 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor3R: Streaming 3D Reconstruction with Transient Anchors for Long-Horizon Visual Mapping
Jun 03, 2026Long-horizon online visual mapping is a core capability for robot perception, requiring continuous camera-motion and scene-geometry estimation from visual streams under bounded memory and computation. Recent feed-forward 3D reconstruction models provide strong geometric priors, but their streaming variants often predict poses in a fixed coordinate system tied to the first frame or a persistent scene memory. This fixed-gauge design leads to train--test mismatch, attention bias toward early anchors, and accumulated drift on sequences much longer than those seen during training. We propose \emph{Anchor3R}, a streaming 3D reconstruction framework that treats feed-forward reconstruction as current-centric local measurement prediction rather than persistent global-gauge regression. At each time step, Anchor3R predicts window-relative poses and a local pointmap in the current-frame coordinate system, turning streaming reconstruction into relative-pose measurement generation. These measurements support online pose updates, while loop-closure reinsertion and motion averaging align the trajectory and transform local pointmaps into a coherent global reconstruction. Experiments on indoor, outdoor, driving, and RGB-D benchmarks show that Anchor3R improves long-horizon pose accuracy and dense reconstruction quality over existing streaming baselines, while supporting bounded-memory online inference.
PlanaReLoc: Camera Relocalization in 3D Planar Primitives via Region-Based Structure Matching
Mar 21, 2026While structure-based relocalizers have long strived for point correspondences when establishing or regressing query-map associations, in this paper, we pioneer the use of planar primitives and 3D planar maps for lightweight 6-DoF camera relocalization in structured environments. Planar primitives, beyond being fundamental entities in projective geometry, also serve as region-based representations that encapsulate both structural and semantic richness. This motivates us to introduce PlanaReLoc, a streamlined plane-centric paradigm where a deep matcher associates planar primitives across the query image and the map within a learned unified embedding space, after which the 6-DoF pose is solved and refined under a robust framework. Through comprehensive experiments on the ScanNet and 12Scenes datasets across hundreds of scenes, our method demonstrates the superiority of planar primitives in facilitating reliable cross-modal structural correspondences and achieving effective camera relocalization without requiring realistically textured/colored maps, pose priors, or per-scene training. The code and data are available at https://github.com/3dv-casia/PlanaReLoc .
Fast Converging 3D Gaussian Splatting for 1-Minute Reconstruction
Jan 27, 2026We present a fast 3DGS reconstruction pipeline designed to converge within one minute, developed for the SIGGRAPH Asia 3DGS Fast Reconstruction Challenge. The challenge consists of an initial round using SLAM-generated camera poses (with noisy trajectories) and a final round using COLMAP poses (highly accurate). To robustly handle these heterogeneous settings, we develop a two-stage solution. In the first round, we use reverse per-Gaussian parallel optimization and compact forward splatting based on Taming-GS and Speedy-splat, load-balanced tiling, an anchor-based Neural-Gaussian representation enabling rapid convergence with fewer learnable parameters, initialization from monocular depth and partially from feed-forward 3DGS models, and a global pose refinement module for noisy SLAM trajectories. In the final round, the accurate COLMAP poses change the optimization landscape; we disable pose refinement, revert from Neural-Gaussians back to standard 3DGS to eliminate MLP inference overhead, introduce multi-view consistency-guided Gaussian splitting inspired by Fast-GS, and introduce a depth estimator to supervise the rendered depth. Together, these techniques enable high-fidelity reconstruction under a strict one-minute budget. Our method achieved the top performance with a PSNR of 28.43 and ranked first in the competition.
Decoupled Geometric Parameterization and its Application in Deep Homography Estimation
May 22, 2025



Planar homography, with eight degrees of freedom (DOFs), is fundamental in numerous computer vision tasks. While the positional offsets of four corners are widely adopted (especially in neural network predictions), this parameterization lacks geometric interpretability and typically requires solving a linear system to compute the homography matrix. This paper presents a novel geometric parameterization of homographies, leveraging the similarity-kernel-similarity (SKS) decomposition for projective transformations. Two independent sets of four geometric parameters are decoupled: one for a similarity transformation and the other for the kernel transformation. Additionally, the geometric interpretation linearly relating the four kernel transformation parameters to angular offsets is derived. Our proposed parameterization allows for direct homography estimation through matrix multiplication, eliminating the need for solving a linear system, and achieves performance comparable to the four-corner positional offsets in deep homography estimation.
