 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-in-One Depth: Bridging the Gap Between Monocular and Binocular Self-supervised Depth Estimation
Sep 02, 2023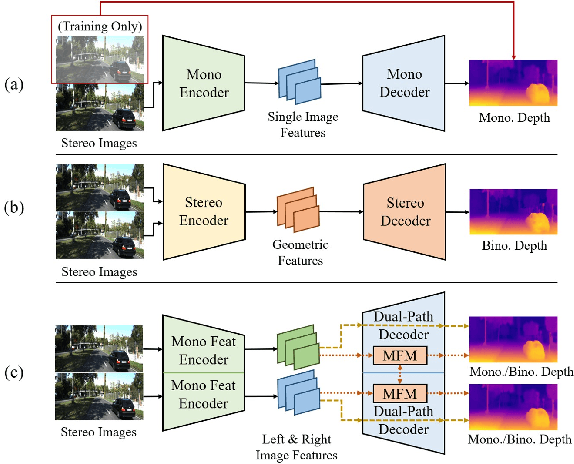
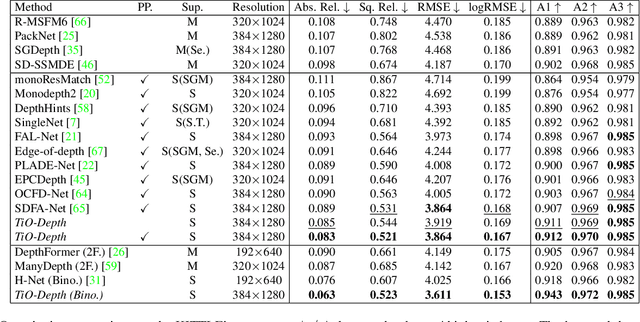
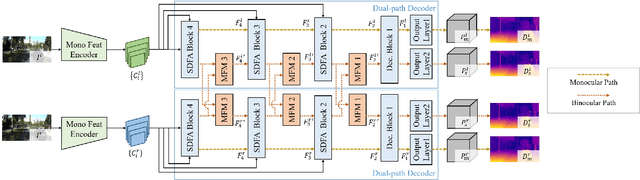
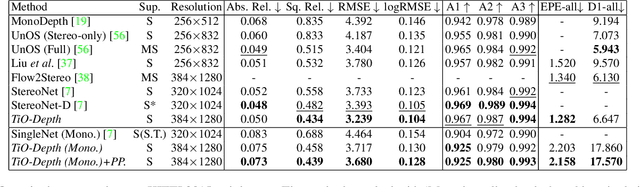
Monocular and binocular self-supervised depth estimations are two important and related tasks in computer vision, which aim to predict scene depths from single images and stereo image pairs respectively. In literature, the two tasks are usually tackled separately by two different kinds of models, and binocular models generally fail to predict depth from single images, while the prediction accuracy of monocular models is generally inferior to binocular models. In this paper, we propose a Two-in-One self-supervised depth estimation network, called TiO-Depth, which could not only compatibly handle the two tasks, but also improve the prediction accuracy. TiO-Depth employs a Siamese architecture and each sub-network of it could be used as a monocular depth estimation model. For binocular depth estimation, a Monocular Feature Matching module is proposed for incorporating the stereo knowledge between the two images, and the full TiO-Depth is used to predict depths. We also design a multi-stage joint-training strategy for improving the performances of TiO-Depth in both two tasks by combining the relative advantages of them. Experimental results on the KITTI, Cityscapes, and DDAD datasets demonstrate that TiO-Depth outperforms both the monocular and binocular state-of-the-art methods in most cases, and further verify the feasibility of a two-in-one network for monocular and binocular depth estimation. The code is available at https://github.com/ZM-Zhou/TiO-Depth_pytorch.
