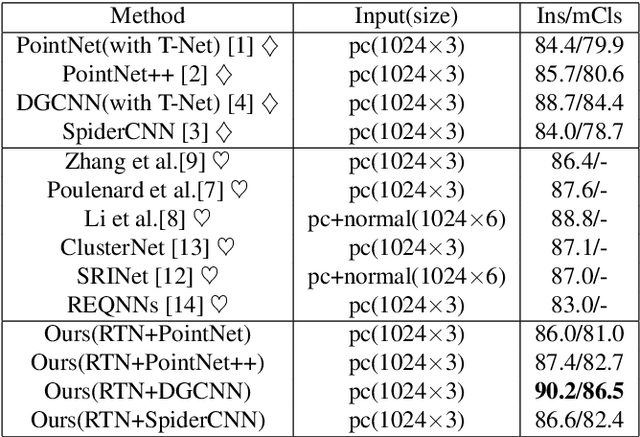
Many recent works show that a spatial manipulation module could boost the performances of deep neural networks (DNNs) for 3D point cloud analysis. In this paper, we aim to provide an insight into spatial manipulation modules. Firstly, we find that the smaller the rotational degree of freedom (RDF) of objects is, the more easily these objects are handled by these DNNs. Then, we investigate the effect of the popular T-Net module and find that it could not reduce the RDF of objects. Motivated by the above two issues, we propose a rotation transformation network for point cloud analysis, called RTN, which could reduce the RDF of input 3D objects to 0. The RTN could be seamlessly inserted into many existing DNNs for point cloud analysis. Extensive experimental results on 3D point cloud classification and segmentation tasks demonstrate that the proposed RTN could improve the performances of several state-of-the-art methods significantly.
Segmenting 3D Hybrid Scenes via Zero-Shot Learning
Jul 04, 2021
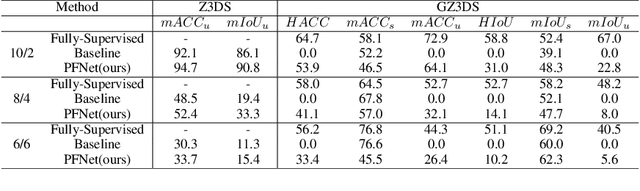
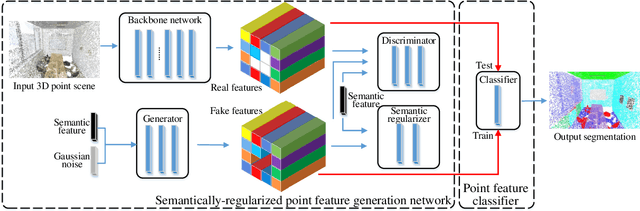
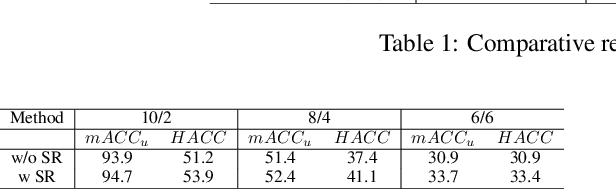
This work is to tackle the problem of point cloud semantic segmentation for 3D hybrid scenes under the framework of zero-shot learning. Here by hybrid, we mean the scene consists of both seen-class and unseen-class 3D objects, a more general and realistic setting in application. To our knowledge, this problem has not been explored in the literature. To this end, we propose a network to synthesize point features for various classes of objects by leveraging the semantic features of both seen and unseen object classes, called PFNet. The proposed PFNet employs a GAN architecture to synthesize point features, where the semantic relationship between seen-class and unseen-class features is consolidated by adapting a new semantic regularizer, and the synthesized features are used to train a classifier for predicting the labels of the testing 3D scene points. Besides we also introduce two benchmarks for algorithmic evaluation by re-organizing the public S3DIS and ScanNet datasets under six different data splits. Experimental results on the two benchmarks validate our proposed method, and we hope our introduced two benchmarks and methodology could be of help for more research on this new direction.
