 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-in-One Depth: Bridging the Gap Between Monocular and Binocular Self-supervised Depth Estimation
Paper and Code
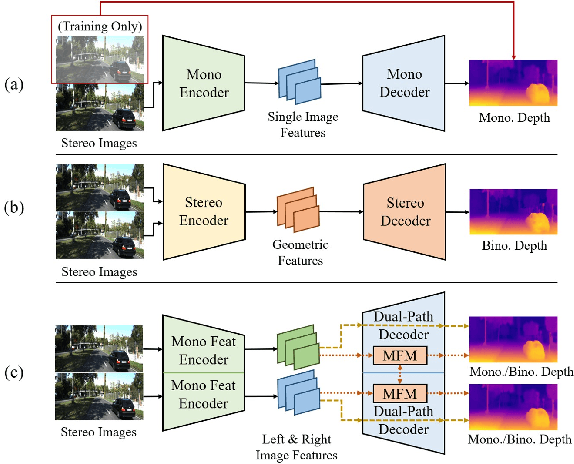
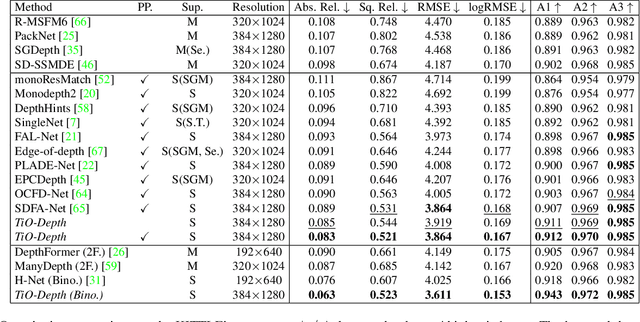
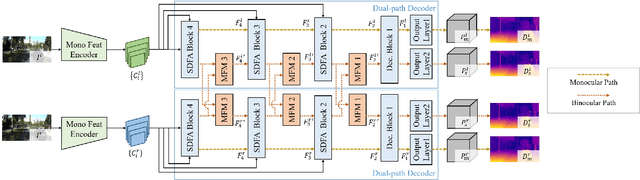
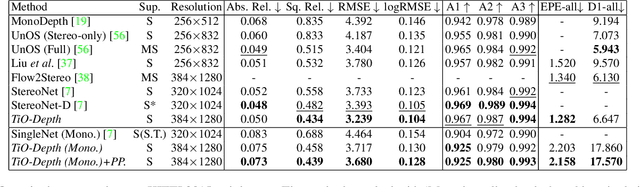
Monocular and binocular self-supervised depth estimations are two important and related tasks in computer vision, which aim to predict scene depths from single images and stereo image pairs respectively. In literature, the two tasks are usually tackled separately by two different kinds of models, and binocular models generally fail to predict depth from single images, while the prediction accuracy of monocular models is generally inferior to binocular models. In this paper, we propose a Two-in-One self-supervised depth estimation network, called TiO-Depth, which could not only compatibly handle the two tasks, but also improve the prediction accuracy. TiO-Depth employs a Siamese architecture and each sub-network of it could be used as a monocular depth estimation model. For binocular depth estimation, a Monocular Feature Matching module is proposed for incorporating the stereo knowledge between the two images, and the full TiO-Depth is used to predict depths. We also design a multi-stage joint-training strategy for improving the performances of TiO-Depth in both two tasks by combining the relative advantages of them. Experimental results on the KITTI, Cityscapes, and DDAD datasets demonstrate that TiO-Depth outperforms both the monocular and binocular state-of-the-art methods in most cases, and further verify the feasibility of a two-in-one network for monocular and binocular depth estimation. The code is available at https://github.com/ZM-Zhou/TiO-Depth_pytorch.