 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace representation by deep learning: a linear encoding in a parameter space?
Paper and Code
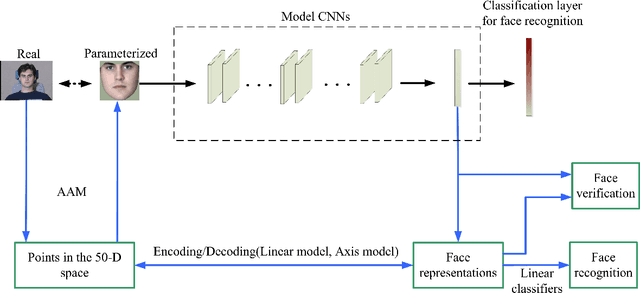
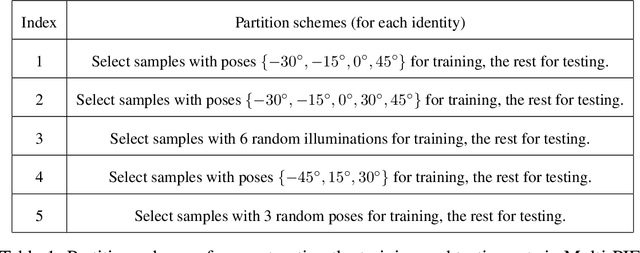
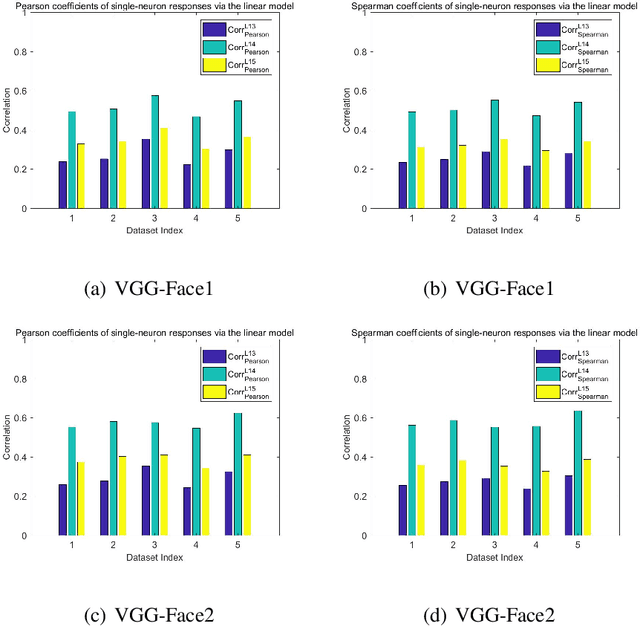

Recently, Convolutional Neural Networks (CNNs) have achieved tremendous performances on face recognition, and one popular perspective regarding CNNs' success is that CNNs could learn discriminative face representations from face images with complex image feature encoding. However, it is still unclear what is the intrinsic mechanism of face representation in CNNs. In this work, we investigate this problem by formulating face images as points in a shape-appearance parameter space, and our results demonstrate that: (i) The encoding and decoding of the neuron responses (representations) to face images in CNNs could be achieved under a linear model in the parameter space, in agreement with the recent discovery in primate IT face neurons, but different from the aforementioned perspective on CNNs' face representation with complex image feature encoding; (ii) The linear model for face encoding and decoding in the parameter space could achieve close or even better performances on face recognition and verification than state-of-the-art CNNs, which might provide new lights on the design strategies for face recognition systems; (iii) The neuron responses to face images in CNNs could not be adequately modelled by the axis model, a model recently proposed on face modelling in primate IT cortex. All these results might shed some lights on the often complained blackbox nature behind CNNs' tremendous performances on face recognition.