Hardness Sampling for Self-Training Based Transductive Zero-Shot Learning
Jun 01, 2021
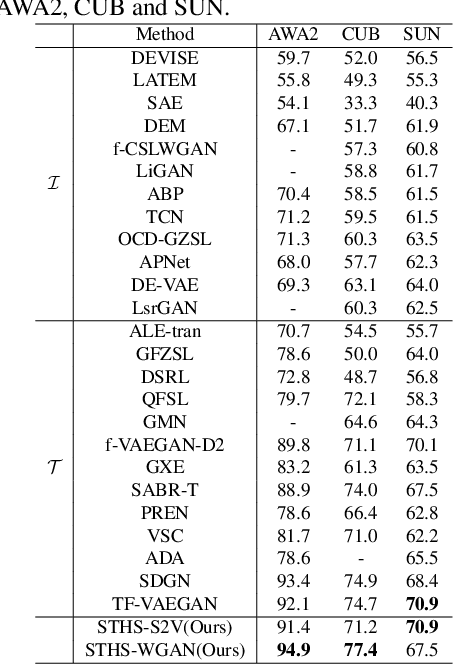


Transductive zero-shot learning (T-ZSL) which could alleviate the domain shift problem in existing ZSL works, has received much attention recently. However, an open problem in T-ZSL: how to effectively make use of unseen-class samples for training, still remains. Addressing this problem, we first empirically analyze the roles of unseen-class samples with different degrees of hardness in the training process based on the uneven prediction phenomenon found in many ZSL methods, resulting in three observations. Then, we propose two hardness sampling approaches for selecting a subset of diverse and hard samples from a given unseen-class dataset according to these observations. The first one identifies the samples based on the class-level frequency of the model predictions while the second enhances the former by normalizing the class frequency via an approximate class prior estimated by an explored prior estimation algorithm. Finally, we design a new Self-Training framework with Hardness Sampling for T-ZSL, called STHS, where an arbitrary inductive ZSL method could be seamlessly embedded and it is iteratively trained with unseen-class samples selected by the hardness sampling approach. We introduce two typical ZSL methods into the STHS framework and extensive experiments demonstrate that the derived T-ZSL methods outperform many state-of-the-art methods on three public benchmarks. Besides, we note that the unseen-class dataset is separately used for training in some existing transductive generalized ZSL (T-GZSL) methods, which is not strict for a GZSL task. Hence, we suggest a more strict T-GZSL data setting and establish a competitive baseline on this setting by introducing the proposed STHS framework to T-GZSL.
Optimization-Based Visual-Inertial SLAM Tightly Coupled with Raw GNSS Measurements
Oct 22, 2020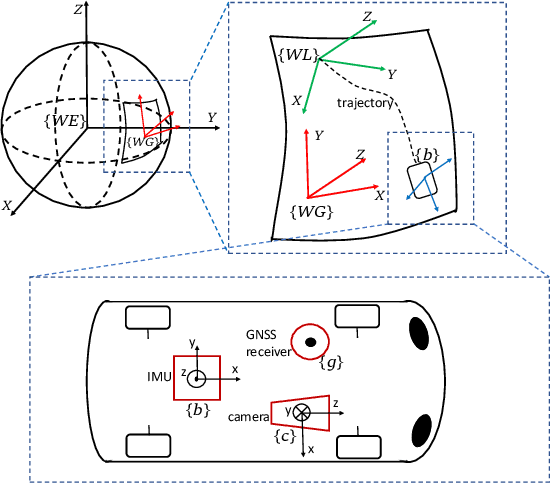
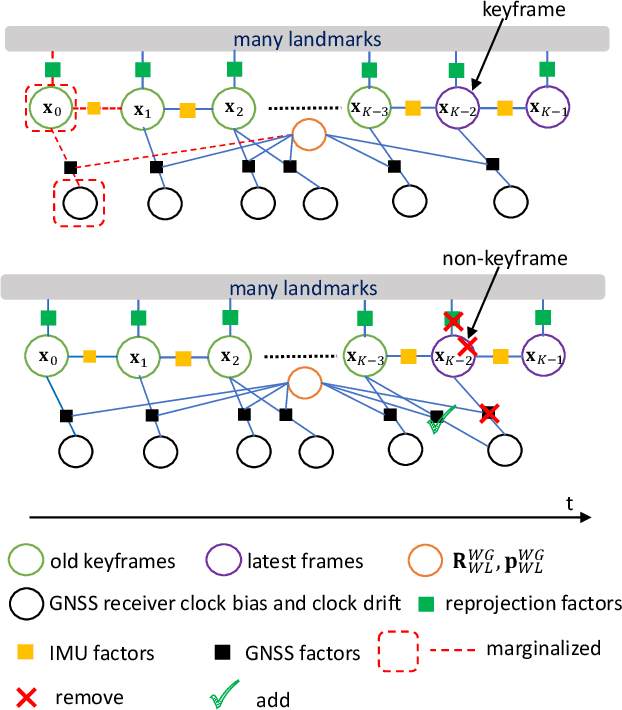
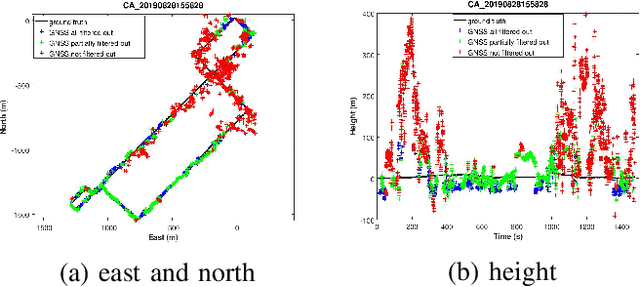

Fusing vision, Inertial Measurement Unit (IMU) and Global Navigation Satellite System (GNSS) information is a promising solution for accurate global positioning in complex urban scenes, because of the complementarity of the different sensors. Unlike the loose coupling approaches and the EKF-based approaches in the literature, we propose an optimization-based visual-inertial