 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCSS-Net: Superpoint Constrained Semi-supervised Segmentation Network for 3D Indoor Scenes
Jul 09, 2021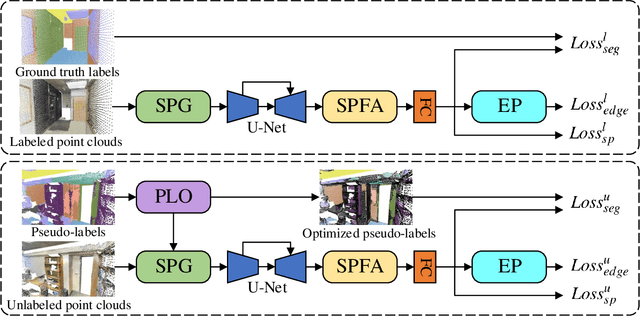

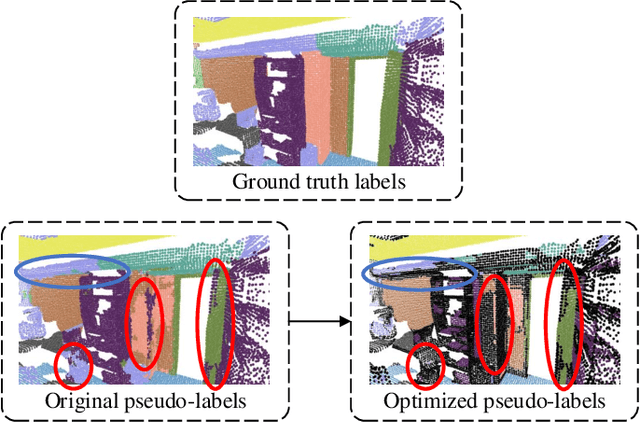

Many existing deep neural networks (DNNs) for 3D point cloud semantic segmentation require a large amount of fully labeled training data. However, manually assigning point-level labels on the complex scenes is time-consuming. While unlabeled point clouds can be easily obtained from sensors or reconstruction, we propose a superpoint constrained semi-supervised segmentation network for 3D point clouds, named as SCSS-Net. Specifically, we use the pseudo labels predicted from unlabeled point clouds for self-training, and the superpoints produced by geometry-based and color-based Region Growing algorithms are combined to modify and delete pseudo labels with low confidence. Additionally, we propose an edge prediction module to constrain the features from edge points of geometry and color. A superpoint feature aggregation module and superpoint feature consistency loss functions are introduced to smooth the point features in each superpoint. Extensive experimental results on two 3D public indoor datasets demonstrate that our method can achieve better performance than some state-of-the-art point cloud segmentation networks and some popular semi-supervised segmentation methods with few labeled scenes.
Rotation Transformation Network: Learning View-Invariant Point Cloud for Classification and Segmentation
Jul 07, 2021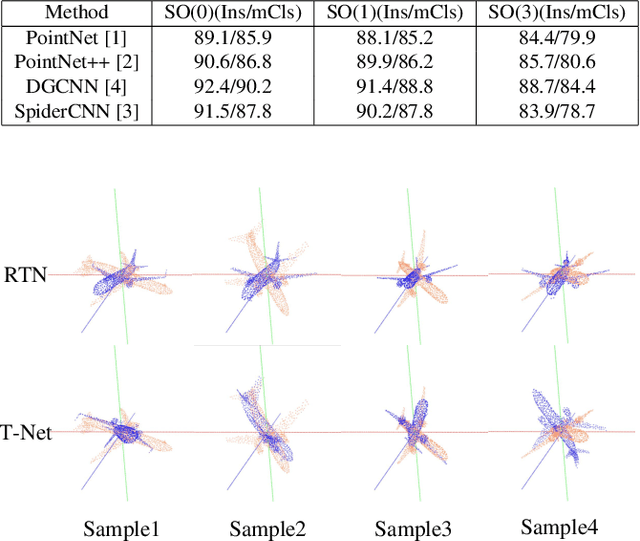
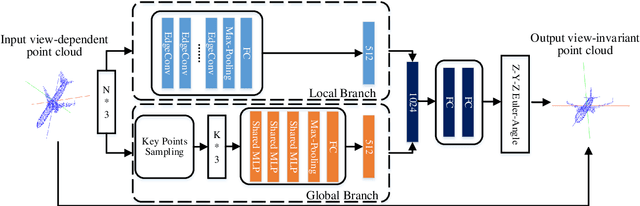

