 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanaReLoc: Camera Relocalization in 3D Planar Primitives via Region-Based Structure Matching
Mar 21, 2026While structure-based relocalizers have long strived for point correspondences when establishing or regressing query-map associations, in this paper, we pioneer the use of planar primitives and 3D planar maps for lightweight 6-DoF camera relocalization in structured environments. Planar primitives, beyond being fundamental entities in projective geometry, also serve as region-based representations that encapsulate both structural and semantic richness. This motivates us to introduce PlanaReLoc, a streamlined plane-centric paradigm where a deep matcher associates planar primitives across the query image and the map within a learned unified embedding space, after which the 6-DoF pose is solved and refined under a robust framework. Through comprehensive experiments on the ScanNet and 12Scenes datasets across hundreds of scenes, our method demonstrates the superiority of planar primitives in facilitating reliable cross-modal structural correspondences and achieving effective camera relocalization without requiring realistically textured/colored maps, pose priors, or per-scene training. The code and data are available at https://github.com/3dv-casia/PlanaReLoc .
Combining LLM Semantic Reasoning with GNN Structural Modeling for Multi-View Multi-Label Feature Selection
Nov 19, 2025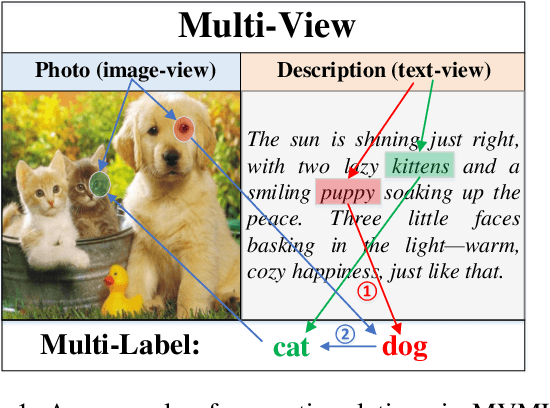



Multi-view multi-label feature selection aims to identify informative features from heterogeneous views, where each sample is associated with multiple interdependent labels. This problem is particularly important in machine learning involving high-dimensional, multimodal data such as social media, bioinformatics or recommendation systems. Existing Multi-View Multi-Label Feature Selection (MVMLFS) methods mainly focus on analyzing statistical information of data, but seldom consider semantic information. In this paper, we aim to use these two types of information jointly and propose a method that combines Large Language Models (LLMs) semantic reasoning with Graph Neural Networks (GNNs) structural modeling for MVMLFS. Specifically, the method consists of three main components. (1) LLM is first used as an evaluation agent to assess the latent semantic relevance among feature, view, and label descriptions. (2) A semantic-aware heterogeneous graph with two levels is designed to represent relations among features, views and labels: one is a semantic graph representing semantic relations, and the other is a statistical graph. (3) A lightweight Graph Attention Network (GAT) is applied to learn node embedding in the heterogeneous graph as feature saliency scores for ranking and selection. Experimental results on multiple benchmark datasets demonstrate the superiority of our method over state-of-the-art baselines, and it is still effective when applied to small-scale datasets, showcasing its robustness, flexibility, and generalization ability.
Redundancy-optimized Multi-head Attention Networks for Multi-View Multi-Label Feature Selection
Nov 16, 2025Multi-view multi-label data offers richer perspectives for artificial intelligence, but simultaneously presents significant challenges for feature selection due to the inherent complexity of interrelations among features, views and labels. Attention mechanisms provide an effective way for analyzing these intricate relationships. They can compute importance weights for information by aggregating correlations between Query and Key matrices to focus on pertinent values. However, existing attention-based feature selection methods predominantly focus on intra-view relationships, neglecting the complementarity of inter-view features and the critical feature-label correlations. Moreover, they often fail to account for feature redundancy, potentially leading to suboptimal feature subsets. To overcome these limitations, we propose a novel method based on Redundancy-optimized Multi-head Attention Networks for Multi-view Multi-label Feature Selection (RMAN-MMFS). Specifically, we employ each individual attention head to model intra-view feature relationships and use the cross-attention mechanisms between different heads to capture inter-view feature complementarity. Furthermore, we design static and dynamic feature redundancy terms: the static term mitigates redundancy within each view, while the dynamic term explicitly models redundancy between unselected and selected features across the entire selection process, thereby promoting feature compactness. Comprehensive evaluations on six real-world datasets, compared against six multi-view multi-label feature selection methods, demonstrate the superior performance of the proposed method.