SLAM tightly coupled with raw GNSS measurements, including pseudoranges and Doppler shift, which is the first of such approaches to our knowledge. Reprojection error, IMU pre-integration error and raw GNSS measurement error are jointly optimized using bundle adjustment in a sliding window, and the asynchronism between images and raw GNSS measurements is considered. Marginalization is performed in the sliding window, and some methods dealing with noisy measurements and vulnerable situations are employed. Experimental results on public dataset in complex urban scenes prove that our proposed approach outperforms state-of-the-art visual-inertial SLAM, GNSS single point positioning, as well as a loose coupling approach, both in the scenes that mainly contain low-rise buildings and the scenes that contain urban canyons.
Zero-Shot Learning from Adversarial Feature Residual to Compact Visual Feature
Aug 29, 2020
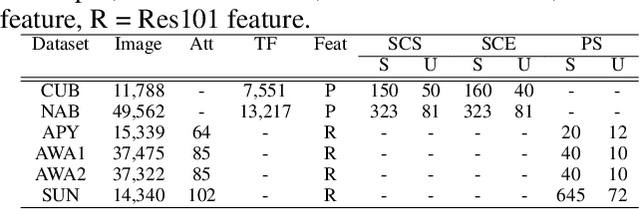
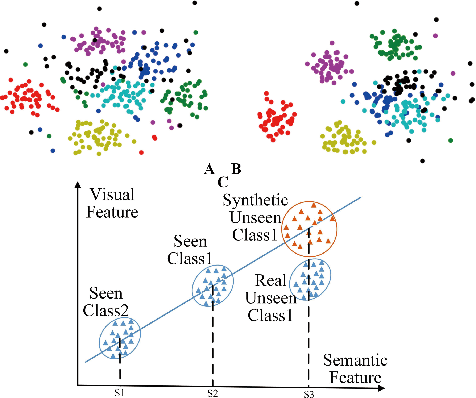

Recently, many zero-shot learning (ZSL) methods focused on learning discriminative object features in an embedding feature space, however, the distributions of the unseen-class features learned by these methods are prone to be partly overlapped, resulting in inaccurate object recognition. Addressing this problem, we propose a novel adversarial network to synthesize compact semantic visual features for ZSL, consisting of a residual generator, a prototype predictor, and a discriminator. The residual generator is to generate the visual feature residual, which is integrated with a visual prototype predicted via the prototype predictor for synthesizing the visual feature. The discriminator is to distinguish the synthetic visual features from the real ones extracted from an existing categorization CNN. Since the generated residuals are generally numerically much smaller than the distances among all the prototypes, the distributions of the unseen-class features synthesized by the proposed network are less overlapped. In addition, considering that the visual features from categorization CNNs are generally inconsistent with their semantic features, a simple feature selection strategy is introduced for extracting more compact semantic visual features. Extensive experimental results on six benchmark datasets demonstrate that our method could achieve a significantly better performance than existing state-of-the-art methods by 1.2-13.2% in most cases.