 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservability Analysis and Composite Disturbance Filtering for a Bar Tethered to Dual UAVs Subject to Multi-source Disturbances
Dec 10, 2025Cooperative suspended aerial transportation is highly susceptible to multi-source disturbances such as aerodynamic effects and thrust uncertainties. To achieve precise load manipulation, existing methods often rely on extra sensors to measure cable directions or the payload's pose, which increases the system cost and complexity. A fundamental question remains: is the payload's pose observable under multi-source disturbances using only the drones' odometry information? To answer this question, this work focuses on the two-drone-bar system and proves that the whole system is observable when only two or fewer types of lumped disturbances exist by using the observability rank criterion. To the best of our knowledge, we are the first to present such a conclusion and this result paves the way for more cost-effective and robust systems by minimizing their sensor suites. Next, to validate this analysis, we consider the situation where the disturbances are only exerted on the drones, and develop a composite disturbance filtering scheme. A disturbance observer-based error-state extended Kalman filter is designed for both state and disturbance estimation, which renders improved estimation performance for the whole system evolving on the manifold $(\mathbb{R}^3)^2\times(TS^2)^3$. Our simulation and experimental tests have validated that it is possible to fully estimate the state and disturbance of the system with only odometry information of the drones.
Pursuing 3D Scene Structures with Optical Satellite Images from Affine Reconstruction to Euclidean Reconstruction
Jan 16, 2022
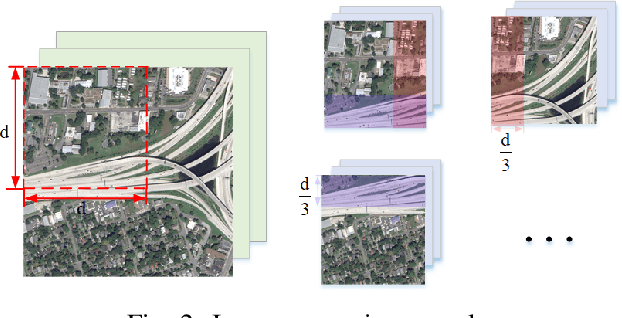
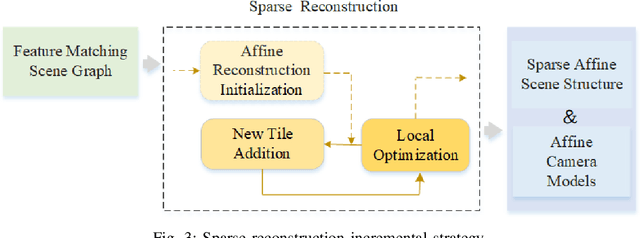

How to use multiple optical satellite images to recover the 3D scene structure is a challenging and important problem in the remote sensing field. Most existing methods in literature have been explored based on the classical RPC (rational polynomial camera) model which requires at least 39 GCPs (ground control points), however, it is not trivial to obtain such a large number of GCPs in many real scenes. Addressing this problem, we propose a hierarchical reconstruction framework based on multiple optical satellite images, which needs only 4 GCPs. The proposed framework is composed of an affine dense reconstruction stage and a followed affine-to-Euclidean upgrading stage: At the affine dense reconstruction stage, an affine dense reconstruction approach is explored for pursuing the 3D affine scene structure without any GCP from input satellite images. Then at the affine-to-Euclidean upgrading stage, the obtained 3D affine structure is upgraded to a Euclidean one with 4 GCPs. Experimental results on two public datasets demonstrate that the proposed method significantly outperforms three state-of-the-art methods in most cases.
Unsupervised monocular stereo matching
Dec 31, 2018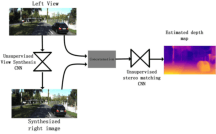
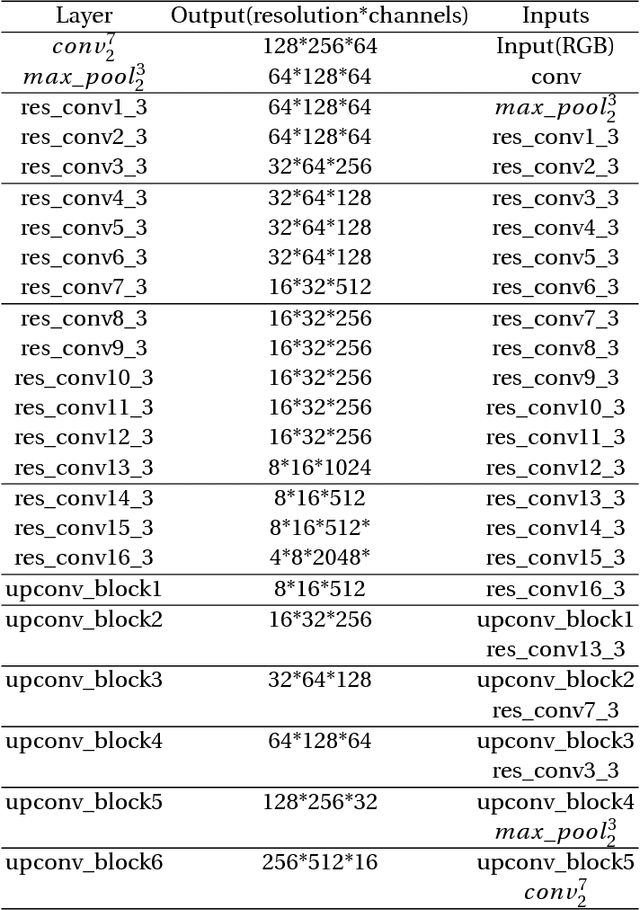

At present, deep learning has been applied more and more in monocular image depth estimation and has shown promising results. The current more ideal method for monocular depth estimation is the supervised learning based on ground truth depth, but this method requires an abundance of expensive ground truth depth as the supervised labels. Therefore, researchers began to work on unsupervised depth estimation methods. Although the accuracy of unsupervised depth estimation method is still lower than that of supervised method, it is a promising research direction. In this paper, Based on the experimental results that the stereo matching models outperforms monocular depth estimation models under the same unsupervised depth estimation model, we proposed an unsupervised monocular vision stereo matching method. In order to achieve the monocular stereo matching, we constructed two unsupervised deep convolution network models, one was to reconstruct the right view from the left view, and the other was to estimate the depth map using the reconstructed right view and the original left view. The two network models are piped together during the test phase. The output results of this method outperforms the current mainstream unsupervised depth estimation method in the challenging KITTI dataset.