 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Learning from Adversarial Feature Residual to Compact Visual Feature
Paper and Code
Aug 29, 2020
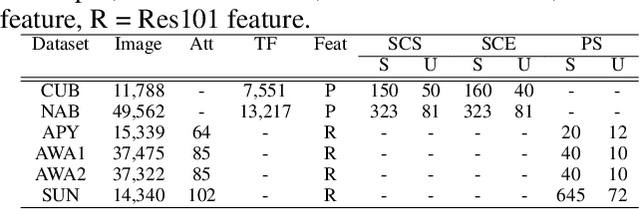
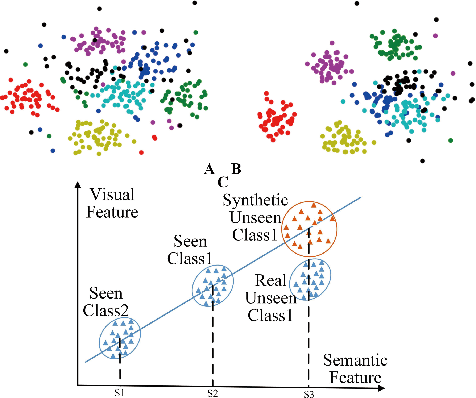

Recently, many zero-shot learning (ZSL) methods focused on learning discriminative object features in an embedding feature space, however, the distributions of the unseen-class features learned by these methods are prone to be partly overlapped, resulting in inaccurate object recognition. Addressing this problem, we propose a novel adversarial network to synthesize compact semantic visual features for ZSL, consisting of a residual generator, a prototype predictor, and a discriminator. The residual generator is to generate the visual feature residual, which is integrated with a visual prototype predicted via the prototype predictor for synthesizing the visual feature. The discriminator is to distinguish the synthetic visual features from the real ones extracted from an existing categorization CNN. Since the generated residuals are generally numerically much smaller than the distances among all the prototypes, the distributions of the unseen-class features synthesized by the proposed network are less overlapped. In addition, considering that the visual features from categorization CNNs are generally inconsistent with their semantic features, a simple feature selection strategy is introduced for extracting more compact semantic visual features. Extensive experimental results on six benchmark datasets demonstrate that our method could achieve a significantly better performance than existing state-of-the-art methods by 1.2-13.2% in most cases.