 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-guided Prompt Learning for Vision-language Models via Visual Granulation
Sep 04, 2025Prompt learning has recently attracted much attention for adapting pre-trained vision-language models (e.g., CLIP) to downstream recognition tasks. However, most of the existing CLIP-based prompt learning methods only show a limited ability for handling fine-grained datasets. To address this issue, we propose a causality-guided text prompt learning method via visual granulation for CLIP, called CaPL, where the explored visual granulation technique could construct sets of visual granules for the text prompt to capture subtle discrepancies among different fine-grained classes through casual inference. The CaPL method contains the following two modules: (1) An attribute disentanglement module is proposed to decompose visual features into non-individualized attributes (shared by some classes) and individualized attributes (specific to single classes) using a Brownian Bridge Diffusion Model; (2) A granule learning module is proposed to construct visual granules by integrating the aforementioned attributes for recognition under two causal inference strategies. Thanks to the learned visual granules, more discriminative text prompt is expected to be learned. Extensive experimental results on 15 datasets demonstrate that our CaPL method significantly outperforms the state-of-the-art prompt learning methods, especially on fine-grained datasets.
A Survey on Open-Set Image Recognition
Dec 25, 2023Open-set image recognition (OSR) aims to both classify known-class samples and identify unknown-class samples in the testing set, which supports robust classifiers in many realistic applications, such as autonomous driving, medical diagnosis, security monitoring, etc. In recent years, open-set recognition methods have achieved more and more attention, since it is usually difficult to obtain holistic information about the open world for model training. In this paper, we aim to summarize the up-to-date development of recent OSR methods, considering their rapid development in recent two or three years. Specifically, we firstly introduce a new taxonomy, under which we comprehensively review the existing DNN-based OSR methods. Then, we compare the performances of some typical and state-of-the-art OSR methods on both coarse-grained datasets and fine-grained datasets under both standard-dataset setting and cross-dataset setting, and further give the analysis of the comparison. Finally, we discuss some open issues and possible future directions in this community.
EAR-Net: Pursuing End-to-End Absolute Rotations from Multi-View Images
Oct 16, 2023Absolute rotation estimation is an important topic in 3D computer vision. Existing works in literature generally employ a multi-stage (at least two-stage) estimation strategy where multiple independent operations (feature matching, two-view rotation estimation, and rotation averaging) are implemented sequentially. However, such a multi-stage strategy inevitably leads to the accumulation of the errors caused by each involved operation, and degrades its final estimation on global rotations accordingly. To address this problem, we propose an End-to-end method for estimating Absolution Rotations from multi-view images based on deep neural Networks, called EAR-Net. The proposed EAR-Net consists of an epipolar confidence graph construction module and a confidence-aware rotation averaging module. The epipolar confidence graph construction module is explored to simultaneously predict pairwise relative rotations among the input images and their corresponding confidences, resulting in a weighted graph (called epipolar confidence graph). Based on this graph, the confidence-aware rotation averaging module, which is differentiable, is explored to predict the absolute rotations. Thanks to the introduced confidences of the relative rotations, the proposed EAR-Net could effectively handle outlier cases. Experimental results on three public datasets demonstrate that EAR-Net outperforms the state-of-the-art methods by a large margin in terms of accuracy and speed.
Recursive Counterfactual Deconfounding for Object Recognition
Sep 25, 2023



Image recognition is a classic and common task in the computer vision field, which has been widely applied in the past decade. Most existing methods in literature aim to learn discriminative features from labeled images for classification, however, they generally neglect confounders that infiltrate into the learned features, resulting in low performances for discriminating test images. To address this problem, we propose a Recursive Counterfactual Deconfounding model for object recognition in both closed-set and open-set scenarios based on counterfactual analysis, called RCD. The proposed model consists of a factual graph and a counterfactual graph, where the relationships among image features, model predictions, and confounders are built and updated recursively for learning more discriminative features. It performs in a recursive manner so that subtler counterfactual features could be learned and eliminated progressively, and both the discriminability and generalization of the proposed model could be improved accordingly. In addition, a negative correlation constraint is designed for alleviating the negative effects of the counterfactual features further at the model training stage. Extensive experimental results on both closed-set recognition task and open-set recognition task demonstrate that the proposed RCD model performs better than 11 state-of-the-art baselines significantly in most cases.