CoMatcher: Multi-View Collaborative Feature Matching
Apr 02, 2025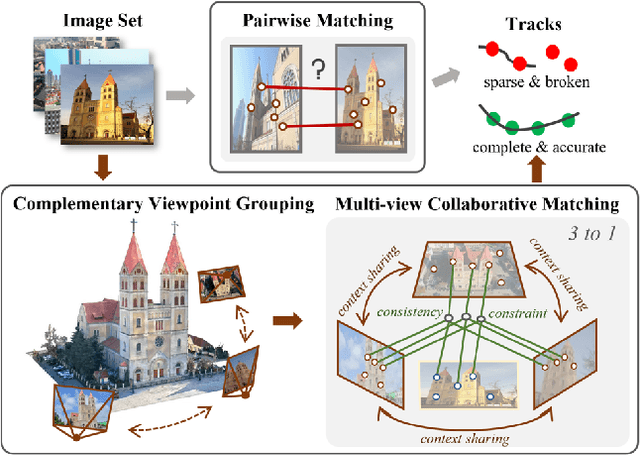
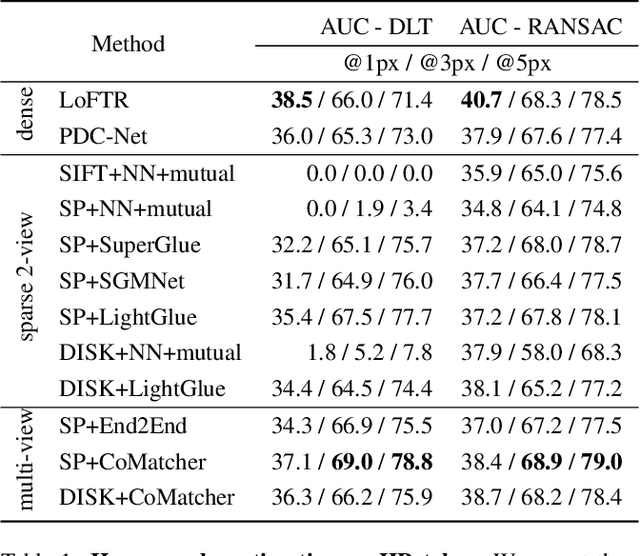
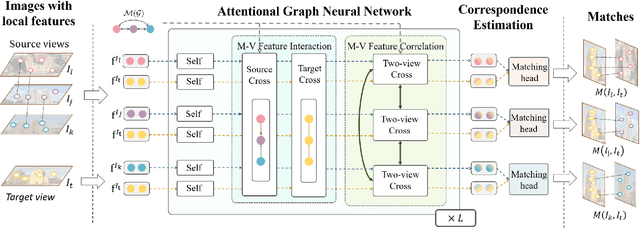
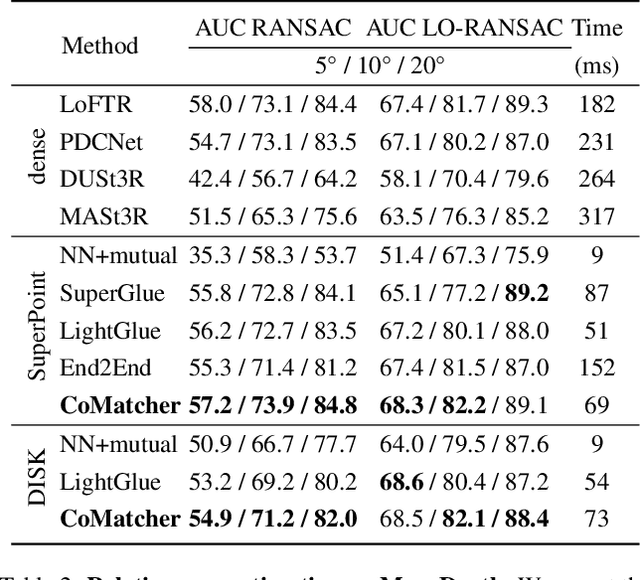
This paper proposes a multi-view collaborative matching strategy for reliable track construction in complex scenarios. We observe that the pairwise matching paradigms applied to image set matching often result in ambiguous estimation when the selected independent pairs exhibit significant occlusions or extreme viewpoint changes. This challenge primarily stems from the inherent uncertainty in interpreting intricate 3D structures based on limited two-view observations, as the 3D-to-2D projection leads to significant information loss. To address this, we introduce CoMatcher, a deep multi-view matcher to (i) leverage complementary context cues from different views to form a holistic 3D scene understanding and (ii) utilize cross-view projection consistency to infer a reliable global solution. Building on CoMatcher, we develop a groupwise framework that fully exploits cross-view relationships for large-scale matching tasks. Extensive experiments on various complex scenarios demonstrate the superiority of our method over the mainstream two-view matching paradigm.
