 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Open-Set Image Recognition
Dec 25, 2023Open-set image recognition (OSR) aims to both classify known-class samples and identify unknown-class samples in the testing set, which supports robust classifiers in many realistic applications, such as autonomous driving, medical diagnosis, security monitoring, etc. In recent years, open-set recognition methods have achieved more and more attention, since it is usually difficult to obtain holistic information about the open world for model training. In this paper, we aim to summarize the up-to-date development of recent OSR methods, considering their rapid development in recent two or three years. Specifically, we firstly introduce a new taxonomy, under which we comprehensively review the existing DNN-based OSR methods. Then, we compare the performances of some typical and state-of-the-art OSR methods on both coarse-grained datasets and fine-grained datasets under both standard-dataset setting and cross-dataset setting, and further give the analysis of the comparison. Finally, we discuss some open issues and possible future directions in this community.
Recursive Counterfactual Deconfounding for Object Recognition
Sep 25, 2023



Image recognition is a classic and common task in the computer vision field, which has been widely applied in the past decade. Most existing methods in literature aim to learn discriminative features from labeled images for classification, however, they generally neglect confounders that infiltrate into the learned features, resulting in low performances for discriminating test images. To address this problem, we propose a Recursive Counterfactual Deconfounding model for object recognition in both closed-set and open-set scenarios based on counterfactual analysis, called RCD. The proposed model consists of a factual graph and a counterfactual graph, where the relationships among image features, model predictions, and confounders are built and updated recursively for learning more discriminative features. It performs in a recursive manner so that subtler counterfactual features could be learned and eliminated progressively, and both the discriminability and generalization of the proposed model could be improved accordingly. In addition, a negative correlation constraint is designed for alleviating the negative effects of the counterfactual features further at the model training stage. Extensive experimental results on both closed-set recognition task and open-set recognition task demonstrate that the proposed RCD model performs better than 11 state-of-the-art baselines significantly in most cases.
Complementary Frequency-Varying Awareness Network for Open-Set Fine-Grained Image Recognition
Jul 14, 2023Open-set image recognition is a challenging topic in computer vision. Most of the existing works in literature focus on learning more discriminative features from the input images, however, they are usually insensitive to the high- or low-frequency components in features, resulting in a decreasing performance on fine-grained image recognition. To address this problem, we propose a Complementary Frequency-varying Awareness Network that could better capture both high-frequency and low-frequency information, called CFAN. The proposed CFAN consists of three sequential modules: (i) a feature extraction module is introduced for learning preliminary features from the input images; (ii) a frequency-varying filtering module is designed to separate out both high- and low-frequency components from the preliminary features in the frequency domain via a frequency-adjustable filter; (iii) a complementary temporal aggregation module is designed for aggregating the high- and low-frequency components via two Long Short-Term Memory networks into discriminative features. Based on CFAN, we further propose an open-set fine-grained image recognition method, called CFAN-OSFGR, which learns image features via CFAN and classifies them via a linear classifier. Experimental results on 3 fine-grained datasets and 2 coarse-grained datasets demonstrate that CFAN-OSFGR performs significantly better than 9 state-of-the-art methods in most cases.
Spatial-Temporal Attention Network for Open-Set Fine-Grained Image Recognition
Nov 25, 2022Triggered by the success of transformers in various visual tasks, the spatial self-attention mechanism has recently attracted more and more attention in the computer vision community. However, we empirically found that a typical vision transformer with the spatial self-attention mechanism could not learn accurate attention maps for distinguishing different categories of fine-grained images. To address this problem, motivated by the temporal attention mechanism in brains, we propose a spatial-temporal attention network for learning fine-grained feature representations, called STAN, where the features learnt by implementing a sequence of spatial self-attention operations corresponding to multiple moments are aggregated progressively. The proposed STAN consists of four modules: a self-attention backbone module for learning a sequence of features with self-attention operations, a spatial feature self-organizing module for facilitating the model training, a spatial-temporal feature learning module for aggregating the re-organized features via a Long Short-Term Memory network, and a context-aware module that is implemented as the forget block of the spatial-temporal feature learning module for preserving/forgetting the long-term memory by utilizing contextual information. Then, we propose a STAN-based method for open-set fine-grained recognition by integrating the proposed STAN network with a linear classifier, called STAN-OSFGR. Extensive experimental results on 3 fine-grained datasets and 2 coarse-grained datasets demonstrate that the proposed STAN-OSFGR outperforms 9 state-of-the-art open-set recognition methods significantly in most cases.
Orthogonal-Coding-Based Feature Generation for Transductive Open-Set Recognition via Dual-Space Consistent Sampling
Jul 13, 2022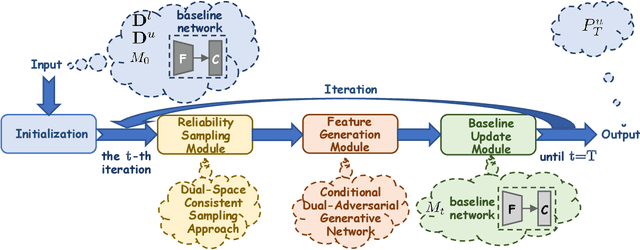