Two-in-One Depth: Bridging the Gap Between Monocular and Binocular Self-supervised Depth Estimation
Sep 02, 2023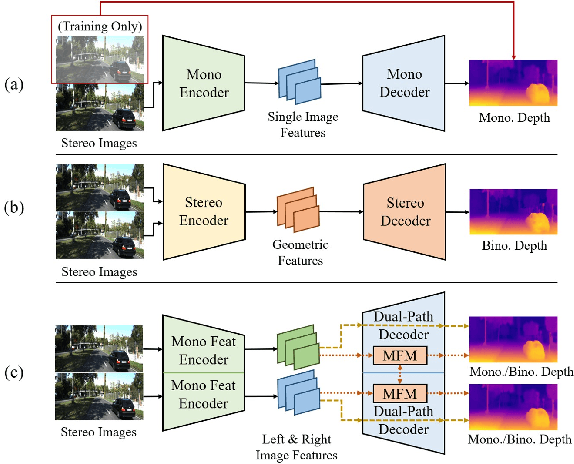
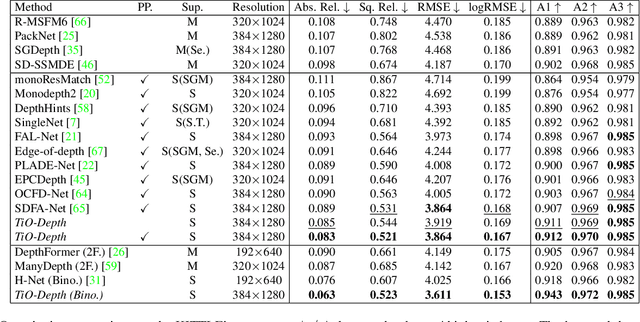
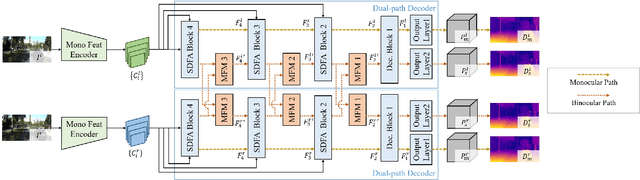
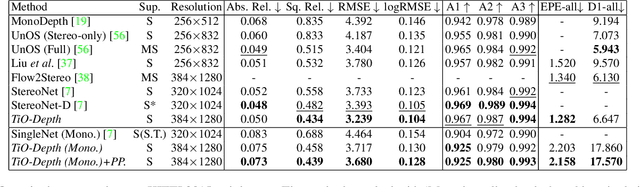
Monocular and binocular self-supervised depth estimations are two important and related tasks in computer vision, which aim to predict scene depths from single images and stereo image pairs respectively. In literature, the two tasks are usually tackled separately by two different kinds of models, and binocular models generally fail to predict depth from single images, while the prediction accuracy of monocular models is generally inferior to binocular models. In this paper, we propose a Two-in-One self-supervised depth estimation network, called TiO-Depth, which could not only compatibly handle the two tasks, but also improve the prediction accuracy. TiO-Depth employs a Siamese architecture and each sub-network of it could be used as a monocular depth estimation model. For binocular depth estimation, a Monocular Feature Matching module is proposed for incorporating the stereo knowledge between the two images, and the full TiO-Depth is used to predict depths. We also design a multi-stage joint-training strategy for improving the performances of TiO-Depth in both two tasks by combining the relative advantages of them. Experimental results on the KITTI, Cityscapes, and DDAD datasets demonstrate that TiO-Depth outperforms both the monocular and binocular state-of-the-art methods in most cases, and further verify the feasibility of a two-in-one network for monocular and binocular depth estimation. The code is available at https://github.com/ZM-Zhou/TiO-Depth_pytorch.