PolyRoom: Room-aware Transformer for Floorplan Reconstruction
Jul 15, 2024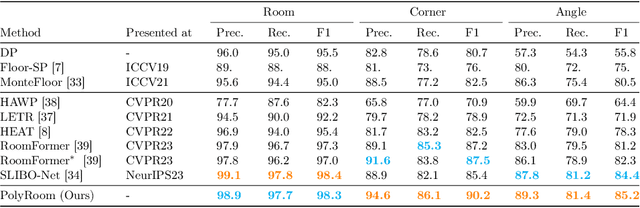
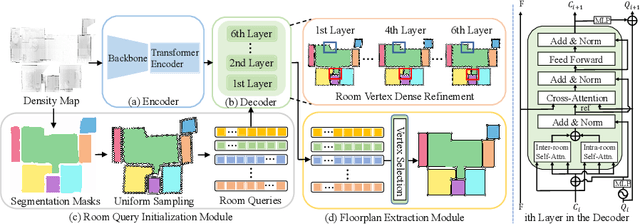
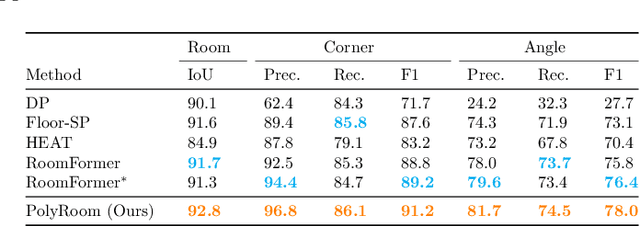

Reconstructing geometry and topology structures from raw unstructured data has always been an important research topic in indoor mapping research. In this paper, we aim to reconstruct the floorplan with a vectorized representation from point clouds. Despite significant advancements achieved in recent years, current methods still encounter several challenges, such as missing corners or edges, inaccuracies in corner positions or angles, self-intersecting or overlapping polygons, and potentially implausible topology. To tackle these challenges, we present PolyRoom, a room-aware Transformer that leverages uniform sampling representation, room-aware query initialization, and room-aware self-attention for floorplan reconstruction. Specifically, we adopt a uniform sampling floorplan representation to enable dense supervision during training and effective utilization of angle information. Additionally, we propose a room-aware query initialization scheme to prevent non-polygonal sequences and introduce room-aware self-attention to enhance memory efficiency and model performance. Experimental results on two widely used datasets demonstrate that PolyRoom surpasses current state-of-the-art methods both quantitatively and qualitatively. Our code is available at: https://github.com/3dv-casia/PolyRoom/.
Autonomous Vehicle Calibration via Linear Optimization
Apr 27, 2022
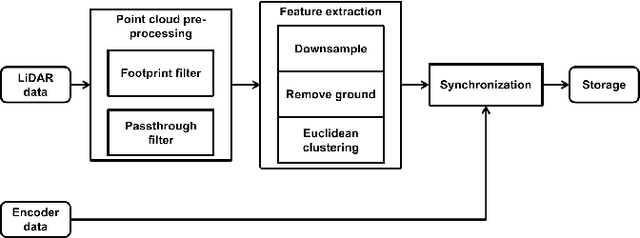
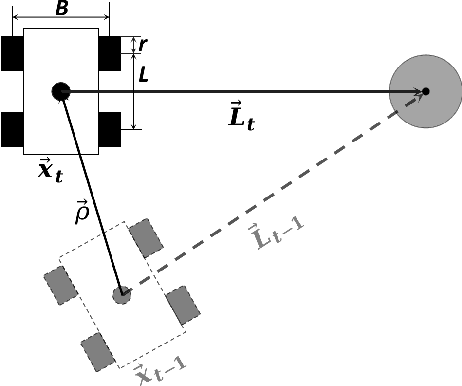
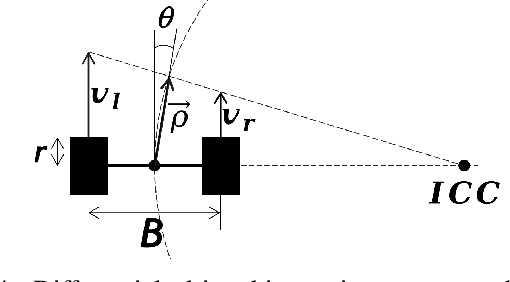
In navigation activities, kinematic parameters of a mobile vehicle play a significant role. Odometry is most commonly used for dead reckoning. However, the unrestricted accumulation of errors is a disadvantage using this method. As a result, it is necessary to calibrate odometry parameters to minimize the error accumulation. This paper presents a pipeline based on sequential least square programming to minimize the relative position displacement of an arbitrary landmark in consecutive time steps of a kinematic vehicle model by calibrating the parameters of applied model. Results showed that the developed pipeline produced accurate results with small datasets.
