 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor3R: Streaming 3D Reconstruction with Transient Anchors for Long-Horizon Visual Mapping
Jun 03, 2026Long-horizon online visual mapping is a core capability for robot perception, requiring continuous camera-motion and scene-geometry estimation from visual streams under bounded memory and computation. Recent feed-forward 3D reconstruction models provide strong geometric priors, but their streaming variants often predict poses in a fixed coordinate system tied to the first frame or a persistent scene memory. This fixed-gauge design leads to train--test mismatch, attention bias toward early anchors, and accumulated drift on sequences much longer than those seen during training. We propose \emph{Anchor3R}, a streaming 3D reconstruction framework that treats feed-forward reconstruction as current-centric local measurement prediction rather than persistent global-gauge regression. At each time step, Anchor3R predicts window-relative poses and a local pointmap in the current-frame coordinate system, turning streaming reconstruction into relative-pose measurement generation. These measurements support online pose updates, while loop-closure reinsertion and motion averaging align the trajectory and transform local pointmaps into a coherent global reconstruction. Experiments on indoor, outdoor, driving, and RGB-D benchmarks show that Anchor3R improves long-horizon pose accuracy and dense reconstruction quality over existing streaming baselines, while supporting bounded-memory online inference.
Incremental Rotation Averaging Revisited and More: A New Rotation Averaging Benchmark
Sep 29, 2023In order to further advance the accuracy and robustness of the incremental parameter estimation-based rotation averaging methods, in this paper, a new member of the Incremental Rotation Averaging (IRA) family is introduced, which is termed as IRAv4. As the most significant feature of the IRAv4, a task-specific connected dominating set is extracted to serve as a more reliable and accurate reference for rotation global alignment. In addition, to further address the limitations of the existing rotation averaging benchmark of relying on the slightly outdated Bundler camera calibration results as ground truths and focusing solely on rotation estimation accuracy, this paper presents a new COLMAP-based rotation averaging benchmark that incorporates a cross check between COLMAP and Bundler, and employ the accuracy of both rotation and downstream location estimation as evaluation metrics, which is desired to provide a more reliable and comprehensive evaluation tool for the rotation averaging research. Comprehensive comparisons between the proposed IRAv4 and other mainstream rotation averaging methods on this new benchmark demonstrate the effectiveness of our proposed approach.
Dense Semantic 3D Map Based Long-Term Visual Localization with Hybrid Features
May 21, 2020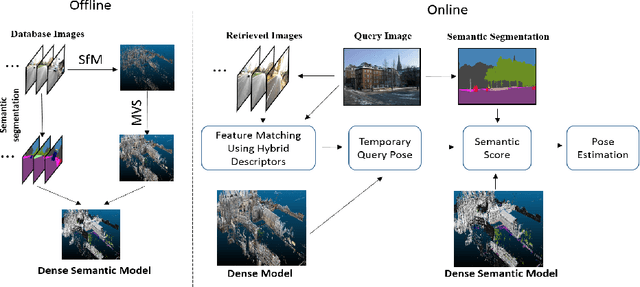
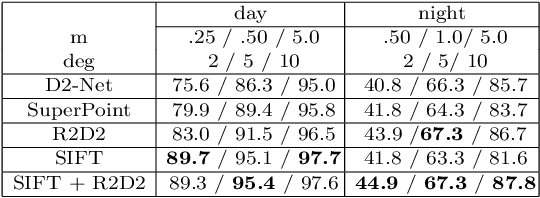

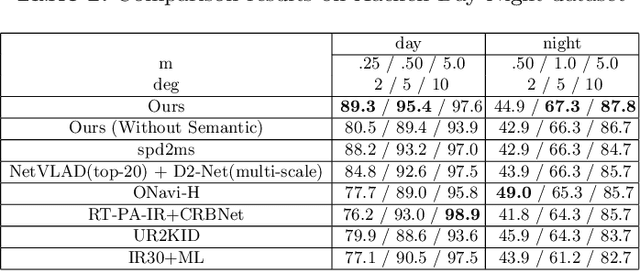
Visual localization plays an important role in many applications. However, due to the large appearance variations such as season and illumination changes, as well as weather and day-night variations, it's still a big challenge for robust long-term visual localization algorithms. In this paper, we present a novel visual localization method using hybrid handcrafted and learned features with dense semantic 3D map. Hybrid features help us to make full use of their strengths in different imaging conditions, and the dense semantic map provide us reliable and complete geometric and semantic information for constructing sufficient 2D-3D matching pairs with semantic consistency scores. In our pipeline, we retrieve and score each candidate database image through the semantic consistency between the dense model and the query image. Then the semantic consistency score is used as a soft constraint in the weighted RANSAC-based PnP pose solver. Experimental results on long-term visual localization benchmarks demonstrate the effectiveness of our method compared with state-of-the-arts.
CSfM: Community-based Structure from Motion
Mar 23, 2018


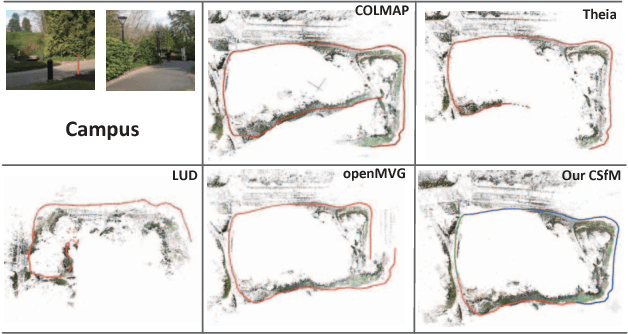
Structure-from-Motion approaches could be broadly divided into two classes: incremental and global. While incremental manner is robust to outliers, it suffers from error accumulation and heavy computation load. The global manner has the advantage of simultaneously estimating all camera poses, but it is usually sensitive to epipolar geometry outliers. In this paper, we propose an adaptive community-based SfM (CSfM) method which takes both robustness and efficiency into consideration. First, the epipolar geometry graph is partitioned into separate communities. Then, the reconstruction problem is solved for each community in parallel. Finally, the reconstruction results are merged by a novel global similarity averaging method, which solves three convex $L1$ optimization problems. Experimental results show that our method performs better than many of the state-of-the-art global SfM approaches in terms of computational efficiency, while achieves similar or better reconstruction accuracy and robustness than many of the state-of-the-art incremental SfM approaches.
* Our paper has been published in ICIP2017
InAR:Inverse Augmented Reality
Aug 11, 2015Augmented reality is the art to seamlessly fuse virtual objects into real ones. In this short note, we address the opposite problem, the inverse augmented reality, that is, given a perfectly augmented reality scene where human is unable to distinguish real objects from virtual ones, how the machine could help do the job. We show by structure from motion (SFM), a simple 3D reconstruction technique from images in computer vision, the real and virtual objects can be easily separated in the reconstructed 3D scene.