Complementary Frequency-Varying Awareness Network for Open-Set Fine-Grained Image Recognition
Jul 14, 2023Open-set image recognition is a challenging topic in computer vision. Most of the existing works in literature focus on learning more discriminative features from the input images, however, they are usually insensitive to the high- or low-frequency components in features, resulting in a decreasing performance on fine-grained image recognition. To address this problem, we propose a Complementary Frequency-varying Awareness Network that could better capture both high-frequency and low-frequency information, called CFAN. The proposed CFAN consists of three sequential modules: (i) a feature extraction module is introduced for learning preliminary features from the input images; (ii) a frequency-varying filtering module is designed to separate out both high- and low-frequency components from the preliminary features in the frequency domain via a frequency-adjustable filter; (iii) a complementary temporal aggregation module is designed for aggregating the high- and low-frequency components via two Long Short-Term Memory networks into discriminative features. Based on CFAN, we further propose an open-set fine-grained image recognition method, called CFAN-OSFGR, which learns image features via CFAN and classifies them via a linear classifier. Experimental results on 3 fine-grained datasets and 2 coarse-grained datasets demonstrate that CFAN-OSFGR performs significantly better than 9 state-of-the-art methods in most cases.
Spatial-Temporal Attention Network for Open-Set Fine-Grained Image Recognition
Nov 25, 2022Triggered by the success of transformers in various visual tasks, the spatial self-attention mechanism has recently attracted more and more attention in the computer vision community. However, we empirically found that a typical vision transformer with the spatial self-attention mechanism could not learn accurate attention maps for distinguishing different categories of fine-grained images. To address this problem, motivated by the temporal attention mechanism in brains, we propose a spatial-temporal attention network for learning fine-grained feature representations, called STAN, where the features learnt by implementing a sequence of spatial self-attention operations corresponding to multiple moments are aggregated progressively. The proposed STAN consists of four modules: a self-attention backbone module for learning a sequence of features with self-attention operations, a spatial feature self-organizing module for facilitating the model training, a spatial-temporal feature learning module for aggregating the re-organized features via a Long Short-Term Memory network, and a context-aware module that is implemented as the forget block of the spatial-temporal feature learning module for preserving/forgetting the long-term memory by utilizing contextual information. Then, we propose a STAN-based method for open-set fine-grained recognition by integrating the proposed STAN network with a linear classifier, called STAN-OSFGR. Extensive experimental results on 3 fine-grained datasets and 2 coarse-grained datasets demonstrate that the proposed STAN-OSFGR outperforms 9 state-of-the-art open-set recognition methods significantly in most cases.