Mobile Delivery Robots: Mixed Reality-Based Simulation Relying on ROS and Unity 3D
Jun 16, 2020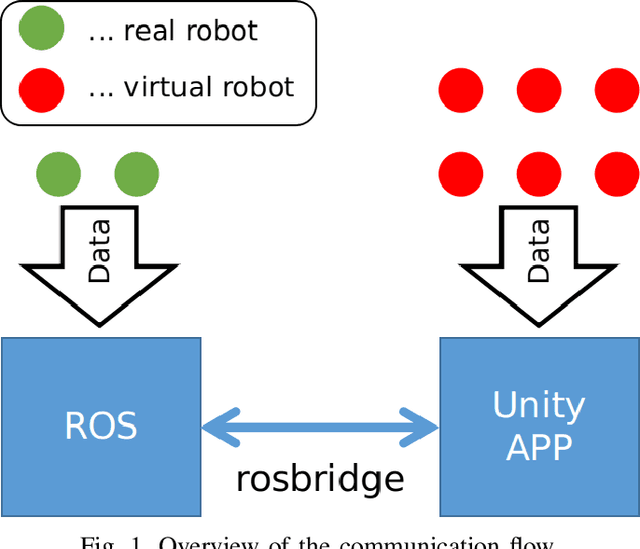


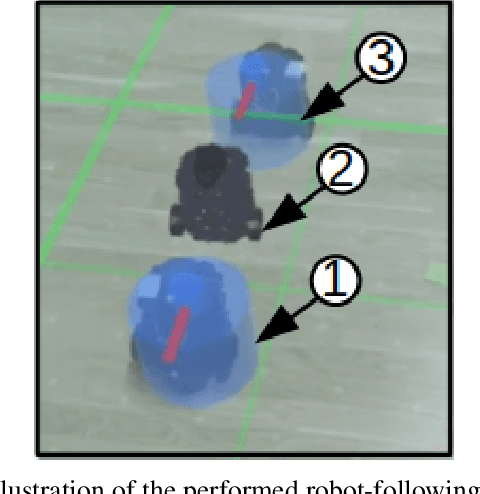
In the context of Intelligent Transportation Systems and the delivery of goods, new technology approaches need to be developed in order to cope with certain challenges that last mile delivery entails, such as navigation in an urban environment. Autonomous delivery robots can help overcome these challenges. We propose a method for performing mixed reality (MR) simulation with ROS-based robots using Unity, which synchronizes the real and virtual environment, and simultaneously uses the sensor information of the real robots to locate themselves and project them into the virtual environment, so that they can use their virtual doppelganger to perceive the virtual world. Using this method, real and virtual robots can perceive each other and the environment in which the other party is located, thereby enabling the exchange of information between virtual and real objects. Through this approach a more realistic and reliable simulation can be obtained. Results of the demonstrated use-cases verified the feasibility and efficiency as well as the stability of implementing MR using Unity for ROS-based robots.
Voice and accompaniment separation in music using self-attention convolutional neural network
Mar 19, 2020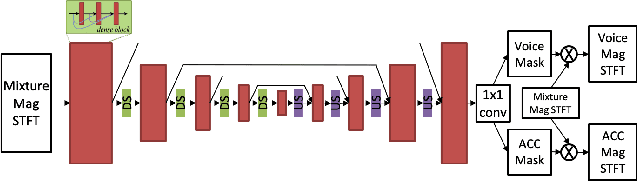
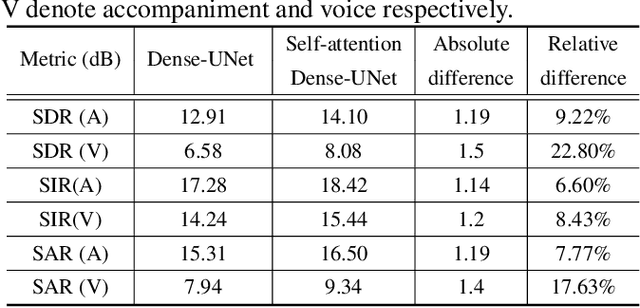
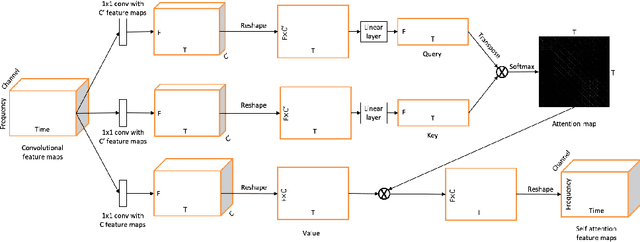
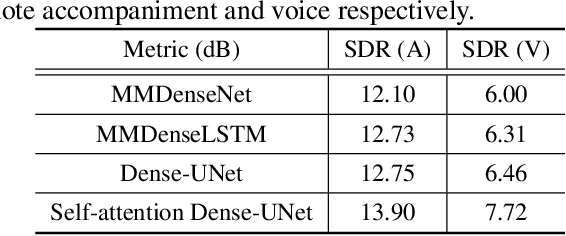