Self-distilled Feature Aggregation for Self-supervised Monocular Depth Estimation
Sep 15, 2022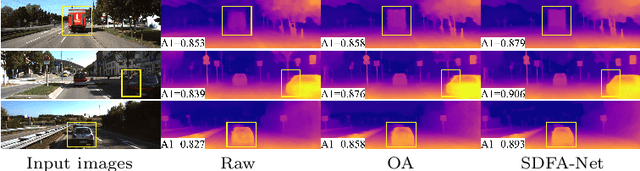
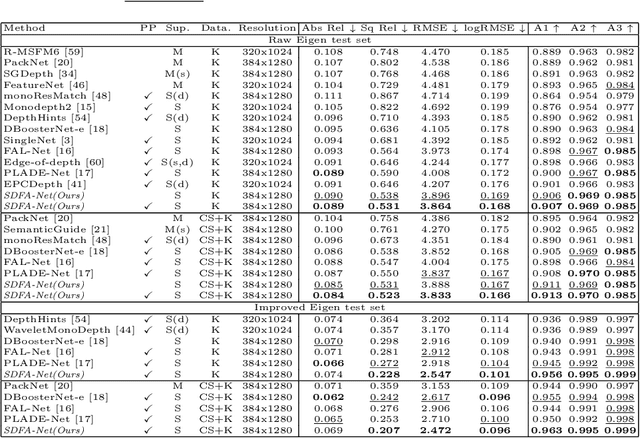
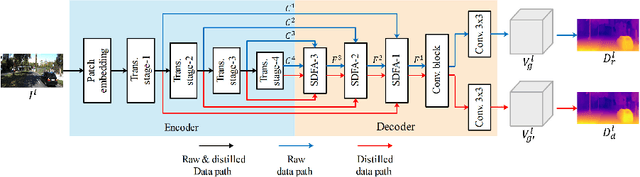
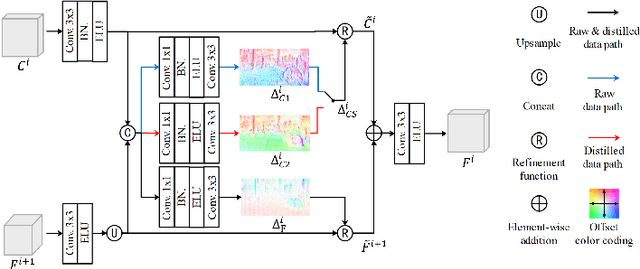
Self-supervised monocular depth estimation has received much attention recently in computer vision. Most of the existing works in literature aggregate multi-scale features for depth prediction via either straightforward concatenation or element-wise addition, however, such feature aggregation operations generally neglect the contextual consistency between multi-scale features. Addressing this problem, we propose the Self-Distilled Feature Aggregation (SDFA) module for simultaneously aggregating a pair of low-scale and high-scale features and maintaining their contextual consistency. The SDFA employs three branches to learn three feature offset maps respectively: one offset map for refining the input low-scale feature and the other two for refining the input high-scale feature under a designed self-distillation manner. Then, we propose an SDFA-based network for self-supervised monocular depth estimation, and design a self-distilled training strategy to train the proposed network with the SDFA module. Experimental results on the KITTI dataset demonstrate that the proposed method outperforms the comparative state-of-the-art methods in most cases. The code is available at https://github.com/ZM-Zhou/SDFA-Net_pytorch.