Descriptor Distillation: a Teacher-Student-Regularized Framework for Learning Local Descriptors
Sep 23, 2022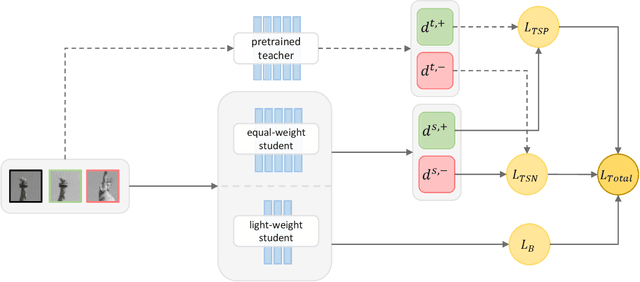
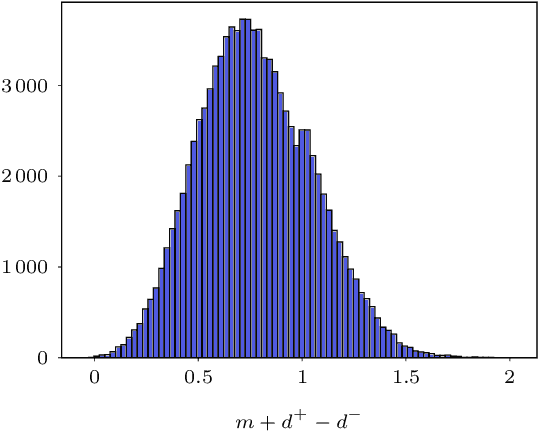
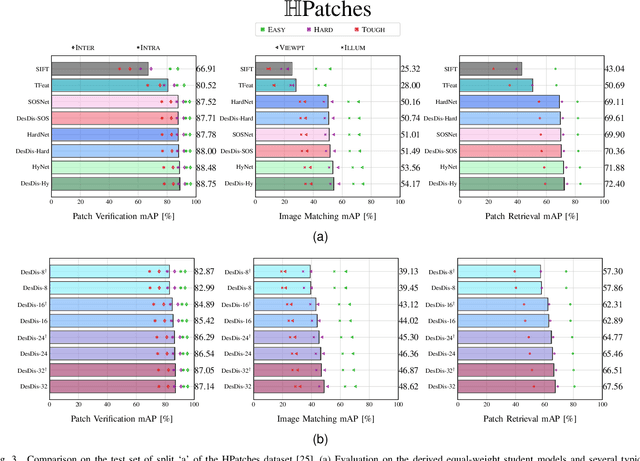

Learning a fast and discriminative patch descriptor is a challenging topic in computer vision. Recently, many existing works focus on training various descriptor learning networks by minimizing a triplet loss (or its variants), which is expected to decrease the distance between each positive pair and increase the distance between each negative pair. However, such an expectation has to be lowered due to the non-perfect convergence of network optimizer to a local solution. Addressing this problem and the open computational speed problem, we propose a Descriptor Distillation framework for local descriptor learning, called DesDis, where a student model gains knowledge from a pre-trained teacher model, and it is further enhanced via a designed teacher-student regularizer. This teacher-student regularizer is to constrain the difference between the positive (also negative) pair similarity from the teacher model and that from the student model, and we theoretically prove that a more effective student model could be trained by minimizing a weighted combination of the triplet loss and this regularizer, than its teacher which is trained by minimizing the triplet loss singly. Under the proposed DesDis, many existing descriptor networks could be embedded as the teacher model, and accordingly, both equal-weight and light-weight student models could be derived, which outperform their teacher in either accuracy or speed. Experimental results on 3 public datasets demonstrate that the equal-weight student models, derived from the proposed DesDis framework by utilizing three typical descriptor learning networks as teacher models, could achieve significantly better performances than their teachers and several other comparative methods. In addition, the derived light-weight models could achieve 8 times or even faster speeds than the comparative methods under similar patch verification performances
Self-distilled Feature Aggregation for Self-supervised Monocular Depth Estimation
Sep 15, 2022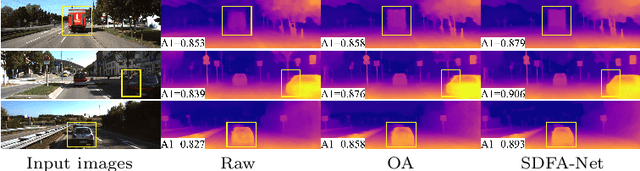
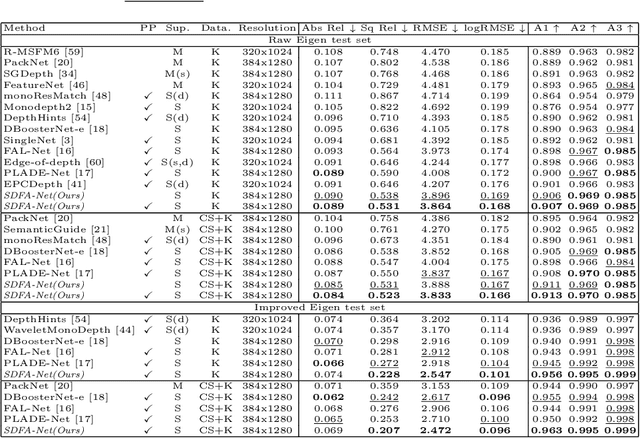
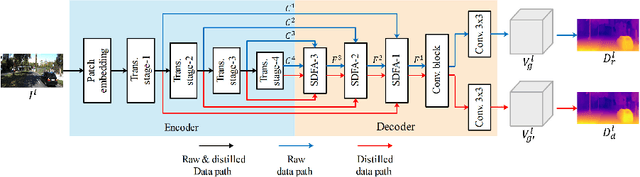
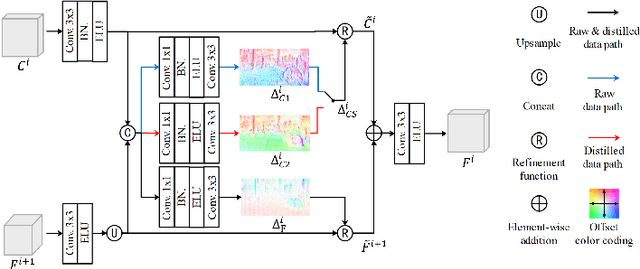