Music source separation has been a popular topic in signal processing for decades, not only because of its technical difficulty, but also due to its importance to many commercial applications, such as automatic karoake and remixing. In this work, we propose a novel self-attention network to separate voice and accompaniment in music. First, a convolutional neural network (CNN) with densely-connected CNN blocks is built as our base network. We then insert self-attention subnets at different levels of the base CNN to make use of the long-term intra-dependency of music, i.e., repetition. Within self-attention subnets, repetitions of the same musical patterns inform reconstruction of other repetitions, for better source separation performance. Results show the proposed method leads to 19.5% relative improvement in vocals separation in terms of SDR. We compare our methods with state-of-the-art systems i.e. MMDenseNet and MMDenseLSTM.
Divide and Conquer: A Deep CASA Approach to Talker-independent Monaural Speaker Separation
Apr 25, 2019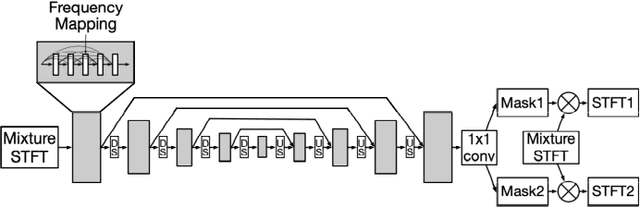
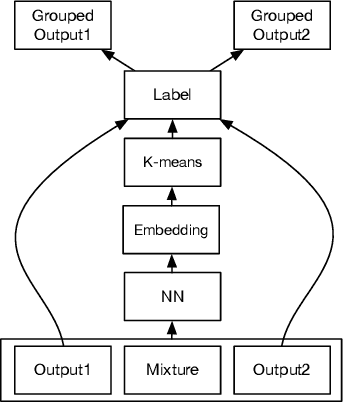
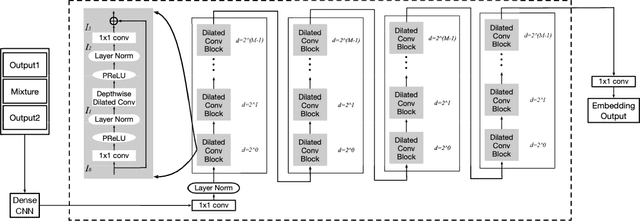
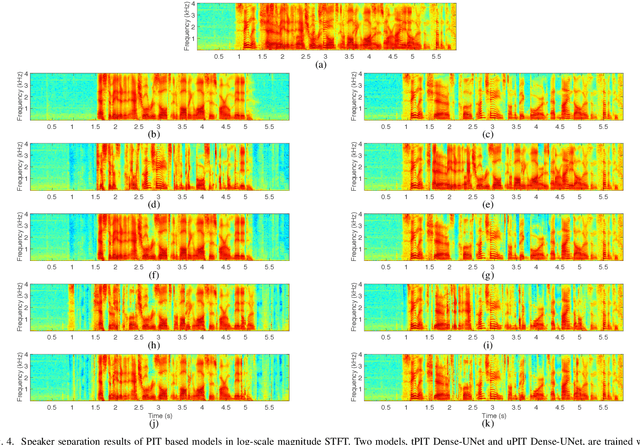
We address talker-independent monaural speaker separation from the perspectives of deep learning and computational auditory scene analysis (CASA). Specifically, we decompose the multi-speaker separation task into the stages of simultaneous grouping and sequential grouping. Simultaneous grouping is first performed in each time frame by separating the spectra of different speakers with a permutation-invariantly trained neural network. In the second stage, the frame-level separated spectra are sequentially grouped to different speakers by a clustering network. The proposed deep CASA approach optimizes frame-level separation and speaker tracking in turn, and produces excellent results for both objectives. Experimental results on the benchmark WSJ0-2mix database show that the new approach achieves the state-of-the-art results with a modest model size.