* 15 pages, 7 figures, to be published in CVPR 2025
PolyRoom: Room-aware Transformer for Floorplan Reconstruction
Jul 15, 2024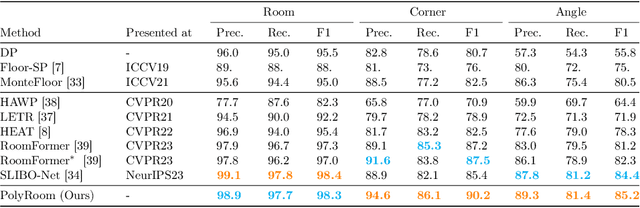
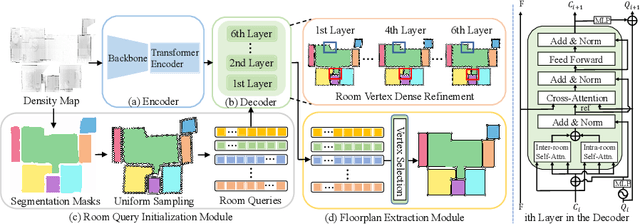
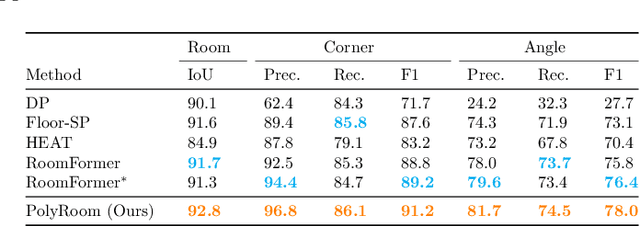

Reconstructing geometry and topology structures from raw unstructured data has always been an important research topic in indoor mapping research. In this paper, we aim to reconstruct the floorplan with a vectorized representation from point clouds. Despite significant advancements achieved in recent years, current methods still encounter several challenges, such as missing corners or edges, inaccuracies in corner positions or angles, self-intersecting or overlapping polygons, and potentially implausible topology. To tackle these challenges, we present PolyRoom, a room-aware Transformer that leverages uniform sampling representation, room-aware query initialization, and room-aware self-attention for floorplan reconstruction. Specifically, we adopt a uniform sampling floorplan representation to enable dense supervision during training and effective utilization of angle information. Additionally, we propose a room-aware query initialization scheme to prevent non-polygonal sequences and introduce room-aware self-attention to enhance memory efficiency and model performance. Experimental results on two widely used datasets demonstrate that PolyRoom surpasses current state-of-the-art methods both quantitatively and qualitatively. Our code is available at: https://github.com/3dv-casia/PolyRoom/.
BEV2PR: BEV-Enhanced Visual Place Recognition with Structural Cues
Mar 11, 2024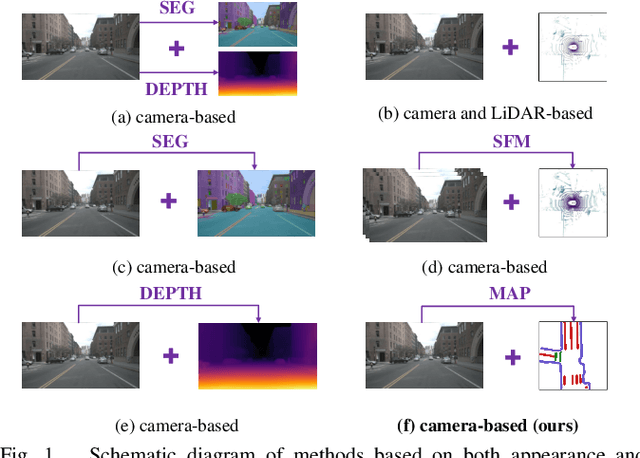
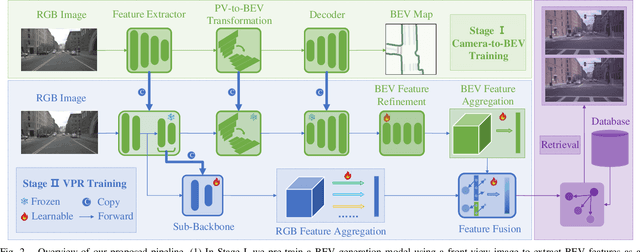

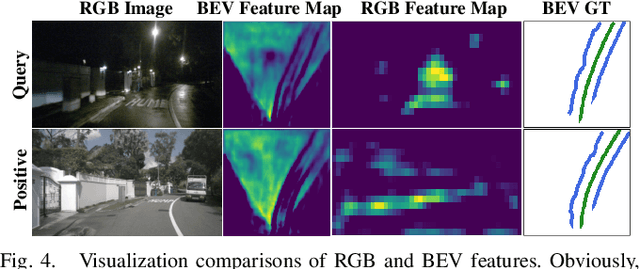
In this paper, we propose a new image-based visual place recognition (VPR) framework by exploiting the structural cues in bird's-eye view (BEV) from a single monocular camera. The motivation arises from two key observations about VPR: 1) For the methods based on both camera and LiDAR sensors, the integration of LiDAR in robotic systems has led to increased expenses, while the alignment of data between different sensors is also a major challenge. 