Self-supervised monocular depth estimation has received much attention recently in computer vision. Most of the existing works in literature aggregate multi-scale features for depth prediction via either straightforward concatenation or element-wise addition, however, such feature aggregation operations generally neglect the contextual consistency between multi-scale features. Addressing this problem, we propose the Self-Distilled Feature Aggregation (SDFA) module for simultaneously aggregating a pair of low-scale and high-scale features and maintaining their contextual consistency. The SDFA employs three branches to learn three feature offset maps respectively: one offset map for refining the input low-scale feature and the other two for refining the input high-scale feature under a designed self-distillation manner. Then, we propose an SDFA-based network for self-supervised monocular depth estimation, and design a self-distilled training strategy to train the proposed network with the SDFA module. Experimental results on the KITTI dataset demonstrate that the proposed method outperforms the comparative state-of-the-art methods in most cases. The code is available at https://github.com/ZM-Zhou/SDFA-Net_pytorch.
Orthogonal-Coding-Based Feature Generation for Transductive Open-Set Recognition via Dual-Space Consistent Sampling
Jul 13, 2022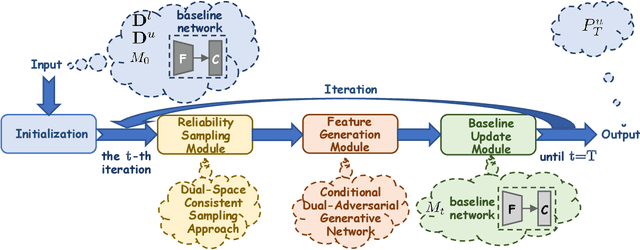

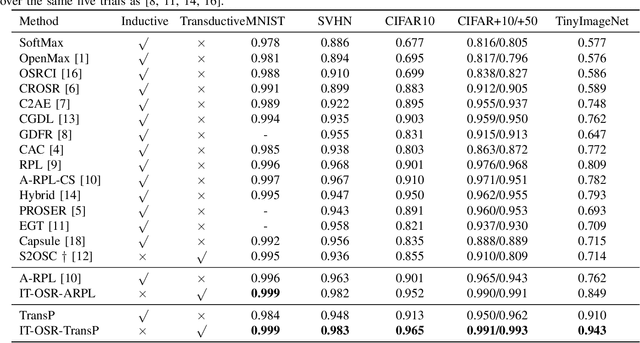

Open-set recognition (OSR) aims to simultaneously detect unknown-class samples and classify known-class samples. Most of the existing OSR methods are inductive methods, which generally suffer from the domain shift problem that the learned model from the known-class domain might be unsuitable for the unknown-class domain. Addressing this problem, inspired by the success of transductive learning for alleviating the domain shift problem in many other visual tasks, we propose an Iterative Transductive OSR framework, called IT-OSR, which implements three explored modules iteratively, including a reliability sampling module, a feature generation module, and a baseline update module. Specifically, at each iteration, a dual-space consistent sampling approach is presented in the explored reliability sampling module for selecting some relatively more reliable ones from the test samples according to their pseudo labels assigned by a baseline method, which could be an arbitrary inductive OSR method. Then, a conditional dual-adversarial generative network under an orthogonal coding condition is designed in the feature generation module to generate discriminative sample features of both known and unknown classes according to the selected test samples with their pseudo labels. Finally, the baseline method is updated for sample re-prediction in the baseline update module by jointly utilizing the generated features, the selected test samples with pseudo labels, and the training samples. Extensive experimental results on both the standard-dataset and the cross-dataset settings demonstrate that the derived transductive methods, by introducing two typical inductive OSR methods into the proposed IT-OSR framework, achieve better performances than 15 state-of-the-art methods in most cases.