Learning Occlusion-Aware Coarse-to-Fine Depth Map for Self-supervised Monocular Depth Estimation
Mar 21, 2022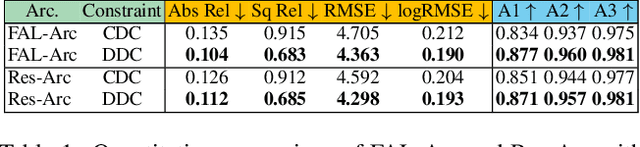
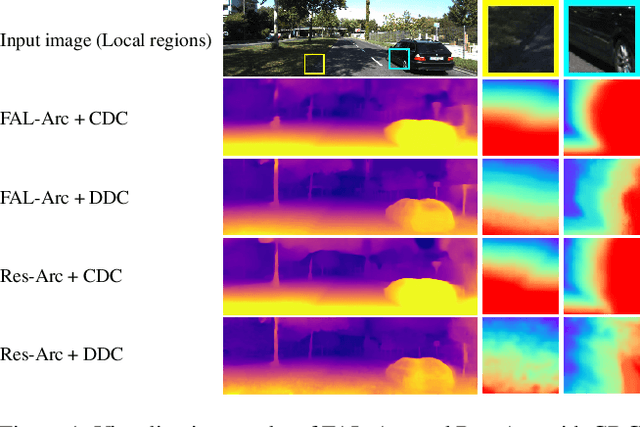
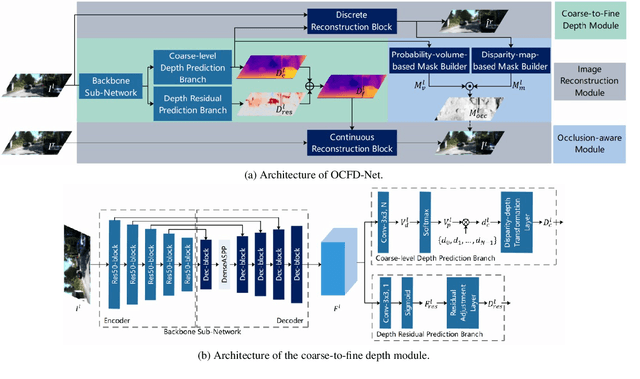
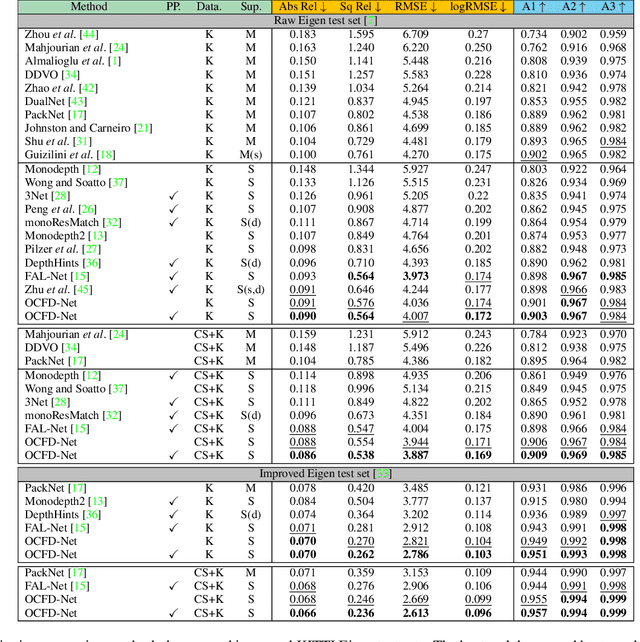
Self-supervised monocular depth estimation, aiming to learn scene depths from single images in a self-supervised manner, has received much attention recently. In spite of recent efforts in this field, how to learn accurate scene depths and alleviate the negative influence of occlusions for self-supervised depth estimation, still remains an open problem. Addressing this problem, we firstly empirically analyze the effects of both the continuous and discrete depth constraints which are widely used in the training process of many existing works. Then inspired by the above empirical analysis, we propose a novel network to learn an Occlusion-aware Coarse-to-Fine Depth map for self-supervised monocular depth estimation, called OCFD-Net. Given an arbitrary training set of stereo image pairs, the proposed OCFD-Net does not only employ a discrete depth constraint for learning a coarse-level depth map, but also employ a continuous depth constraint for learning a scene depth residual, resulting in a fine-level depth map. In addition, an occlusion-aware module is designed under the proposed OCFD-Net, which is able to improve the capability of the learnt fine-level depth map for handling occlusions. Extensive experimental results on the public KITTI and Make3D datasets demonstrate that the proposed method outperforms 20 existing state-of-the-art methods in most cases.