2) Other image-/camera-based methods, involving integrating RGB images and their derived variants (e.g., pseudo depth images, pseudo 3D point clouds), exhibit several limitations, such as the failure to effectively exploit the explicit spatial relationships between different objects. To tackle the above issues, we design a new BEV-enhanced VPR framework, nemely BEV2PR, which can generate a composite descriptor with both visual cues and spatial awareness solely based on a single camera. For the visual cues, any popular aggregation module for RGB global features can be integrated into our framework. The key points lie in: 1) We use BEV segmentation features as an explicit source of structural knowledge in constructing global features. 2) The lower layers of the pre-trained backbone from BEV map generation are shared for visual and structural streams in VPR, facilitating the learning of fine-grained local features in the visual stream. 3) The complementary visual features and structural features can jointly enhance VPR performance. Our BEV2PR framework enables consistent performance improvements over several popular camera-based VPR aggregation modules when integrating them. The experiments on our collected VPR-NuScenes dataset demonstrate an absolute gain of 2.47% on Recall@1 for the strong Conv-AP baseline to achieve the best performance in our setting, and notably, a 18.06% gain on the hard set.
Unsigned Orthogonal Distance Fields: An Accurate Neural Implicit Representation for Diverse 3D Shapes
Mar 03, 2024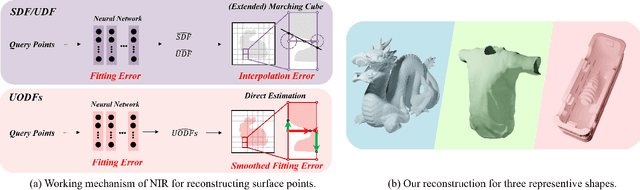
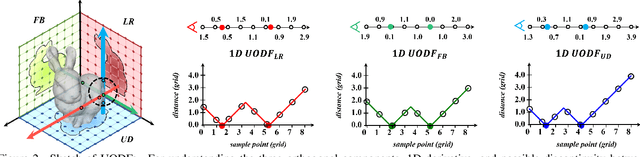

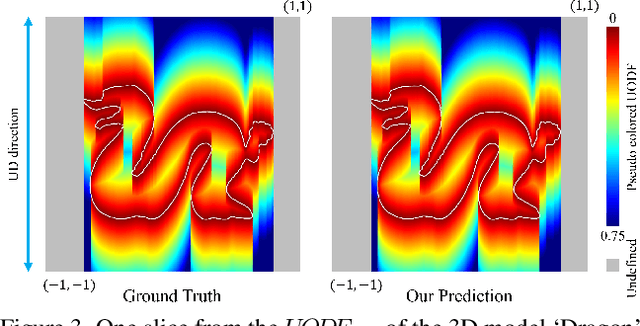
Neural implicit representation of geometric shapes has witnessed considerable advancements in recent years. However, common distance field based implicit representations, specifically signed distance field (SDF) for watertight shapes or unsigned distance field (UDF) for arbitrary shapes, routinely suffer from degradation of reconstruction accuracy when converting to explicit surface points and meshes. In this paper, we introduce a novel neural implicit representation based on unsigned orthogonal distance fields (UODFs). In UODFs, the minimal unsigned distance from any spatial point to the shape surface is defined solely in one orthogonal direction, contrasting with the multi-directional determination made by SDF and UDF. Consequently, every point in the 3D UODFs can directly access its closest surface points along three orthogonal directions. This distinctive feature leverages the accurate reconstruction of surface points without interpolation errors. We verify the effectiveness of UODFs through a range of reconstruction examples, extending from simple watertight or non-watertight shapes to complex shapes that include hollows, internal or assembling structures.