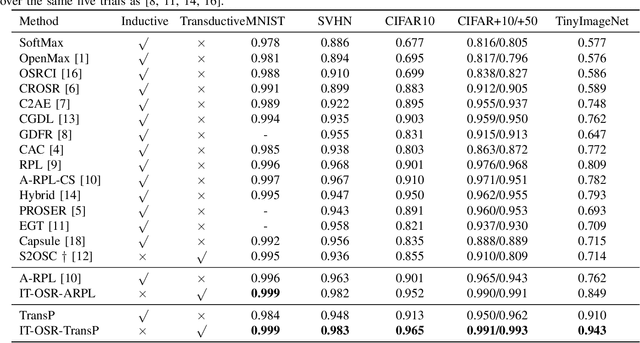

Open-set recognition (OSR) aims to simultaneously detect unknown-class samples and classify known-class samples. Most of the existing OSR methods are inductive methods, which generally suffer from the domain shift problem that the learned model from the known-class domain might be unsuitable for the unknown-class domain. Addressing this problem, inspired by the success of transductive learning for alleviating the domain shift problem in many other visual tasks, we propose an Iterative Transductive OSR framework, called IT-OSR, which implements three explored modules iteratively, including a reliability sampling module, a feature generation module, and a baseline update module. Specifically, at each iteration, a dual-space consistent sampling approach is presented in the explored reliability sampling module for selecting some relatively more reliable ones from the test samples according to their pseudo labels assigned by a baseline method, which could be an arbitrary inductive OSR method. Then, a conditional dual-adversarial generative network under an orthogonal coding condition is designed in the feature generation module to generate discriminative sample features of both known and unknown classes according to the selected test samples with their pseudo labels. Finally, the baseline method is updated for sample re-prediction in the baseline update module by jointly utilizing the generated features, the selected test samples with pseudo labels, and the training samples. Extensive experimental results on both the standard-dataset and the cross-dataset settings demonstrate that the derived transductive methods, by introducing two typical inductive OSR methods into the proposed IT-OSR framework, achieve better performances than 15 state-of-the-art methods in most cases.
Face representation by deep learning: a linear encoding in a parameter space?
Oct 22, 2019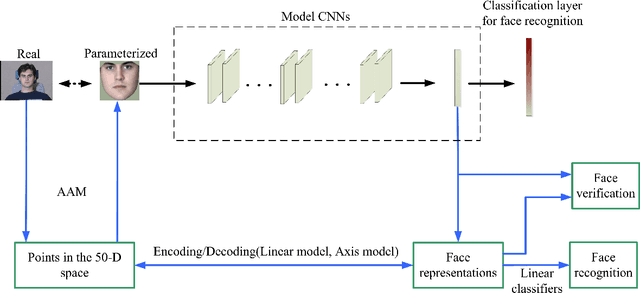
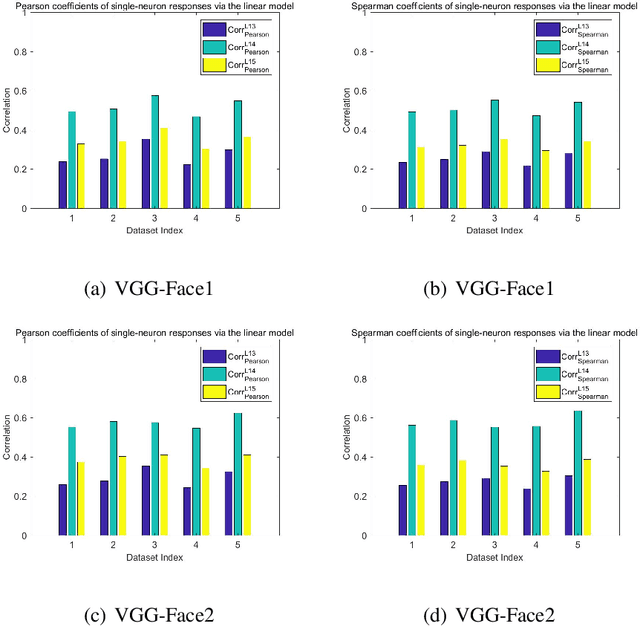

Recently, Convolutional Neural Networks (CNNs) have achieved tremendous performances on face recognition, and one popular perspective regarding CNNs' success is that CNNs could learn discriminative face representations from face images with complex image feature encoding. However, it is still unclear what is the intrinsic mechanism of face representation in CNNs. In this work, we investigate this problem by formulating face images as points in a shape-appearance parameter space, and our results demonstrate that: (i) The encoding and decoding of the neuron responses (representations) to face images in CNNs could be achieved under a linear model in the parameter space, in agreement with the recent discovery in primate IT face neurons, but different from the aforementioned perspective on CNNs' face representation with complex image feature encoding; (ii) The linear model for face encoding and decoding in the parameter space could achieve close or even better performances on face recognition and verification than state-of-the-art CNNs, which might provide new lights on the design strategies for face recognition systems; (iii) The neuron responses to face images in CNNs could not be adequately modelled by the axis model, a model recently proposed on face modelling in primate IT cortex. All these results might shed some lights on the often complained blackbox nature behind CNNs' tremendous performances on face recognition.