 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoDETRNext: Next-generation Accurate and Efficient Monocular 3D Object Detection Method
May 24, 2024



Monocular vision-based 3D object detection is crucial in various sectors, yet existing methods face significant challenges in terms of accuracy and computational efficiency. Building on the successful strategies in 2D detection and depth estimation, we propose MonoDETRNext, which seeks to optimally balance precision and processing speed. Our methodology includes the development of an efficient hybrid visual encoder, enhancement of depth prediction mechanisms, and introduction of an innovative query generation strategy, augmented by an advanced depth predictor. Building on MonoDETR, MonoDETRNext introduces two variants: MonoDETRNext-F, which emphasizes speed, and MonoDETRNext-A, which focuses on precision. We posit that MonoDETRNext establishes a new benchmark in monocular 3D object detection and opens avenues for future research. We conducted an exhaustive evaluation demonstrating the model's superior performance against existing solutions. Notably, MonoDETRNext-A demonstrated a 4.60% improvement in the AP3D metric on the KITTI test benchmark over MonoDETR, while MonoDETRNext-F showed a 2.21% increase. Additionally, the computational efficiency of MonoDETRNext-F slightly exceeds that of its predecessor.
MoD2T:Model-Data-Driven Motion-Static Object Tracking Method
Dec 29, 2023The domain of Multi-Object Tracking (MOT) is of paramount significance within the realm of video analysis. However, both traditional methodologies and deep learning-based approaches within this domain exhibit inherent limitations. Deep learning methods driven exclusively by data exhibit challenges in accurately discerning the motion states of objects, while traditional methods relying on comprehensive mathematical models may suffer from suboptimal tracking precision. To address these challenges, we introduce the Model-Data-Driven Motion-Static Object Tracking Method (MoD2T). We propose a novel architecture that adeptly amalgamates traditional mathematical modeling with deep learning-based MOT frameworks, thereby effectively mitigating the limitations associated with sole reliance on established methodologies or advanced deep learning techniques. MoD2T's fusion of mathematical modeling and deep learning augments the precision of object motion determination, consequently enhancing tracking accuracy. Our empirical experiments robustly substantiate MoD2T's efficacy across a diverse array of scenarios, including UAV aerial surveillance and street-level tracking. To assess MoD2T's proficiency in discerning object motion states, we introduce MVF1 metric. This novel performance metric is designed to measure the accuracy of motion state classification, providing a comprehensive evaluation of MoD2T's performance. Meticulous experiments substantiate the rationale behind MVF1's formulation. To provide a comprehensive assessment of MoD2T's performance, we meticulously annotate diverse datasets and subject MoD2T to rigorous testing. The achieved MVF1 scores, which measure the accuracy of motion state classification, are particularly noteworthy in scenarios marked by minimal or mild camera motion, with values of 0.774 on the KITTI dataset, 0.521 on MOT17, and 0.827 on UAVDT.
MO-YOLO: End-to-End Multiple-Object Tracking Method with YOLO and MOTR
Oct 26, 2023This paper aims to address critical issues in the field of Multi-Object Tracking (MOT) by proposing an efficient and computationally resource-efficient end-to-end multi-object tracking model, named MO-YOLO. Traditional MOT methods typically involve two separate steps: object detection and object tracking, leading to computational complexity and error propagation issues. Recent research has demonstrated outstanding performance in end-to-end MOT models based on Transformer architectures, but they require substantial hardware support. MO-YOLO combines the strengths of YOLO and RT-DETR models to construct a high-efficiency, lightweight, and resource-efficient end-to-end multi-object tracking network, offering new opportunities in the multi-object tracking domain. On the MOT17 dataset, MOTR\cite{zeng2022motr} requires training with 8 GeForce 2080 Ti GPUs for 4 days to achieve satisfactory results, while MO-YOLO only requires 1 GeForce 2080 Ti GPU and 12 hours of training to achieve comparable performance.
A Creative Industry Image Generation Dataset Based on Captions
Nov 16, 2022Most image generation methods are difficult to precisely control the properties of the generated images, such as structure, scale, shape, etc., which limits its large-scale application in creative industries such as conceptual design and graphic design, and so on. Using the prompt and the sketch is a practical solution for controllability. Existing datasets lack either prompt or sketch and are not designed for the creative industry. Here is the main contribution of our work. a) This is the first dataset that covers the 4 most important areas of creative industry domains and is labeled with prompt and sketch. b) We provide multiple reference images in the test set and fine-grained scores for each reference which are useful for measurement. c) We apply two state-of-the-art models to our dataset and then find some shortcomings, such as the prompt is more highly valued than the sketch.
Towards Micro-video Thumbnail Selection via a Multi-label Visual-semantic Embedding Model
Feb 07, 2022The thumbnail, as the first sight of a micro-video, plays a pivotal role in attracting users to click and watch. While in the real scenario, the more the thumbnails satisfy the users, the more likely the micro-videos will be clicked. In this paper, we aim to select the thumbnail of a given micro-video that meets most users` interests. Towards this end, we present a multi-label visual-semantic embedding model to estimate the similarity between the pair of each frame and the popular topics that users are interested in. In this model, the visual and textual information is embedded into a shared semantic space, whereby the similarity can be measured directly, even the unseen words. Moreover, to compare the frame to all words from the popular topics, we devise an attention embedding space associated with the semantic-attention projection. With the help of these two embedding spaces, the popularity score of a frame, which is defined by the sum of similarity scores over the corresponding visual information and popular topic pairs, is achieved. Ultimately, we fuse the visual representation score and the popularity score of each frame to select the attractive thumbnail for the given micro-video. Extensive experiments conducted on a real-world dataset have well-verified that our model significantly outperforms several state-of-the-art baselines.
A Benchmark Dataset for Micro-video Thumbnail Selection
Dec 30, 2021