Fast and Interpretable 2D Homography Decomposition: Similarity-Kernel-Similarity and Affine-Core-Affine Transformations
Feb 28, 2024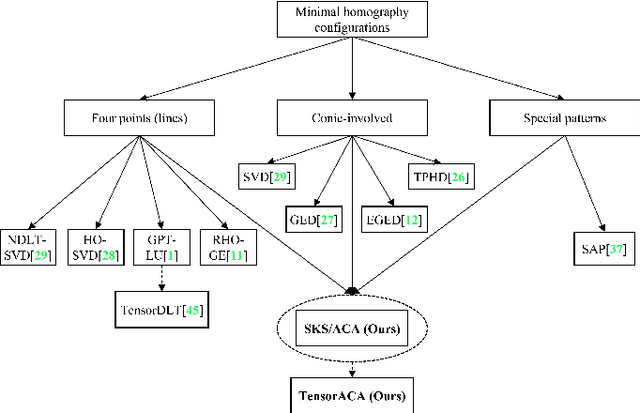

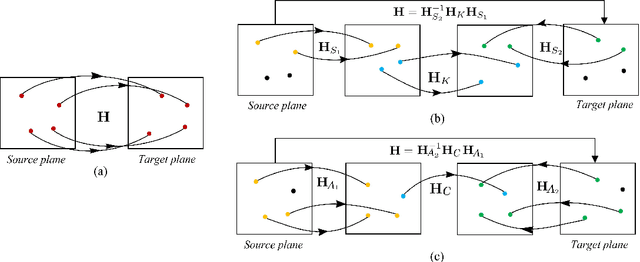
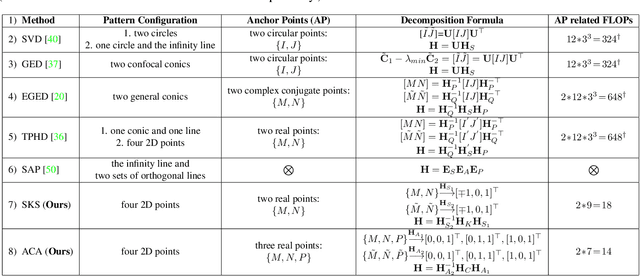
In this paper, we present two fast and interpretable decomposition methods for 2D homography, which are named Similarity-Kernel-Similarity (SKS) and Affine-Core-Affine (ACA) transformations respectively. Under the minimal $4$-point configuration, the first and the last similarity transformations in SKS are computed by two anchor points on target and source planes, respectively. Then, the other two point correspondences can be exploited to compute the middle kernel transformation with only four parameters. Furthermore, ACA uses three anchor points to compute the first and the last affine transformations, followed by computation of the middle core transformation utilizing the other one point correspondence. ACA can compute a homography up to a scale with only $85$ floating-point operations (FLOPs), without even any division operations. Therefore, as a plug-in module, ACA facilitates the traditional feature-based Random Sample Consensus (RANSAC) pipeline, as well as deep homography pipelines estimating $4$-point offsets. In addition to the advantages of geometric parameterization and computational efficiency, SKS and ACA can express each element of homography by a polynomial of input coordinates ($7$th degree to $9$th degree), extend the existing essential Similarity-Affine-Projective (SAP) decomposition and calculate 2D affine transformations in a unified way. Source codes are released in https://github.com/cscvlab/SKS-Homography.
Incremental Rotation Averaging Revisited and More: A New Rotation Averaging Benchmark
Sep 29, 2023In order to further advance the accuracy and robustness of the incremental parameter estimation-based rotation averaging methods, in this paper, a new member of the Incremental Rotation Averaging (IRA) family is introduced, which is termed as IRAv4. As the most significant feature of the IRAv4, a task-specific connected dominating set is extracted to serve as a more reliable and accurate reference for rotation global alignment. In addition, to further address the limitations of the existing rotation averaging benchmark of relying on the slightly outdated Bundler camera calibration results as ground truths and focusing solely on rotation estimation accuracy, this paper presents a new COLMAP-based rotation averaging benchmark that incorporates a cross check between COLMAP and Bundler, and employ the accuracy of both rotation and downstream location estimation as evaluation metrics, which is desired to provide a more reliable and comprehensive evaluation tool for the rotation averaging research. Comprehensive comparisons between the proposed IRAv4 and other mainstream rotation averaging methods on this new benchmark demonstrate the effectiveness of our proposed approach.