 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-distilled Feature Aggregation for Self-supervised Monocular Depth Estimation
Paper and Code
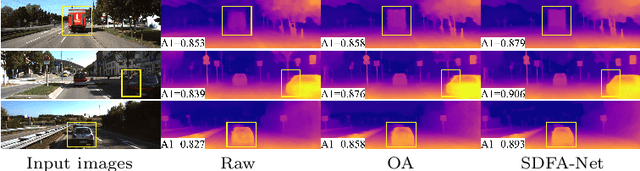
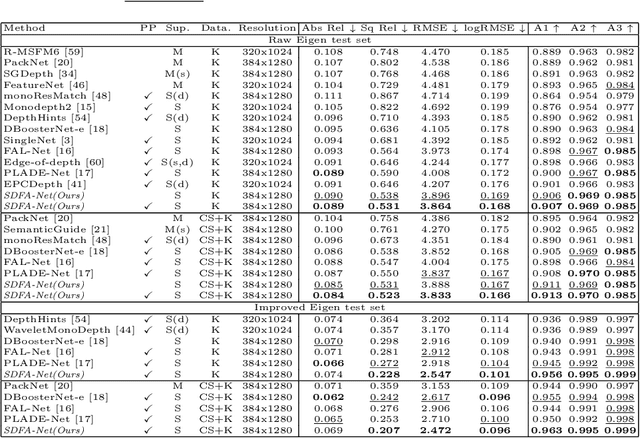
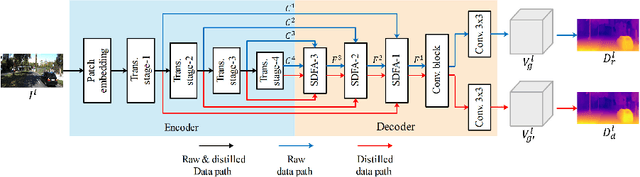
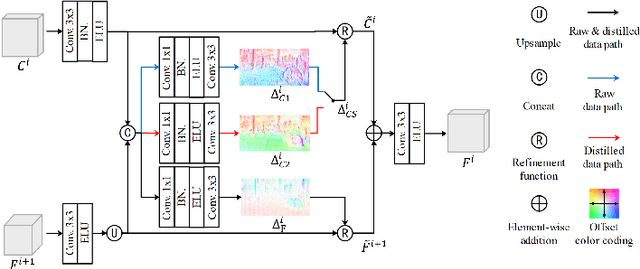
Self-supervised monocular depth estimation has received much attention recently in computer vision. Most of the existing works in literature aggregate multi-scale features for depth prediction via either straightforward concatenation or element-wise addition, however, such feature aggregation operations generally neglect the contextual consistency between multi-scale features. Addressing this problem, we propose the Self-Distilled Feature Aggregation (SDFA) module for simultaneously aggregating a pair of low-scale and high-scale features and maintaining their contextual consistency. The SDFA employs three branches to learn three feature offset maps respectively: one offset map for refining the input low-scale feature and the other two for refining the input high-scale feature under a designed self-distillation manner. Then, we propose an SDFA-based network for self-supervised monocular depth estimation, and design a self-distilled training strategy to train the proposed network with the SDFA module. Experimental results on the KITTI dataset demonstrate that the proposed method outperforms the comparative state-of-the-art methods in most cases. The code is available at https://github.com/ZM-Zhou/SDFA-Net_pytorch.