The thumbnail, as the first sight of a micro-video, plays a pivotal role in attracting users to click and watch. Although several pioneer efforts have been dedicated to jointly considering the quality and representativeness for selecting the thumbnail, they are limited in exploring the influence of users` interests. While in the real scenario, the more the thumbnails satisfy the users, the more likely the micro-videos will be clicked. In this paper, we aim to select the thumbnail of a given micro-video that meets most users` interests. Towards this end, we construct a large-scale dataset for the micro-video thumbnails. Ultimately, we conduct several baselines on the dataset and demonstrate the effectiveness of our dataset.
Hardness Sampling for Self-Training Based Transductive Zero-Shot Learning
Jun 01, 2021
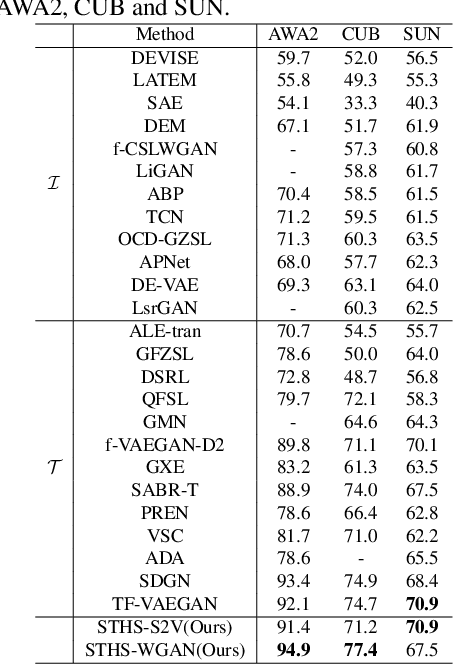


Transductive zero-shot learning (T-ZSL) which could alleviate the domain shift problem in existing ZSL works, has received much attention recently. However, an open problem in T-ZSL: how to effectively make use of unseen-class samples for training, still remains. Addressing this problem, we first empirically analyze the roles of unseen-class samples with different degrees of hardness in the training process based on the uneven prediction phenomenon found in many ZSL methods, resulting in three observations. Then, we propose two hardness sampling approaches for selecting a subset of diverse and hard samples from a given unseen-class dataset according to these observations. The first one identifies the samples based on the class-level frequency of the model predictions while the second enhances the former by normalizing the class frequency via an approximate class prior estimated by an explored prior estimation algorithm. Finally, we design a new Self-Training framework with Hardness Sampling for T-ZSL, called STHS, where an arbitrary inductive ZSL method could be seamlessly embedded and it is iteratively trained with unseen-class samples selected by the hardness sampling approach. We introduce two typical ZSL methods into the STHS framework and extensive experiments demonstrate that the derived T-ZSL methods outperform many state-of-the-art methods on three public benchmarks. Besides, we note that the unseen-class dataset is separately used for training in some existing transductive generalized ZSL (T-GZSL) methods, which is not strict for a GZSL task. Hence, we suggest a more strict T-GZSL data setting and establish a competitive baseline on this setting by introducing the proposed STHS framework to T-GZSL.