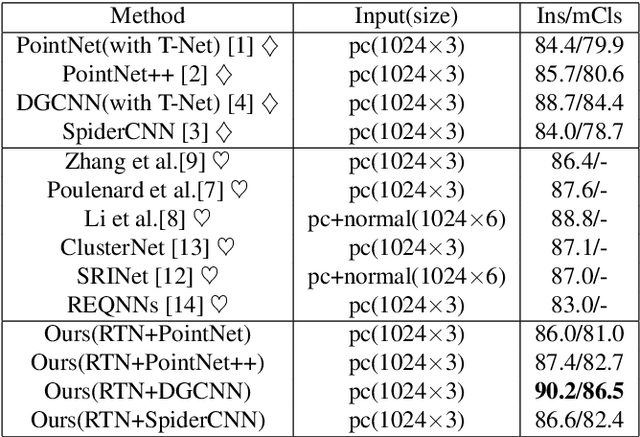
Many recent works show that a spatial manipulation module could boost the performances of deep neural networks (DNNs) for 3D point cloud analysis. In this paper, we aim to provide an insight into spatial manipulation modules. Firstly, we find that the smaller the rotational degree of freedom (RDF) of objects is, the more easily these objects are handled by these DNNs. Then, we investigate the effect of the popular T-Net module and find that it could not reduce the RDF of objects. Motivated by the above two issues, we propose a rotation transformation network for point cloud analysis, called RTN, which could reduce the RDF of input 3D objects to 0. The RTN could be seamlessly inserted into many existing DNNs for point cloud analysis. Extensive experimental results on 3D point cloud classification and segmentation tasks demonstrate that the proposed RTN could improve the performances of several state-of-the-art methods significantly.
GA-NET: Global Attention Network for Point Cloud Semantic Segmentation
Jul 07, 2021
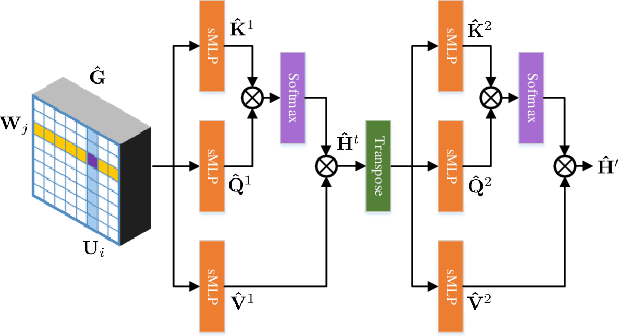


How to learn long-range dependencies from 3D point clouds is a challenging problem in 3D point cloud analysis. Addressing this problem, we propose a global attention network for point cloud semantic segmentation, named as GA-Net, consisting of a point-independent global attention module and a point-dependent global attention module for obtaining contextual information of 3D point clouds in this paper. The point-independent global attention module simply shares a global attention map for all 3D points. In the point-dependent global attention module, for each point, a novel random cross attention block using only two randomly sampled subsets is exploited to learn the contextual information of all the points. Additionally, we design a novel point-adaptive aggregation block to replace linear skip connection for aggregating more discriminate features. Extensive experimental results on three 3D public datasets demonstrate that our method outperforms state-of-the-art methods in most cases.
Segmenting 3D Hybrid Scenes via Zero-Shot Learning
Jul 04, 2021
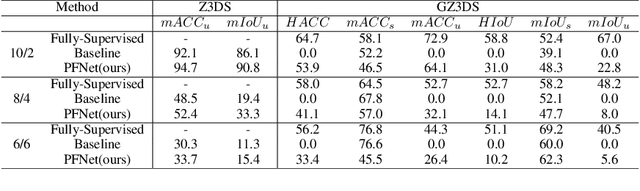
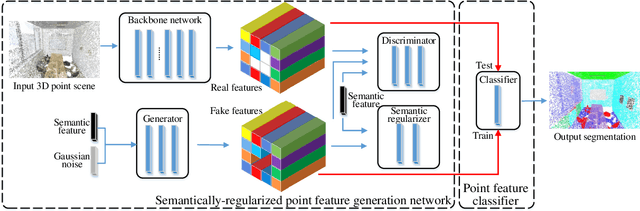
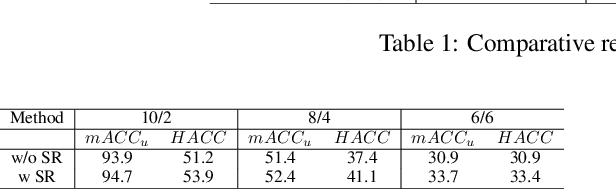
This work is to tackle the problem of point cloud semantic segmentation for 3D hybrid scenes under the framework of zero-shot learning. Here by hybrid, we mean the scene consists of both seen-class and unseen-class 3D objects, a more general and realistic setting in application. To our knowledge, this problem has not been explored in the literature. To this end, we propose a network to synthesize point features for various classes of objects by leveraging the semantic features of both seen and unseen object classes, called PFNet. The proposed PFNet employs a GAN architecture to synthesize point features, where the semantic relationship between seen-class and unseen-class features is consolidated by adapting a new semantic regularizer, and the synthesized features are used to train a classifier for predicting the labels of the testing 3D scene points. Besides we also introduce two benchmarks for algorithmic evaluation by re-organizing the public S3DIS and ScanNet datasets under six different data splits. Experimental results on the two benchmarks validate our proposed method, and we hope our introduced two benchmarks and methodology could be of help for more research on this new direction.